 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Improved MVDR Beamforming for Sound Enhancement
Jun 12, 2024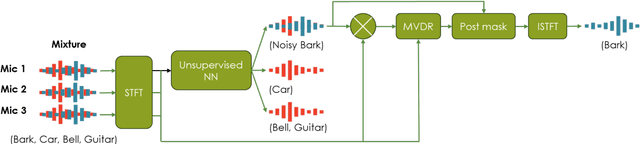
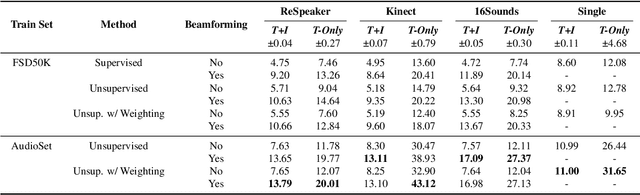
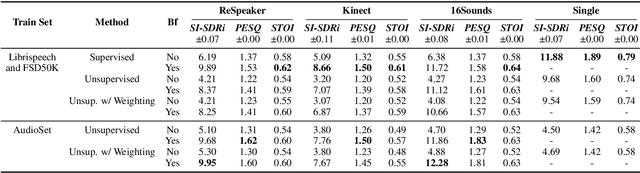
Neural networks have recently become the dominant approach to sound separation. Their good performance relies on large datasets of isolated recordings. For speech and music, isolated single channel data are readily available; however the same does not hold in the multi-channel case, and with most other sound classes. Multi-channel methods have the potential to outperform single channel approaches as they can exploit both spatial and spectral features, but the lack of training data remains a challenge. We propose unsupervised improved minimum variation distortionless response (UIMVDR), which enables multi-channel separation to leverage in-the-wild single-channel data through unsupervised training and beamforming. Results show that UIMVDR generalizes well and improves separation performance compared to supervised models, particularly in cases with limited supervised data. By using data available online, it also reduces the effort required to gather data for multi-channel approaches.
Real-time Audio Video Enhancement \\with a Microphone Array and Headphones
Mar 02, 2023



This paper presents a complete hardware and software pipeline for real-time speech enhancement in noisy and reverberant conditions. The device consists of a microphone array and a camera mounted on eyeglasses, connected to an embedded system that enhances speech and plays back the audio in headphones, with a latency of maximum 120 msec. The proposed approach relies on face detection, tracking and verification to enhance the speech of a target speaker using a beamformer and a postfiltering neural network. Results demonstrate the feasibility of the approach, and opens the door to the exploration and validation of a wide range of beamformer and speech enhancement methods for real-time speech enhancement.