 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscrete Audio Tokens: More Than a Survey!
Jun 12, 2025Discrete audio tokens are compact representations that aim to preserve perceptual quality, phonetic content, and speaker characteristics while enabling efficient storage and inference, as well as competitive performance across diverse downstream tasks.They provide a practical alternative to continuous features, enabling the integration of speech and audio into modern large language models (LLMs). As interest in token-based audio processing grows, various tokenization methods have emerged, and several surveys have reviewed the latest progress in the field. However, existing studies often focus on specific domains or tasks and lack a unified comparison across various benchmarks. This paper presents a systematic review and benchmark of discrete audio tokenizers, covering three domains: speech, music, and general audio. We propose a taxonomy of tokenization approaches based on encoder-decoder, quantization techniques, training paradigm, streamability, and application domains. We evaluate tokenizers on multiple benchmarks for reconstruction, downstream performance, and acoustic language modeling, and analyze trade-offs through controlled ablation studies. Our findings highlight key limitations, practical considerations, and open challenges, providing insight and guidance for future research in this rapidly evolving area. For more information, including our main results and tokenizer database, please refer to our website: https://poonehmousavi.github.io/dates-website/.
Unsupervised ASR via Cross-Lingual Pseudo-Labeling
May 19, 2023

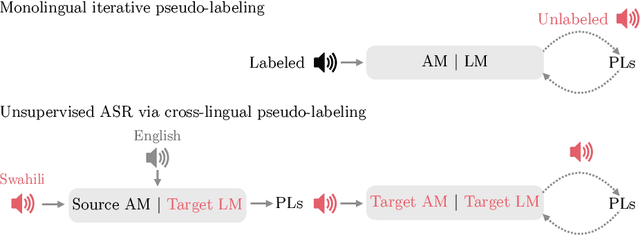

Recent work has shown that it is possible to train an $\textit{unsupervised}$ automatic speech recognition (ASR) system using only unpaired audio and text. Existing unsupervised ASR methods assume that no labeled data can be used for training. We argue that even if one does not have any labeled audio for a given language, there is $\textit{always}$ labeled data available for other languages. We show that it is possible to use character-level acoustic models (AMs) from other languages to bootstrap an $\textit{unsupervised}$ AM in a new language. Here, "unsupervised" means no labeled audio is available for the $\textit{target}$ language. Our approach is based on two key ingredients: (i) generating pseudo-labels (PLs) of the $\textit{target}$ language using some $\textit{other}$ language AM and (ii) constraining these PLs with a $\textit{target language model}$. Our approach is effective on Common Voice: e.g. transfer of English AM to Swahili achieves 18% WER. It also outperforms character-based wav2vec-U 2.0 by 15% absolute WER on LJSpeech with 800h of labeled German data instead of 60k hours of unlabeled English data.
Pseudo-Labeling for Massively Multilingual Speech Recognition
Oct 30, 2021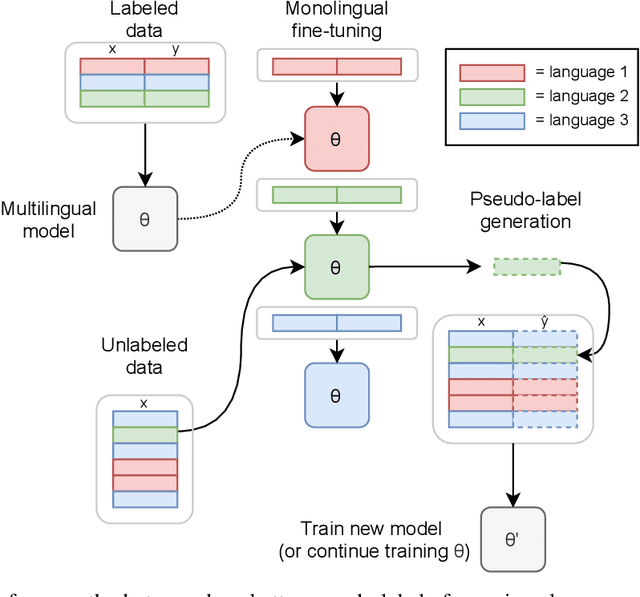
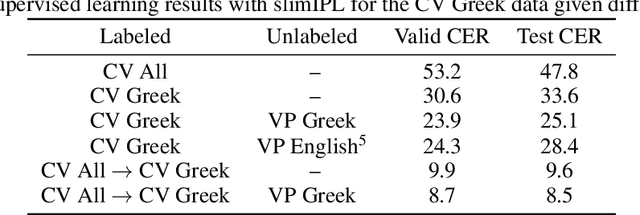
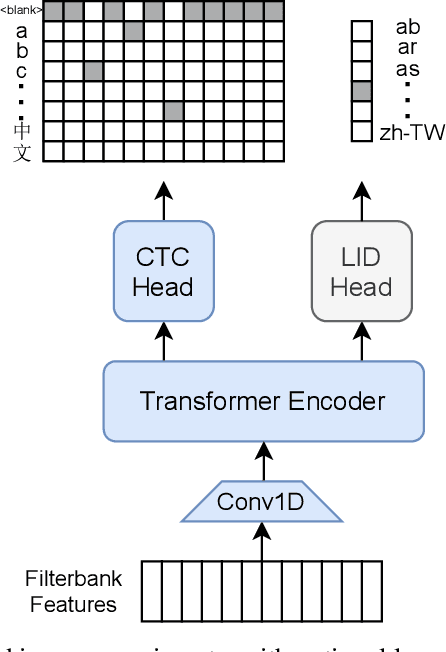
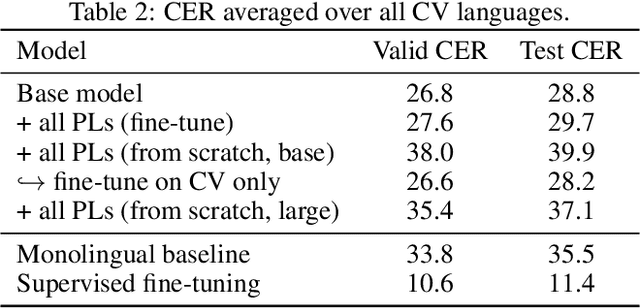
Semi-supervised learning through pseudo-labeling has become a staple of state-of-the-art monolingual speech recognition systems. In this work, we extend pseudo-labeling to massively multilingual speech recognition with 60 languages. We propose a simple pseudo-labeling recipe that works well even with low-resource languages: train a supervised multilingual model, fine-tune it with semi-supervised learning on a target language, generate pseudo-labels for that language, and train a final model using pseudo-labels for all languages, either from scratch or by fine-tuning. Experiments on the labeled Common Voice and unlabeled VoxPopuli datasets show that our recipe can yield a model with better performance for many languages that also transfers well to LibriSpeech.
SpeechBrain: A General-Purpose Speech Toolkit
Jun 08, 2021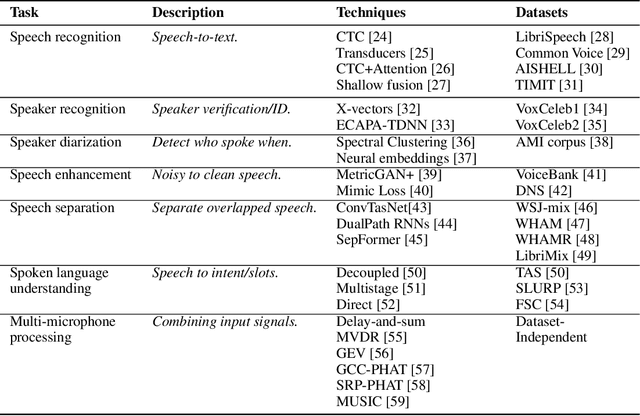
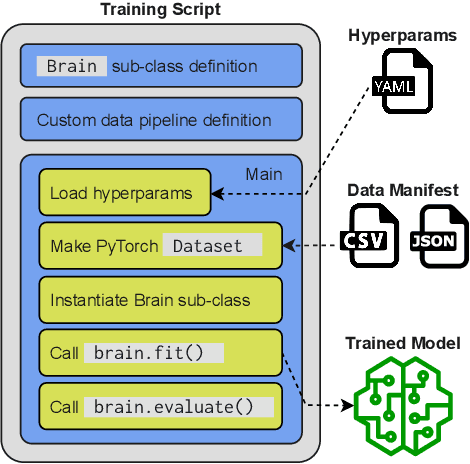

SpeechBrain is an open-source and all-in-one speech toolkit. It is designed to facilitate the research and development of neural speech processing technologies by being simple, flexible, user-friendly, and well-documented. This paper describes the core architecture designed to support several tasks of common interest, allowing users to naturally conceive, compare and share novel speech processing pipelines. SpeechBrain achieves competitive or state-of-the-art performance in a wide range of speech benchmarks. It also provides training recipes, pretrained models, and inference scripts for popular speech datasets, as well as tutorials which allow anyone with basic Python proficiency to familiarize themselves with speech technologies.
Timers and Such: A Practical Benchmark for Spoken Language Understanding with Numbers
Apr 04, 2021
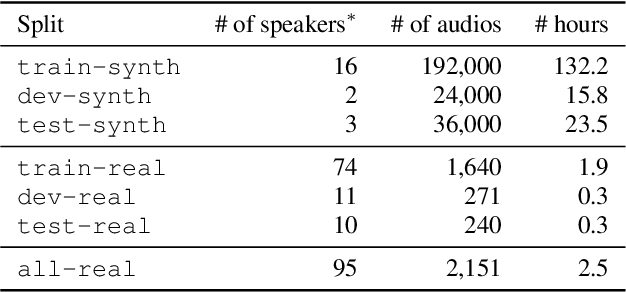
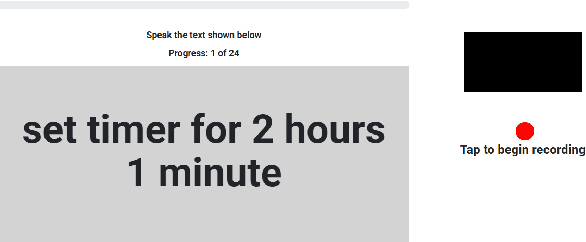
This paper introduces Timers and Such, a new open source dataset of spoken English commands for common voice control use cases involving numbers. We describe the gap in existing spoken language understanding datasets that Timers and Such fills, the design and creation of the dataset, and experiments with a number of ASR-based and end-to-end baseline models, the code for which has been made available as part of the SpeechBrain toolkit.
Surprisal-Triggered Conditional Computation with Neural Networks
Jun 02, 2020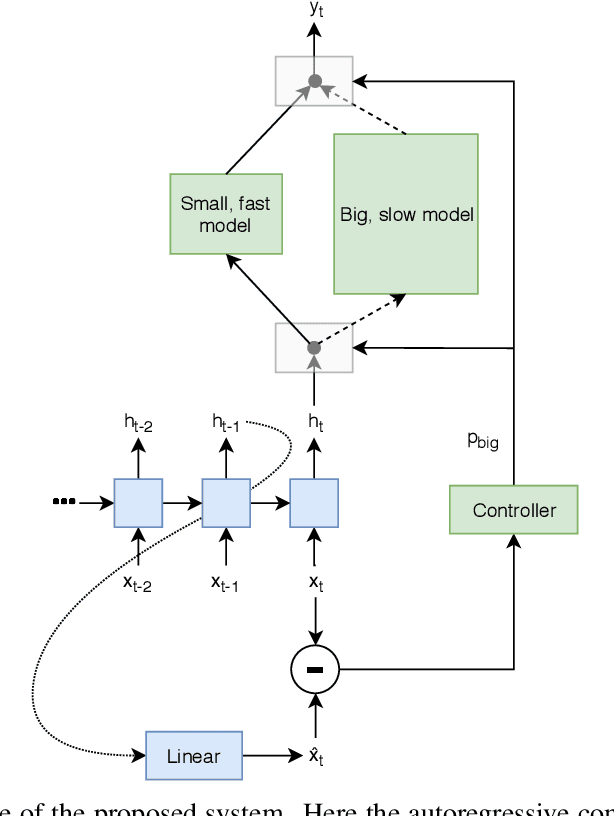

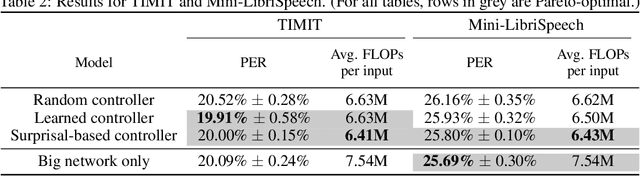
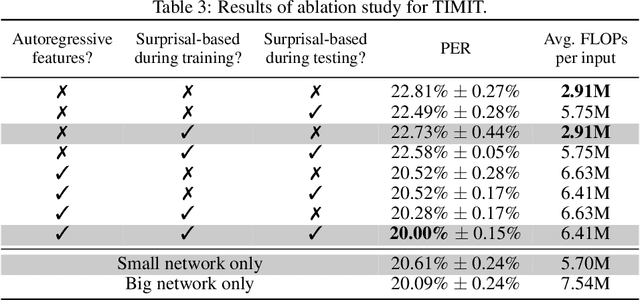
Autoregressive neural network models have been used successfully for sequence generation, feature extraction, and hypothesis scoring. This paper presents yet another use for these models: allocating more computation to more difficult inputs. In our model, an autoregressive model is used both to extract features and to predict observations in a stream of input observations. The surprisal of the input, measured as the negative log-likelihood of the current observation according to the autoregressive model, is used as a measure of input difficulty. This in turn determines whether a small, fast network, or a big, slow network, is used. Experiments on two speech recognition tasks show that our model can match the performance of a baseline in which the big network is always used with 15% fewer FLOPs.
Speech Model Pre-training for End-to-End Spoken Language Understanding
Apr 07, 2019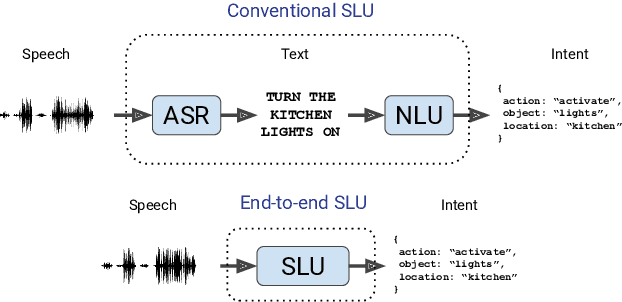
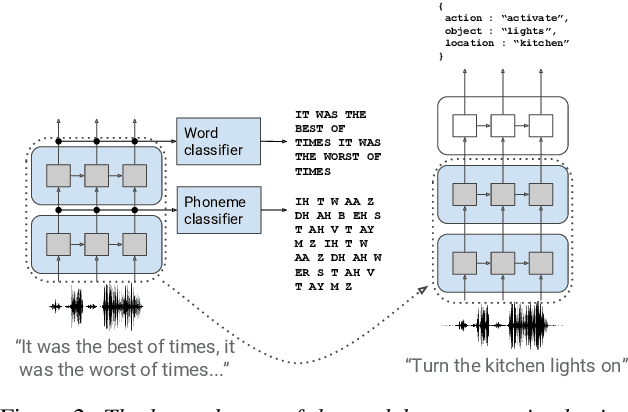
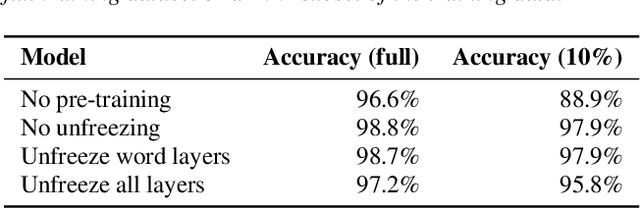
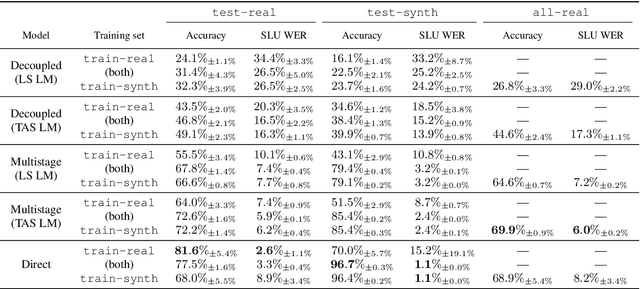
Whereas conventional spoken language understanding (SLU) systems map speech to text, and then text to intent, end-to-end SLU systems map speech directly to intent through a single trainable model. Achieving high accuracy with these end-to-end models without a large amount of training data is difficult. We propose a method to reduce the data requirements of end-to-end SLU in which the model is first pre-trained to predict words and phonemes, thus learning good features for SLU. We introduce a new SLU dataset, Fluent Speech Commands, and show that our method improves performance both when the full dataset is used for training and when only a small subset is used. We also describe preliminary experiments to gauge the model's ability to generalize to new phrases not heard during training.
DONUT: CTC-based Query-by-Example Keyword Spotting
Nov 26, 2018

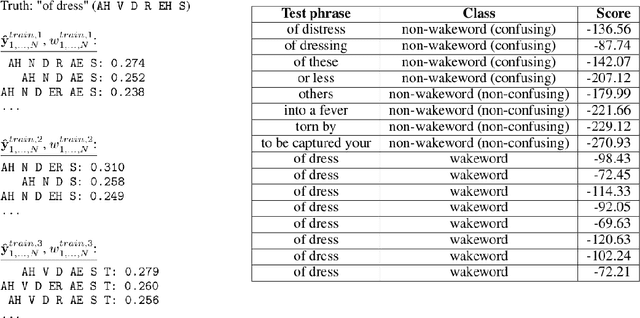
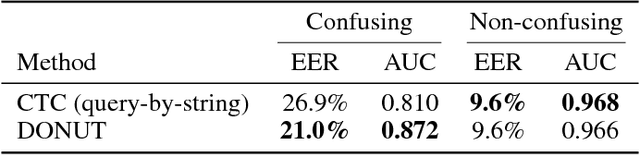
Keyword spotting--or wakeword detection--is an essential feature for hands-free operation of modern voice-controlled devices. With such devices becoming ubiquitous, users might want to choose a personalized custom wakeword. In this work, we present DONUT, a CTC-based algorithm for online query-by-example keyword spotting that enables custom wakeword detection. The algorithm works by recording a small number of training examples from the user, generating a set of label sequence hypotheses from these training examples, and detecting the wakeword by aggregating the scores of all the hypotheses given a new audio recording. Our method combines the generalization and interpretability of CTC-based keyword spotting with the user-adaptation and convenience of a conventional query-by-example system. DONUT has low computational requirements and is well-suited for both learning and inference on embedded systems without requiring private user data to be uploaded to the cloud.
Learning from the Syndrome
Oct 23, 2018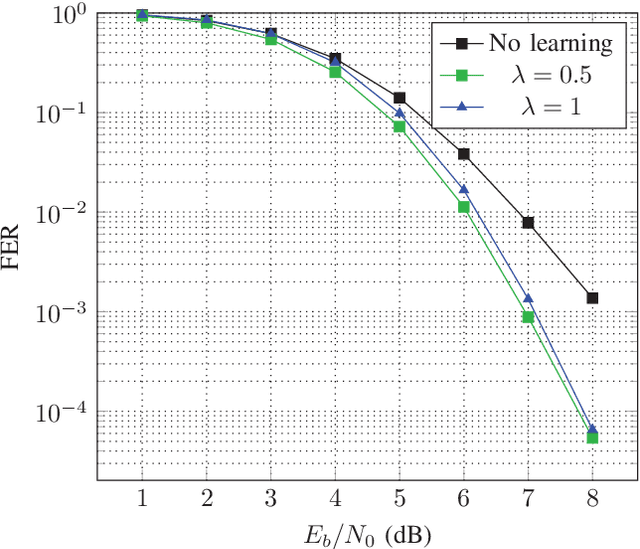
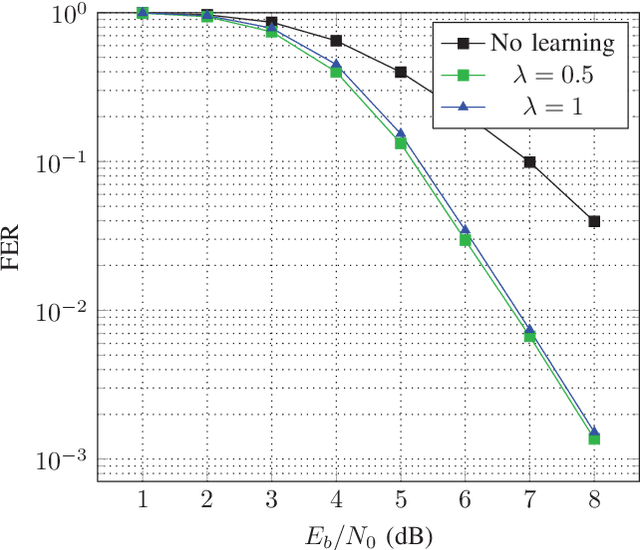
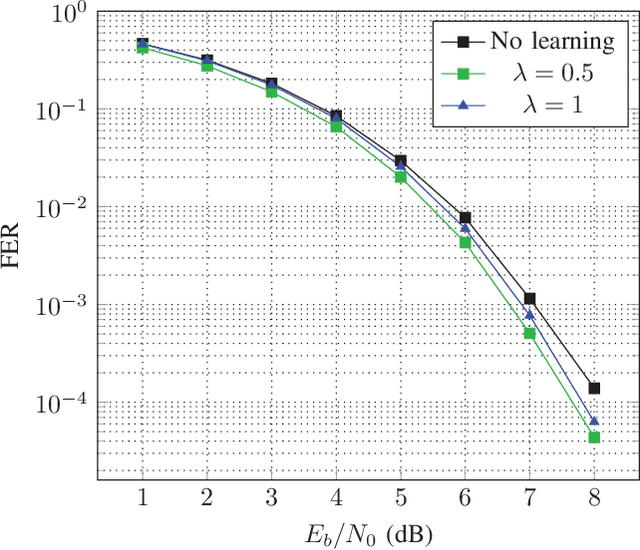
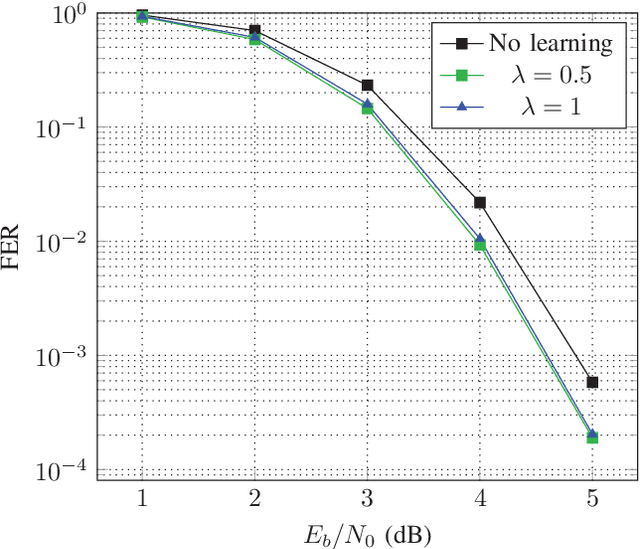
In this paper, we introduce the syndrome loss, an alternative loss function for neural error-correcting decoders based on a relaxation of the syndrome. The syndrome loss penalizes the decoder for producing outputs that do not correspond to valid codewords. We show that training with the syndrome loss yields decoders with consistently lower frame error rate for a number of short block codes, at little additional cost during training and no additional cost during inference. The proposed method does not depend on knowledge of the transmitted codeword, making it a promising tool for online adaptation to changing channel conditions.
Deep Learning Methods for Improved Decoding of Linear Codes
Jan 01, 2018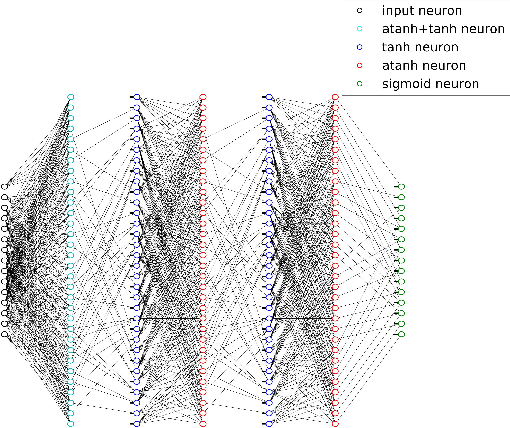
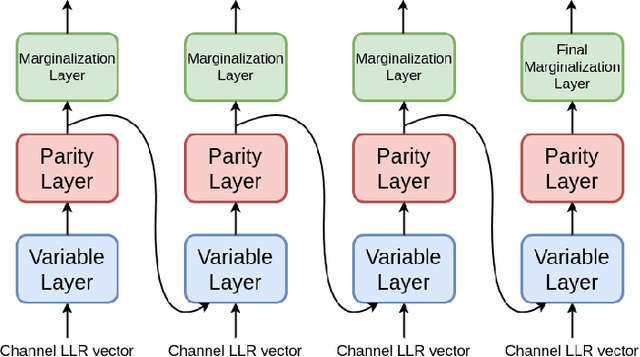
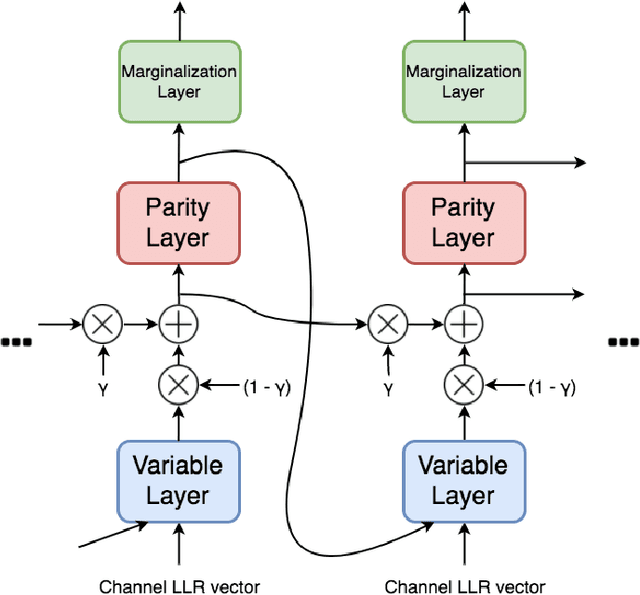
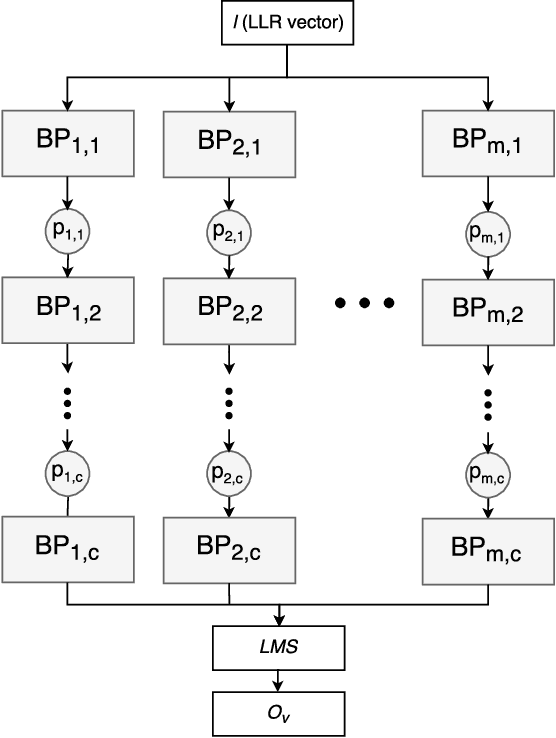
The problem of low complexity, close to optimal, channel decoding of linear codes with short to moderate block length is considered. It is shown that deep learning methods can be used to improve a standard belief propagation decoder, despite the large example space. Similar improvements are obtained for the min-sum algorithm. It is also shown that tying the parameters of the decoders across iterations, so as to form a recurrent neural network architecture, can be implemented with comparable results. The advantage is that significantly less parameters are required. We also introduce a recurrent neural decoder architecture based on the method of successive relaxation. Improvements over standard belief propagation are also observed on sparser Tanner graph representations of the codes. Furthermore, we demonstrate that the neural belief propagation decoder can be used to improve the performance, or alternatively reduce the computational complexity, of a close to optimal decoder of short BCH codes.