 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScenario Dreamer: Vectorized Latent Diffusion for Generating Driving Simulation Environments
Mar 28, 2025



We introduce Scenario Dreamer, a fully data-driven generative simulator for autonomous vehicle planning that generates both the initial traffic scene - comprising a lane graph and agent bounding boxes - and closed-loop agent behaviours. Existing methods for generating driving simulation environments encode the initial traffic scene as a rasterized image and, as such, require parameter-heavy networks that perform unnecessary computation due to many empty pixels in the rasterized scene. Moreover, we find that existing methods that employ rule-based agent behaviours lack diversity and realism. Scenario Dreamer instead employs a novel vectorized latent diffusion model for initial scene generation that directly operates on the vectorized scene elements and an autoregressive Transformer for data-driven agent behaviour simulation. Scenario Dreamer additionally supports scene extrapolation via diffusion inpainting, enabling the generation of unbounded simulation environments. Extensive experiments show that Scenario Dreamer outperforms existing generative simulators in realism and efficiency: the vectorized scene-generation base model achieves superior generation quality with around 2x fewer parameters, 6x lower generation latency, and 10x fewer GPU training hours compared to the strongest baseline. We confirm its practical utility by showing that reinforcement learning planning agents are more challenged in Scenario Dreamer environments than traditional non-generative simulation environments, especially on long and adversarial driving environments.
Ctrl-V: Higher Fidelity Video Generation with Bounding-Box Controlled Object Motion
Jun 09, 2024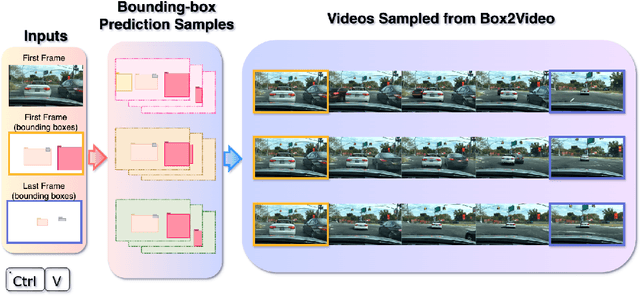
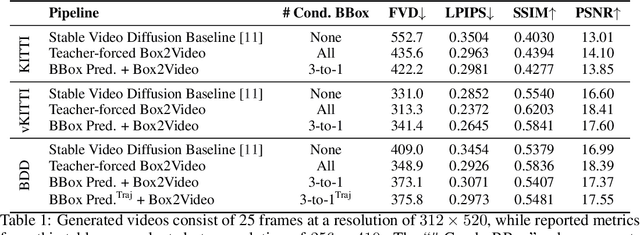


With recent advances in video prediction, controllable video generation has been attracting more attention. Generating high fidelity videos according to simple and flexible conditioning is of particular interest. To this end, we propose a controllable video generation model using pixel level renderings of 2D or 3D bounding boxes as conditioning. In addition, we also create a bounding box predictor that, given the initial and ending frames' bounding boxes, can predict up to 15 bounding boxes per frame for all the frames in a 25-frame clip. We perform experiments across 3 well-known AV video datasets: KITTI, Virtual-KITTI 2 and BDD100k.
CtRL-Sim: Reactive and Controllable Driving Agents with Offline Reinforcement Learning
Mar 29, 2024



Evaluating autonomous vehicle stacks (AVs) in simulation typically involves replaying driving logs from real-world recorded traffic. However, agents replayed from offline data do not react to the actions of the AV, and their behaviour cannot be easily controlled to simulate counterfactual scenarios. Existing approaches have attempted to address these shortcomings by proposing methods that rely on heuristics or learned generative models of real-world data but these approaches either lack realism or necessitate costly iterative sampling procedures to control the generated behaviours. In this work, we take an alternative approach and propose CtRL-Sim, a method that leverages return-conditioned offline reinforcement learning within a physics-enhanced Nocturne simulator to efficiently generate reactive and controllable traffic agents. Specifically, we process real-world driving data through the Nocturne simulator to generate a diverse offline reinforcement learning dataset, annotated with various reward terms. With this dataset, we train a return-conditioned multi-agent behaviour model that allows for fine-grained manipulation of agent behaviours by modifying the desired returns for the various reward components. This capability enables the generation of a wide range of driving behaviours beyond the scope of the initial dataset, including those representing adversarial behaviours. We demonstrate that CtRL-Sim can efficiently generate diverse and realistic safety-critical scenarios while providing fine-grained control over agent behaviours. Further, we show that fine-tuning our model on simulated safety-critical scenarios generated by our model enhances this controllability.
Real-time Audio Video Enhancement \\with a Microphone Array and Headphones
Mar 02, 2023



This paper presents a complete hardware and software pipeline for real-time speech enhancement in noisy and reverberant conditions. The device consists of a microphone array and a camera mounted on eyeglasses, connected to an embedded system that enhances speech and plays back the audio in headphones, with a latency of maximum 120 msec. The proposed approach relies on face detection, tracking and verification to enhance the speech of a target speaker using a beamformer and a postfiltering neural network. Results demonstrate the feasibility of the approach, and opens the door to the exploration and validation of a wide range of beamformer and speech enhancement methods for real-time speech enhancement.