 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Literature Search Evaluation: Deep Research Helps, and Human Citation Lists Are Not a Ground Truth
May 28, 2026We study large-scale literature search from two complementary angles: improving the retrieval pipeline, and stress-testing the human reference list as an evaluation target. First, we implement a Deep Research pipeline that processes the full query paper and expands the retrieved results breadth-first along their bibliographies, and show that it substantially outperforms vanilla API-only search, raising recall on RollingEval-Jun25 (a 250-paper literature-search benchmark) from below 20% to above 80%. Second, we use a neutral LLM-as-a-judge to determine if human references are sound ground truth for the task. We find significant limitations: only 51% of human citations are judged moderately relevant or higher, against 86--88% for the strongest AI-based re-rankers. We study this gap on the OpenAlex co-authorship graph, finding that humans are 2.5x more likely than the best AI re-rankers to cite a direct collaborator. Together, our results argue against single-axis literature-search evaluation: recall, topical-relevance scoring, ranked-list diversity, and a co-authorship-distance diagnostic each measure complementary properties of citation quality and should be reported jointly.
Mem-$π$: Adaptive Memory through Learning When and What to Generate
May 20, 2026We present Mem-$π$, a framework for adaptive memory in large language model (LLM) agents, where useful guidance is generated on demand rather than retrieved from external memory stores. Existing memory-augmented agents typically rely on similarity-based retrieval from episodic memory banks or skill libraries, returning static entries that often misalign with the current context. In contrast, Mem-$π$ uses a dedicated language or vision-language model with its own parameters, separate from the downstream agent, to generate context-specific guidance for complex tasks. Conditioned on the current agent context, the model jointly decides when to produce guidance and what guidance to produce. We train it with a decision-content decoupled reinforcement learning (RL) objective, enabling it to abstain when generation would not help and otherwise produce concise, useful guidance. Across diverse agentic benchmarks spanning web navigation, terminal-based tool use, and text-based embodied interaction, Mem-$π$ consistently outperforms retrieval-based and prior RL-optimized memory baselines, achieving over 30% relative improvement on web navigation tasks.
Generative Floor Plan Design with LLMs via Reinforcement Learning with Verifiable Rewards
May 13, 2026An AI system for professional floor plan design must precisely control room dimensions and areas while respecting the desired connectivity between rooms and maintaining functional and aesthetic quality. Existing generative approaches focus primarily on respecting the requested connectivity between rooms, but do not support generating floor plans that respect numerical constraints. We introduce a text-based floor plan generation approach that fine-tunes a large language model (LLM) on real plans and then applies reinforcement learning with verifiable rewards (RLVR) to improve adherence to topological and numerical constraints while discouraging invalid or overlapping outputs. Furthermore, we design a set of constraint adherence metrics to systematically measure how generated floor plans align with user-defined constraints. Our model generates floor plans that satisfy user-defined connectivity and numerical constraints and outperforms existing methods on Realism, Compatibility, and Diversity metrics. Across all tasks, our approach achieves at least a 94% relative reduction in Compatibility compared with existing methods. Our results demonstrate that LLMs can effectively handle constraints in this setting, suggesting broader applications for text-based generative modeling.
Do Enterprise Systems Need Learned World Models? The Importance of Context to Infer Dynamics
May 12, 2026World models enable agents to anticipate the effects of their actions by internalizing environment dynamics. In enterprise systems, however, these dynamics are often defined by tenant-specific business logic that varies across deployments and evolves over time, making models trained on historical transitions brittle under deployment shift. We ask a question the world-models literature has not addressed: when the rules can be read at inference time, does an agent still need to learn them? We argue, and demonstrate empirically, that in settings where transition dynamics are configurable and readable, runtime discovery complements offline training by grounding predictions in the active system instance. We propose enterprise discovery agents, which recover relevant transition dynamics at runtime by reading the system's configuration rather than relying solely on internalized representations. We introduce CascadeBench, a reasoning-focused benchmark for enterprise cascade prediction that adopts the evaluation methodology of World of Workflows on diverse synthetic environments, and use it together with deployment-shift evaluation to show that offline-trained world models can perform well in-distribution but degrade as dynamics change, whereas discovery-based agents are more robust under shift by grounding their predictions in the current instance. Our findings suggest that, in configurable enterprise environments, agents should not rely solely on fixed internalized dynamics, but should incorporate mechanisms for discovering relevant transition logic at runtime.
MOOZY: A Patient-First Foundation Model for Computational Pathology
Mar 31, 2026Computational pathology needs whole-slide image (WSI) foundation models that transfer across diverse clinical tasks, yet current approaches remain largely slide-centric, often depend on private data and expensive paired-report supervision, and do not explicitly model relationships among multiple slides from the same patient. We present MOOZY, a patient-first pathology foundation model in which the patient case, not the individual slide, is the core unit of representation. MOOZY explicitly models dependencies across all slides from the same patient via a case transformer during pretraining, combining multi-stage open self-supervision with scaled low-cost task supervision. In Stage 1, we pretrain a vision-only slide encoder on 77,134 public slide feature grids using masked self-distillation. In Stage 2, we align these representations with clinical semantics using a case transformer and multi-task supervision over 333 tasks from 56 public datasets, including 205 classification and 128 survival tasks across four endpoints. Across eight held-out tasks with five-fold frozen-feature probe evaluation, MOOZY achieves best or tied-best performance on most metrics and improves macro averages over TITAN by +7.37%, +5.50%, and +7.83% and over PRISM by +8.83%, +10.70%, and +9.78% for weighted F1, weighted ROC-AUC, and balanced accuracy, respectively. MOOZY is also parameter efficient with 85.77M parameters, 14x smaller than GigaPath. These results demonstrate that open, reproducible patient-level pretraining yields transferable embeddings, providing a practical path toward scalable patient-first histopathology foundation models.
Constrained Group Relative Policy Optimization
Feb 05, 2026While Group Relative Policy Optimization (GRPO) has emerged as a scalable framework for critic-free policy learning, extending it to settings with explicit behavioral constraints remains underexplored. We introduce Constrained GRPO, a Lagrangian-based extension of GRPO for constrained policy optimization. Constraints are specified via indicator cost functions, enabling direct optimization of violation rates through a Lagrangian relaxation. We show that a naive multi-component treatment in advantage estimation can break constrained learning: mismatched component-wise standard deviations distort the relative importance of the different objective terms, which in turn corrupts the Lagrangian signal and prevents meaningful constraint enforcement. We formally derive this effect to motivate our scalarized advantage construction that preserves the intended trade-off between reward and constraint terms. Experiments in a toy gridworld confirm the predicted optimization pathology and demonstrate that scalarizing advantages restores stable constraint control. In addition, we evaluate Constrained GRPO on robotics tasks, where it improves constraint satisfaction while increasing task success, establishing a simple and effective recipe for constrained policy optimization in embodied AI domains that increasingly rely on large multimodal foundation models.
Diffusion Large Language Models for Black-Box Optimization
Jan 20, 2026Offline black-box optimization (BBO) aims to find optimal designs based solely on an offline dataset of designs and their labels. Such scenarios frequently arise in domains like DNA sequence design and robotics, where only a few labeled data points are available. Traditional methods typically rely on task-specific proxy or generative models, overlooking the in-context learning capabilities of pre-trained large language models (LLMs). Recent efforts have adapted autoregressive LLMs to BBO by framing task descriptions and offline datasets as natural language prompts, enabling direct design generation. However, these designs often contain bidirectional dependencies, which left-to-right models struggle to capture. In this paper, we explore diffusion LLMs for BBO, leveraging their bidirectional modeling and iterative refinement capabilities. This motivates our in-context denoising module: we condition the diffusion LLM on the task description and the offline dataset, both formatted in natural language, and prompt it to denoise masked designs into improved candidates. To guide the generation toward high-performing designs, we introduce masked diffusion tree search, which casts the denoising process as a step-wise Monte Carlo Tree Search that dynamically balances exploration and exploitation. Each node represents a partially masked design, each denoising step is an action, and candidates are evaluated via expected improvement under a Gaussian Process trained on the offline dataset. Our method, dLLM, achieves state-of-the-art results in few-shot settings on design-bench.
Grounding Computer Use Agents on Human Demonstrations
Nov 10, 2025



Building reliable computer-use agents requires grounding: accurately connecting natural language instructions to the correct on-screen elements. While large datasets exist for web and mobile interactions, high-quality resources for desktop environments are limited. To address this gap, we introduce GroundCUA, a large-scale desktop grounding dataset built from expert human demonstrations. It covers 87 applications across 12 categories and includes 56K screenshots, with every on-screen element carefully annotated for a total of over 3.56M human-verified annotations. From these demonstrations, we generate diverse instructions that capture a wide range of real-world tasks, providing high-quality data for model training. Using GroundCUA, we develop the GroundNext family of models that map instructions to their target UI elements. At both 3B and 7B scales, GroundNext achieves state-of-the-art results across five benchmarks using supervised fine-tuning, while requiring less than one-tenth the training data of prior work. Reinforcement learning post-training further improves performance, and when evaluated in an agentic setting on the OSWorld benchmark using o3 as planner, GroundNext attains comparable or superior results to models trained with substantially more data,. These results demonstrate the critical role of high-quality, expert-driven datasets in advancing general-purpose computer-use agents.
Poutine: Vision-Language-Trajectory Pre-Training and Reinforcement Learning Post-Training Enable Robust End-to-End Autonomous Driving
Jun 12, 2025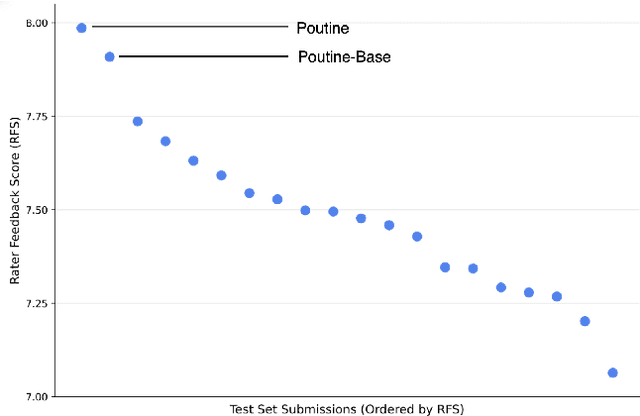



We present Poutine, a 3B-parameter vision-language model (VLM) tailored for end-to-end autonomous driving in long-tail driving scenarios. Poutine is trained in two stages. To obtain strong base driving capabilities, we train Poutine-Base in a self-supervised vision-language-trajectory (VLT) next-token prediction fashion on 83 hours of CoVLA nominal driving and 11 hours of Waymo long-tail driving. Accompanying language annotations are auto-generated with a 72B-parameter VLM. Poutine is obtained by fine-tuning Poutine-Base with Group Relative Policy Optimization (GRPO) using less than 500 preference-labeled frames from the Waymo validation set. We show that both VLT pretraining and RL fine-tuning are critical to attain strong driving performance in the long-tail. Poutine-Base achieves a rater-feedback score (RFS) of 8.12 on the validation set, nearly matching Waymo's expert ground-truth RFS. The final Poutine model achieves an RFS of 7.99 on the official Waymo test set, placing 1st in the 2025 Waymo Vision-Based End-to-End Driving Challenge by a significant margin. These results highlight the promise of scalable VLT pre-training and lightweight RL fine-tuning to enable robust and generalizable autonomy.
Rendering-Aware Reinforcement Learning for Vector Graphics Generation
May 27, 2025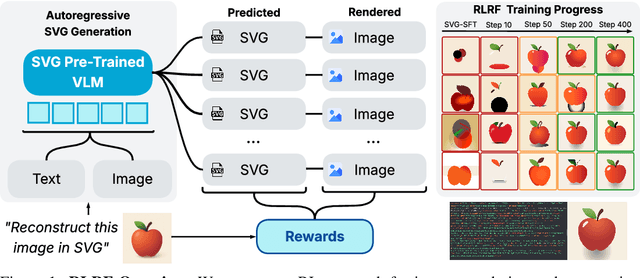
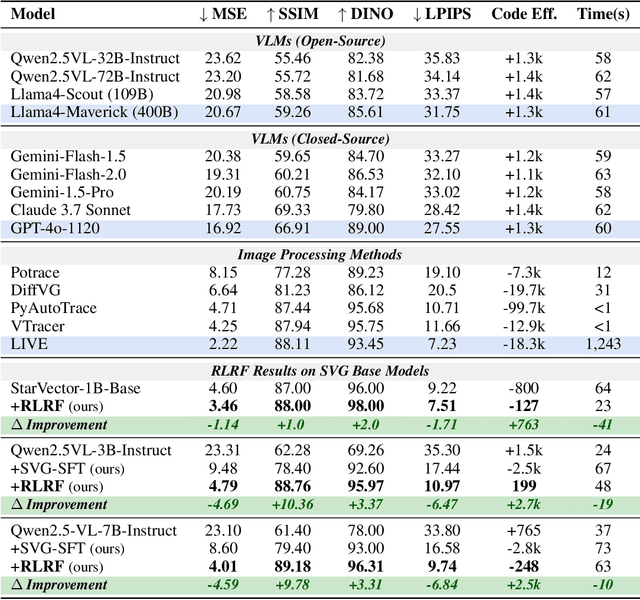
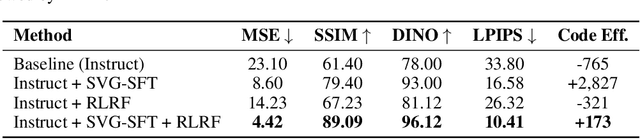
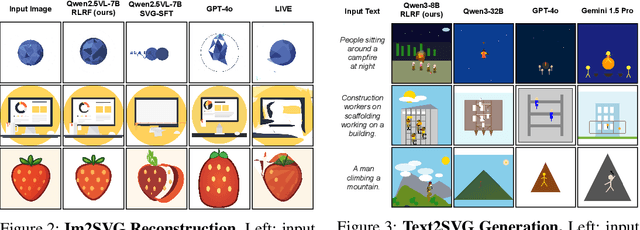
Scalable Vector Graphics (SVG) offer a powerful format for representing visual designs as interpretable code. Recent advances in vision-language models (VLMs) have enabled high-quality SVG generation by framing the problem as a code generation task and leveraging large-scale pretraining. VLMs are particularly suitable for this task as they capture both global semantics and fine-grained visual patterns, while transferring knowledge across vision, natural language, and code domains. However, existing VLM approaches often struggle to produce faithful and efficient SVGs because they never observe the rendered images during training. Although differentiable rendering for autoregressive SVG code generation remains unavailable, rendered outputs can still be compared to original inputs, enabling evaluative feedback suitable for reinforcement learning (RL). We introduce RLRF(Reinforcement Learning from Rendering Feedback), an RL method that enhances SVG generation in autoregressive VLMs by leveraging feedback from rendered SVG outputs. Given an input image, the model generates SVG roll-outs that are rendered and compared to the original image to compute a reward. This visual fidelity feedback guides the model toward producing more accurate, efficient, and semantically coherent SVGs. RLRF significantly outperforms supervised fine-tuning, addressing common failure modes and enabling precise, high-quality SVG generation with strong structural understanding and generalization.