 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAcoustic Drone Package Delivery Detection
Feb 10, 2026In recent years, the illicit use of unmanned aerial vehicles (UAVs) for deliveries in restricted area such as prisons became a significant security challenge. While numerous studies have focused on UAV detection or localization, little attention has been given to delivery events identification. This study presents the first acoustic package delivery detection algorithm using a ground-based microphone array. The proposed method estimates both the drone's propeller speed and the delivery event using solely acoustic features. A deep neural network detects the presence of a drone and estimates the propeller's rotation speed or blade passing frequency (BPF) from a mel spectrogram. The algorithm analyzes the BPFs to identify probable delivery moments based on sudden changes before and after a specific time. Results demonstrate a mean absolute error of the blade passing frequency estimator of 16 Hz when the drone is less than 150 meters away from the microphone array. The drone presence detection estimator has a accuracy of 97%. The delivery detection algorithm correctly identifies 96% of events with a false positive rate of 8%. This study shows that deliveries can be identified using acoustic signals up to a range of 100 meters.
Unsupervised Improved MVDR Beamforming for Sound Enhancement
Jun 12, 2024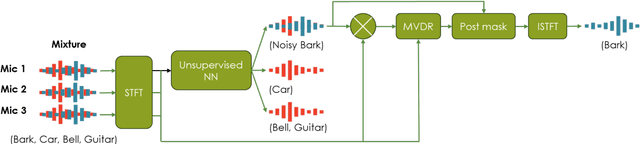
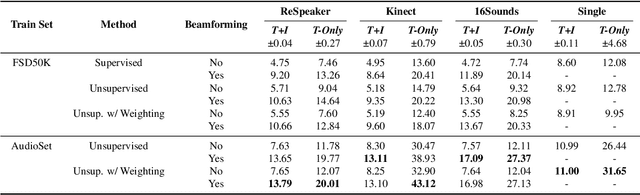
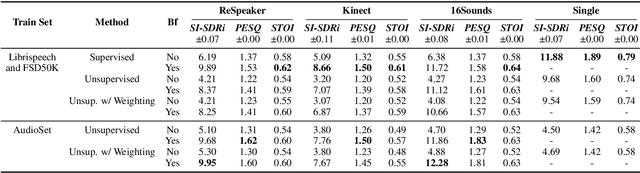
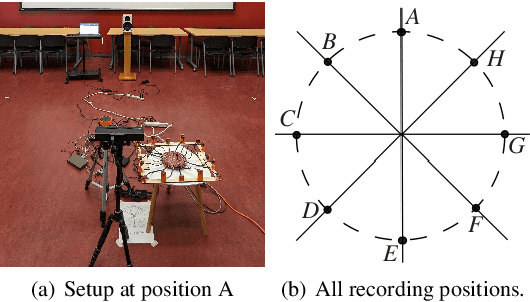
Neural networks have recently become the dominant approach to sound separation. Their good performance relies on large datasets of isolated recordings. For speech and music, isolated single channel data are readily available; however the same does not hold in the multi-channel case, and with most other sound classes. Multi-channel methods have the potential to outperform single channel approaches as they can exploit both spatial and spectral features, but the lack of training data remains a challenge. We propose unsupervised improved minimum variation distortionless response (UIMVDR), which enables multi-channel separation to leverage in-the-wild single-channel data through unsupervised training and beamforming. Results show that UIMVDR generalizes well and improves separation performance compared to supervised models, particularly in cases with limited supervised data. By using data available online, it also reduces the effort required to gather data for multi-channel approaches.
Efficient Face Detection with Audio-Based Region Proposals
Sep 14, 2023Robot vision often involves a large computational load due to large images to process in a short amount of time. Existing solutions often involve reducing image quality which can negatively impact processing. Another approach is to generate regions of interest with expensive vision algorithms. In this paper, we evaluate how audio can be used to generate regions of interest in optical images. To achieve this, we propose a unique attention mechanism to localize speech sources and evaluate its impact on a face detection algorithm. Our results show that the attention mechanism reduces the computational load. The proposed pipeline is flexible and can be easily adapted for human-robot interactions, robot surveillance, video-conferences or smart glasses.
Gray Jedi MVDR Post-filtering
Sep 10, 2023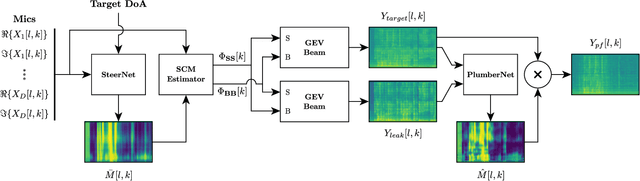
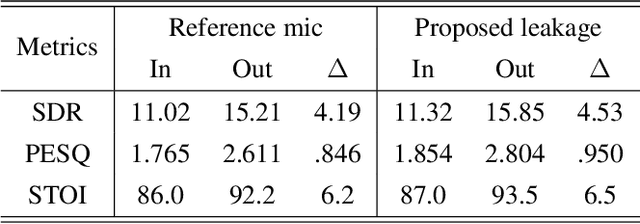
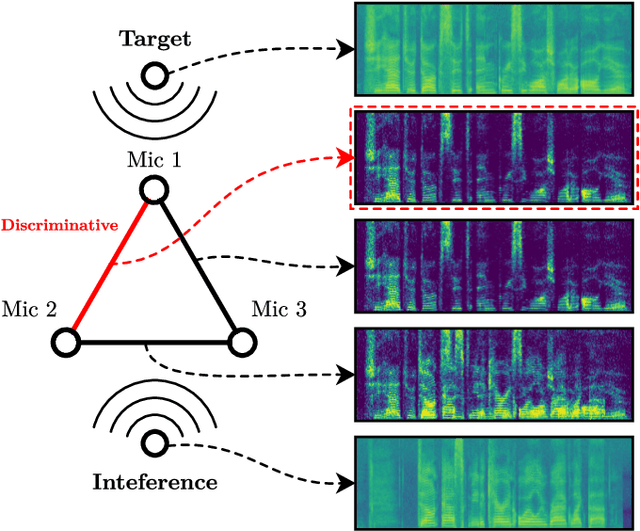
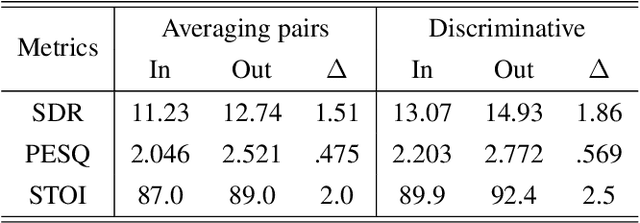
Spatial filters can exploit deep-learning-based speech enhancement models to increase their reliability in scenarios with multiple speech sources scenarios. To further improve speech quality, it is common to perform postfiltering on the estimated target speech obtained with spatial filtering. In this work, Minimum Variance Distortionless Response (MVDR) is employed to provide the interference estimation, along with the estimation of the target speech, to be later used for postfiltering. This improves the enhancement performance over a single-input baseline in a far more significant way than by increasing the model's complexity. Results suggest that less computing resources are required for postfiltering when provided with both target and interference signals, which is a step forward in developing an online speech enhancement system for multi-speech scenarios.
Ego-noise reduction of a mobile robot using noise spatial covariance matrix learning and minimum variance distortionless response
Mar 07, 2023



The performance of speech and events recognition systems significantly improved recently thanks to deep learning methods. However, some of these tasks remain challenging when algorithms are deployed on robots due to the unseen mechanical noise and electrical interference generated by their actuators while training the neural networks. Ego-noise reduction as a preprocessing step therefore can help solve this issue when using pre-trained speech and event recognition algorithms on robots. In this paper, we propose a new method to reduce ego-noise using only a microphone array and less than two minute of noise recordings. Using Principal Component Analysis (PCA), the best covariance matrix candidate is selected from a dictionary created online during calibration and used with the Minimum Variance Distortionless Response (MVDR) beamformer. Results show that the proposed method runs in real-time, improves the signal-to-distortion ratio (SDR) by up to 10 dB, decreases the word error rate (WER) by 55\% in some cases and increases the Average Precision (AP) of event detection by up to 0.2.
Real-time Audio Video Enhancement \\with a Microphone Array and Headphones
Mar 02, 2023



This paper presents a complete hardware and software pipeline for real-time speech enhancement in noisy and reverberant conditions. The device consists of a microphone array and a camera mounted on eyeglasses, connected to an embedded system that enhances speech and plays back the audio in headphones, with a latency of maximum 120 msec. The proposed approach relies on face detection, tracking and verification to enhance the speech of a target speaker using a beamformer and a postfiltering neural network. Results demonstrate the feasibility of the approach, and opens the door to the exploration and validation of a wide range of beamformer and speech enhancement methods for real-time speech enhancement.
Resource-Efficient Separation Transformer
Jun 19, 2022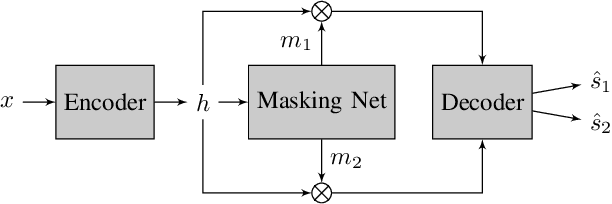
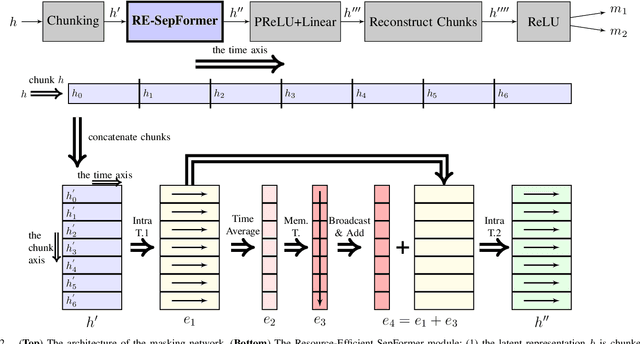
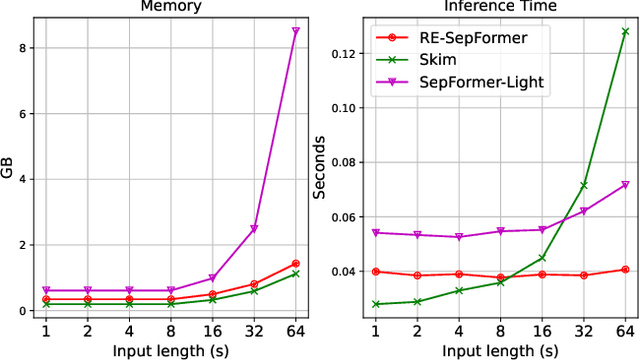
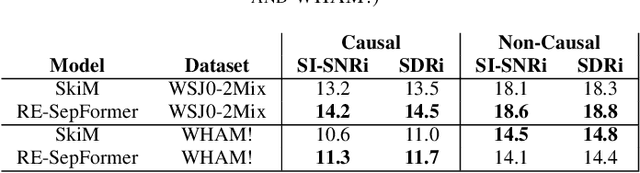
Transformers have recently achieved state-of-the-art performance in speech separation. These models, however, are computationally-demanding and require a lot of learnable parameters. This paper explores Transformer-based speech separation with a reduced computational cost. Our main contribution is the development of the Resource-Efficient Separation Transformer (RE-SepFormer), a self-attention-based architecture that reduces the computational burden in two ways. First, it uses non-overlapping blocks in the latent space. Second, it operates on compact latent summaries calculated from each chunk. The RE-SepFormer reaches a competitive performance on the popular WSJ0-2Mix and WHAM! datasets in both causal and non-causal settings. Remarkably, it scales significantly better than the previous Transformer and RNN-based architectures in terms of memory and inference-time, making it more suitable for processing long mixtures.
Fast Cross-Correlation for TDoA Estimation on Small Aperture Microphone Arrays
Apr 28, 2022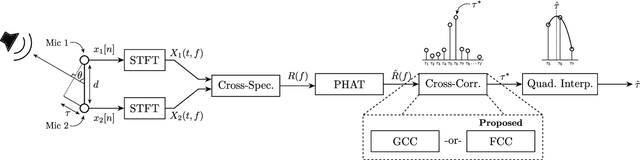
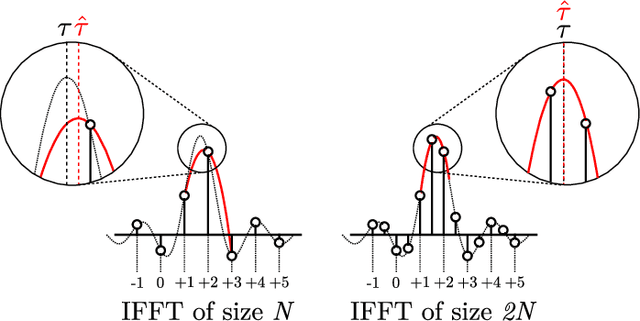
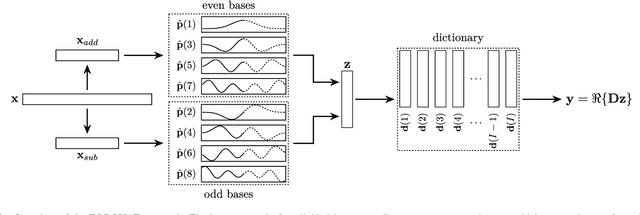
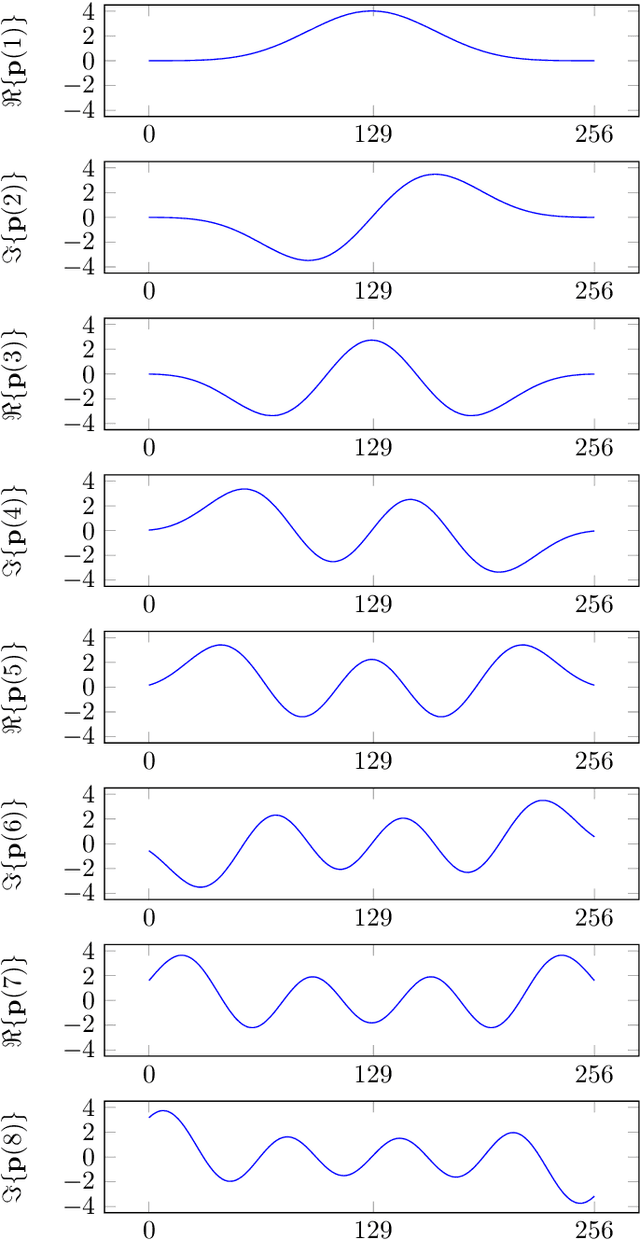
This paper introduces the Fast Cross-Correlation (FCC) method for Time Difference of Arrival (TDoA) Estimation for pairs of microphones on a small aperture microphone array. FCC relies on low-rank decomposition and exploits symmetry in even and odd bases to speed up computation while preserving TDoA accuracy. FCC reduces the number of flops by a factor of 4.5 and the execution speed by factors of 8.2, 2.6 and 2.7 on a Raspberry Pi Zero, a Raspberry Pi 4 and a Nvidia Jetson TX2 devices, respectively, compared to the state-of-the-art Generalized Cross-Correlation (GCC) method that relies on the Fast Fourier Transform (FFT). This improvement can provide portable microphone arrays with extended battery life and allow real-time processing on low-cost hardware.
SMP-PHAT: Lightweight DoA Estimation by Merging Microphone Pairs
Mar 27, 2022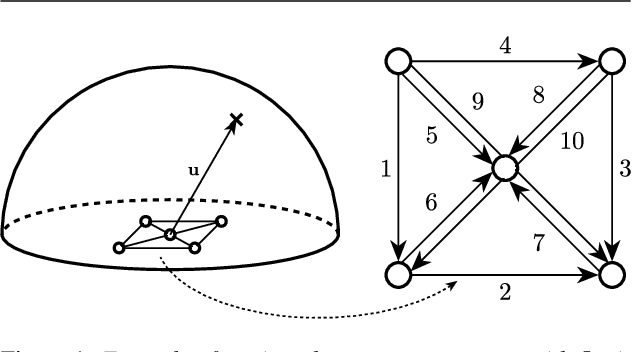
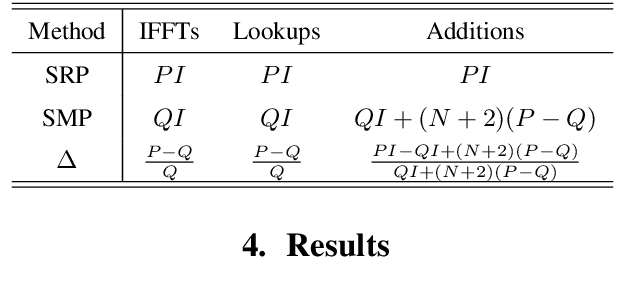
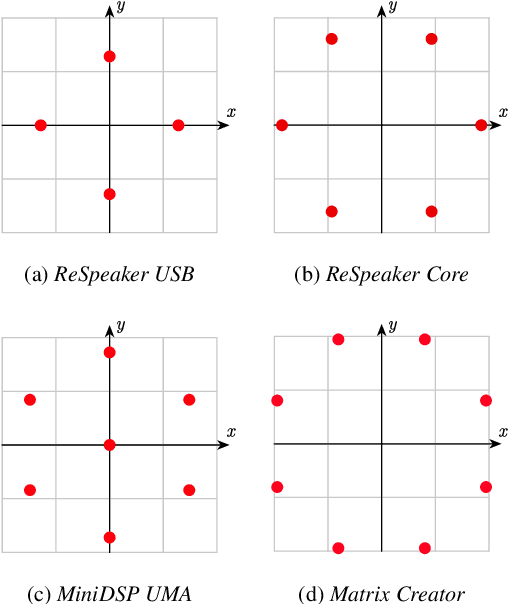
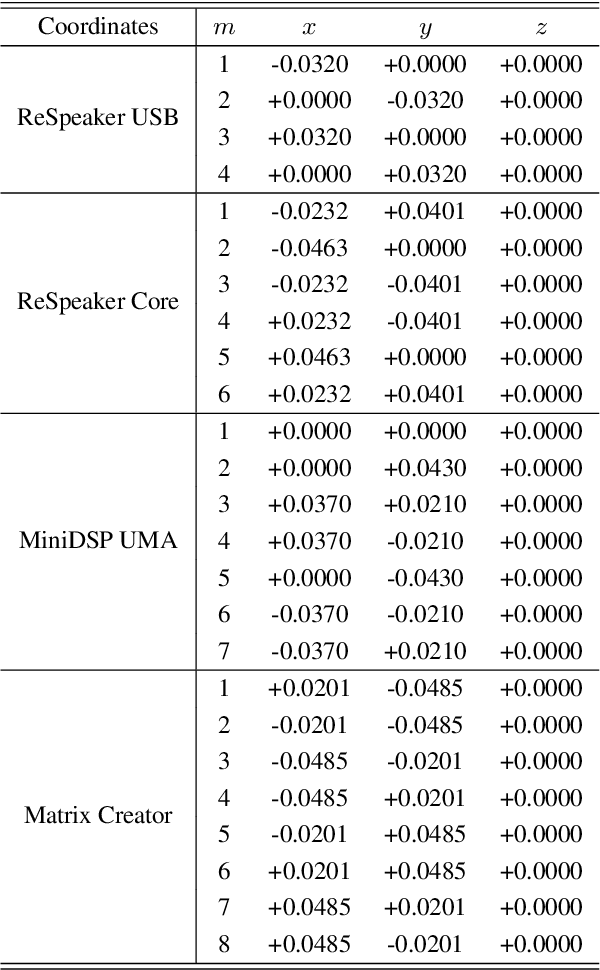
This paper introduces SMP-PHAT, which performs direction of arrival (DoA) of sound estimation with a microphone array by merging pairs of microphones that are parallel in space. This approach reduces the number of pairwise cross-correlation computations, and brings down the number of flops and memory lookups when searching for DoA. Experiments on low-cost hardware with commonly used microphone arrays show that the proposed method provides the same accuracy as the former SRP-PHAT approach, while reducing the computational load by 39% in some cases.
SmartBelt: A Wearable Microphone Array for Sound Source Localization with Haptic Feedback
Feb 28, 2022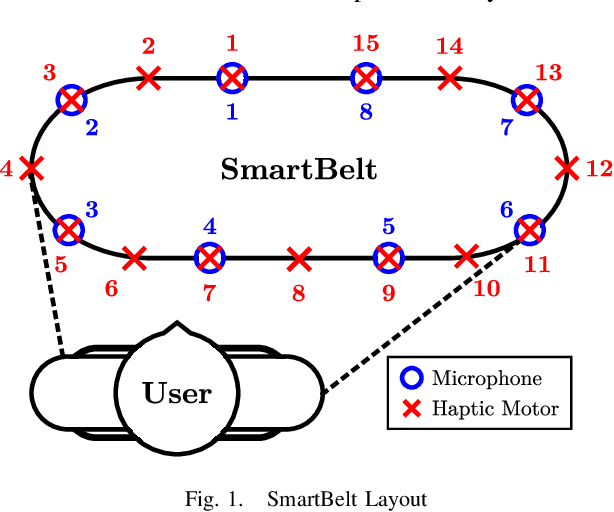

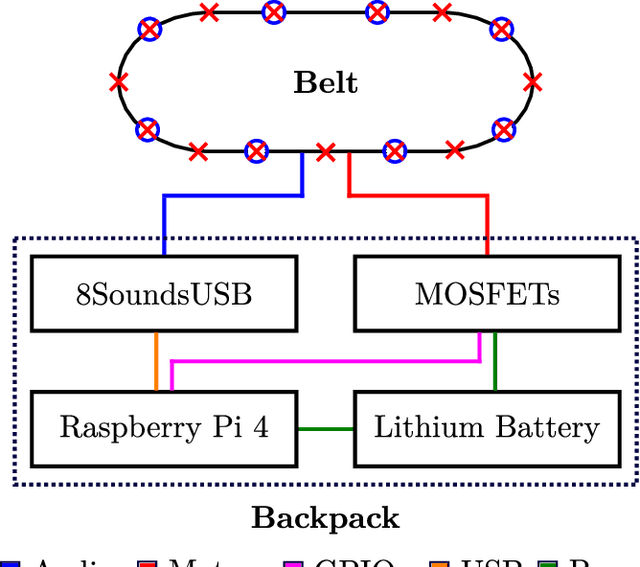
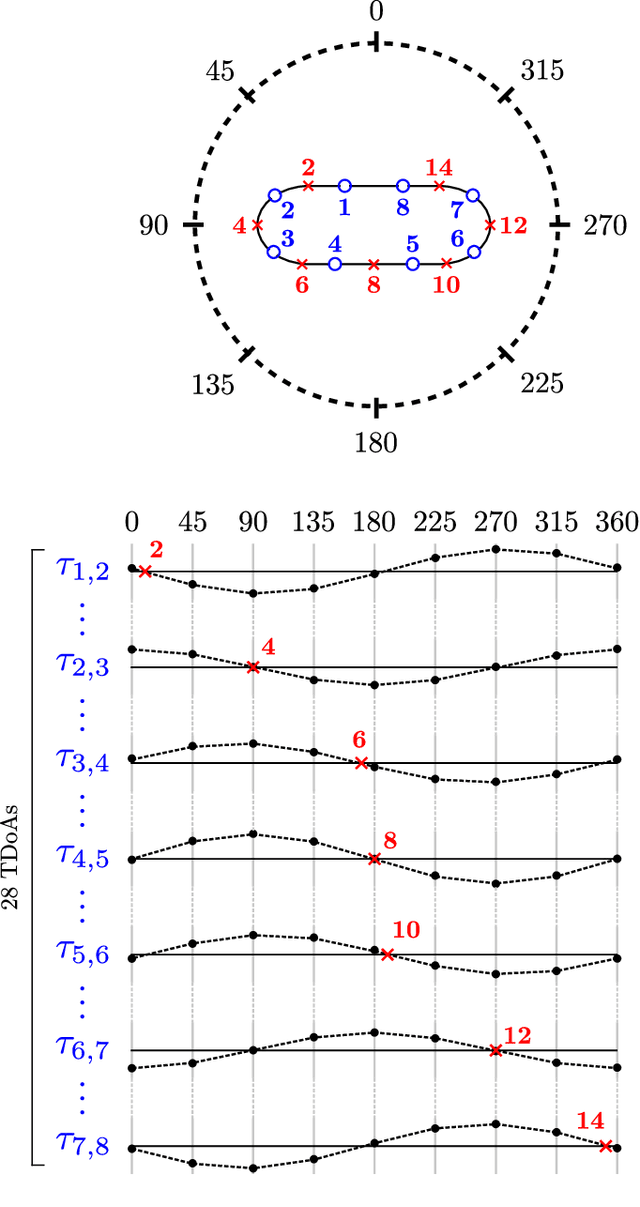
This paper introduces SmartBelt, a wearable microphone array on a belt that performs sound source localization and returns the direction of arrival with respect to the user waist. One of the haptic motors on the belt then vibrates in the corresponding direction to provide useful feedback to the user. We also introduce a simple calibration step to adapt the belt to different waist sizes. Experiments are performed to confirm the accuracy of this wearable sound source localization system, and results show a Mean Average Error (MAE) of 2.90 degrees, and a correct haptic motor selection with a rate of 92.3%. Results suggest the device can provide useful haptic feedback, and will be evaluated in a study with people having hearing impairments.