 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentAda: Skill-Adaptive Data Analytics for Tailored Insight Discovery
Apr 10, 2025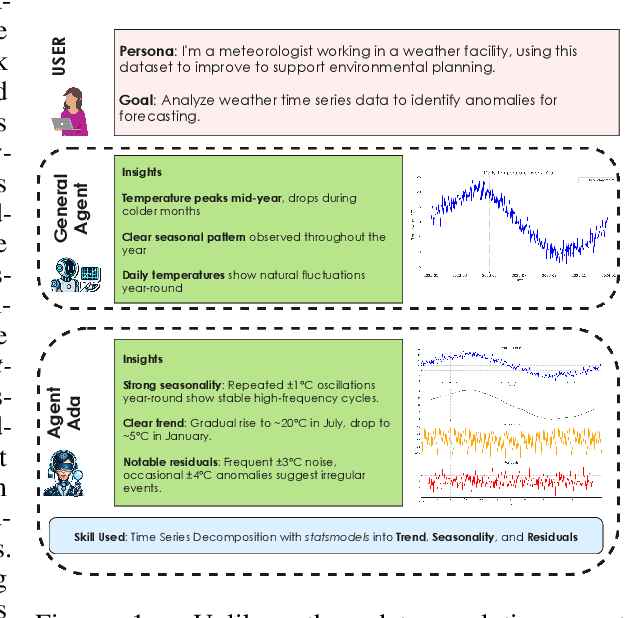

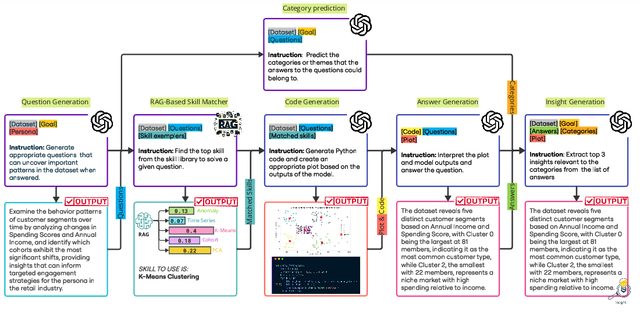
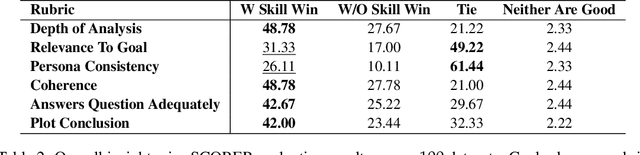
We introduce AgentAda, the first LLM-powered analytics agent that can learn and use new analytics skills to extract more specialized insights. Unlike existing methods that require users to manually decide which data analytics method to apply, AgentAda automatically identifies the skill needed from a library of analytical skills to perform the analysis. This also allows AgentAda to use skills that existing LLMs cannot perform out of the box. The library covers a range of methods, including clustering, predictive modeling, and NLP techniques like BERT, which allow AgentAda to handle complex analytics tasks based on what the user needs. AgentAda's dataset-to-insight extraction strategy consists of three key steps: (I) a question generator to generate queries relevant to the user's goal and persona, (II) a hybrid Retrieval-Augmented Generation (RAG)-based skill matcher to choose the best data analytics skill from the skill library, and (III) a code generator that produces executable code based on the retrieved skill's documentation to extract key patterns. We also introduce KaggleBench, a benchmark of curated notebooks across diverse domains, to evaluate AgentAda's performance. We conducted a human evaluation demonstrating that AgentAda provides more insightful analytics than existing tools, with 48.78% of evaluators preferring its analyses, compared to 27.67% for the unskilled agent. We also propose a novel LLM-as-a-judge approach that we show is aligned with human evaluation as a way to automate insight quality evaluation at larger scale.
Tiny-HR: Towards an interpretable machine learning pipeline for heart rate estimation on edge devices
Aug 16, 2022



The focus of this paper is a proof of concept, machine learning (ML) pipeline that extracts heart rate from pressure sensor data acquired on low-power edge devices. The ML pipeline consists an upsampler neural network, a signal quality classifier, and a 1D-convolutional neural network optimized for efficient and accurate heart rate estimation. The models were designed so the pipeline was less than 40 kB. Further, a hybrid pipeline consisting of the upsampler and classifier, followed by a peak detection algorithm was developed. The pipelines were deployed on ESP32 edge device and benchmarked against signal processing to determine the energy usage, and inference times. The results indicate that the proposed ML and hybrid pipeline reduces energy and time per inference by 82% and 28% compared to traditional algorithms. The main trade-off for ML pipeline was accuracy, with a mean absolute error (MAE) of 3.28, compared to 2.39 and 1.17 for the hybrid and signal processing pipelines. The ML models thus show promise for deployment in energy and computationally constrained devices. Further, the lower sampling rate and computational requirements for the ML pipeline could enable custom hardware solutions to reduce the cost and energy needs of wearable devices.