 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Face Detection with Audio-Based Region Proposals
Sep 14, 2023Robot vision often involves a large computational load due to large images to process in a short amount of time. Existing solutions often involve reducing image quality which can negatively impact processing. Another approach is to generate regions of interest with expensive vision algorithms. In this paper, we evaluate how audio can be used to generate regions of interest in optical images. To achieve this, we propose a unique attention mechanism to localize speech sources and evaluate its impact on a face detection algorithm. Our results show that the attention mechanism reduces the computational load. The proposed pipeline is flexible and can be easily adapted for human-robot interactions, robot surveillance, video-conferences or smart glasses.
SpeechBrain: A General-Purpose Speech Toolkit
Jun 08, 2021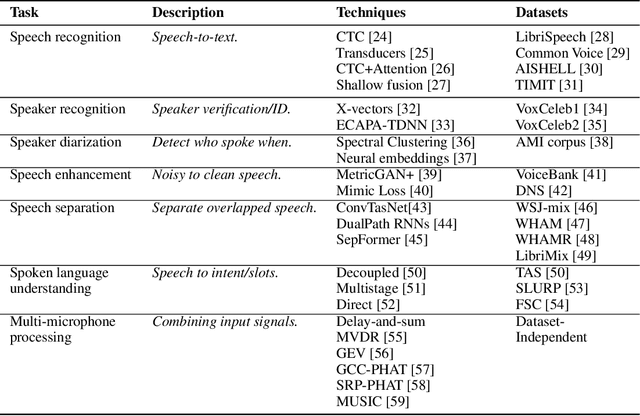
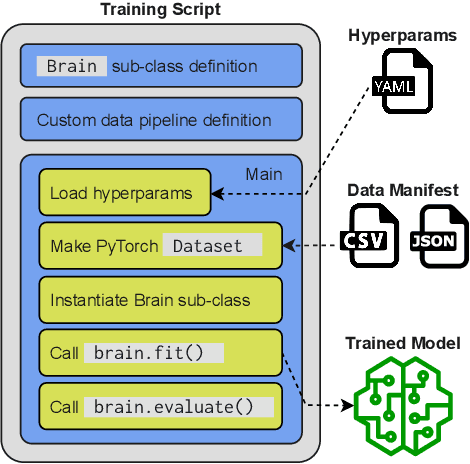

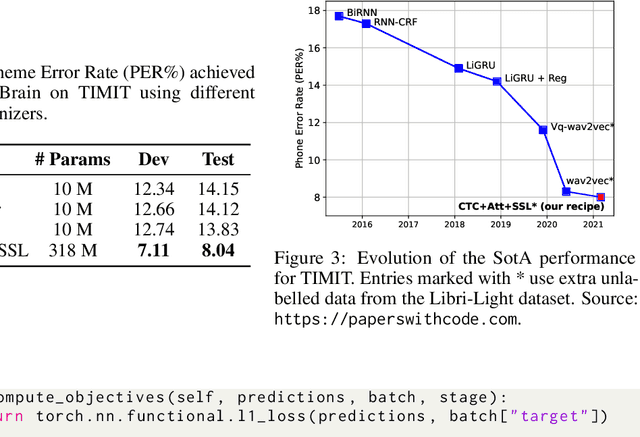
SpeechBrain is an open-source and all-in-one speech toolkit. It is designed to facilitate the research and development of neural speech processing technologies by being simple, flexible, user-friendly, and well-documented. This paper describes the core architecture designed to support several tasks of common interest, allowing users to naturally conceive, compare and share novel speech processing pipelines. SpeechBrain achieves competitive or state-of-the-art performance in a wide range of speech benchmarks. It also provides training recipes, pretrained models, and inference scripts for popular speech datasets, as well as tutorials which allow anyone with basic Python proficiency to familiarize themselves with speech technologies.