 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Pruning of Fine-tuning Datasets for Transformer-based Language Models
Jul 11, 2024Transformer-based language models have shown state-of-the-art performance on a variety of natural language understanding tasks. To achieve this performance, these models are first pre-trained on general corpus and then fine-tuned on downstream tasks. Previous work studied the effect of pruning the training set of the downstream tasks on the performance of the model on its evaluation set. In this work, we propose an automatic dataset pruning method for the training set of fine-tuning tasks. Our method is based on the model's success rate in correctly classifying each training data point. Unlike previous work which relies on user feedback to determine subset size, our method automatically extracts training subsets that are adapted for each pair of model and fine-tuning task. Our method provides multiple subsets for use in dataset pruning that navigate the trade-off between subset size and evaluation accuracy. Our largest subset, which we also refer to as the winning ticket subset, is on average $3 \times$ smaller than the original training set of the fine-tuning task. Our experiments on 5 downstream tasks and 2 language models show that, on average, fine-tuning on the winning ticket subsets results in a $0.1 \%$ increase in the evaluation performance of the model.
SSS3D: Fast Neural Architecture Search For Efficient Three-Dimensional Semantic Segmentation
Apr 21, 2023



We present SSS3D, a fast multi-objective NAS framework designed to find computationally efficient 3D semantic scene segmentation networks. It uses RandLA-Net, an off-the-shelf point-based network, as a super-network to enable weight sharing and reduce search time by 99.67% for single-stage searches. SSS3D has a complex search space composed of sampling and architectural parameters that can form 2.88 * 10^17 possible networks. To further reduce search time, SSS3D splits the complete search space and introduces a two-stage search that finds optimal subnetworks in 54% of the time required by single-stage searches.
FMAS: Fast Multi-Objective SuperNet Architecture Search for Semantic Segmentation
Mar 28, 2023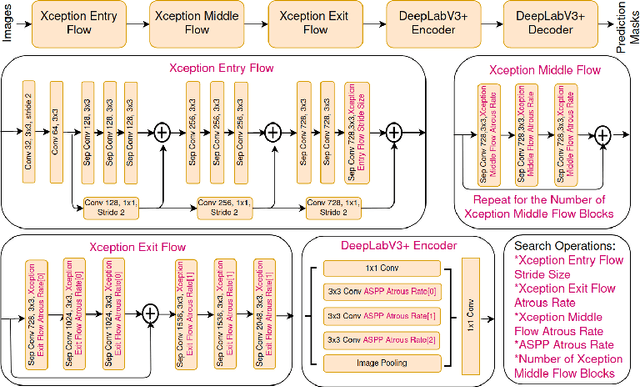
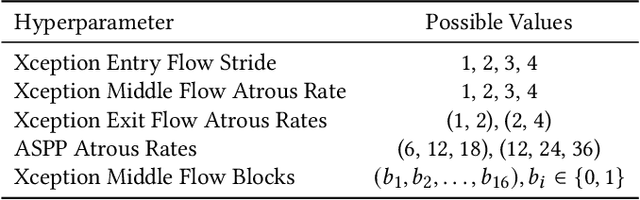
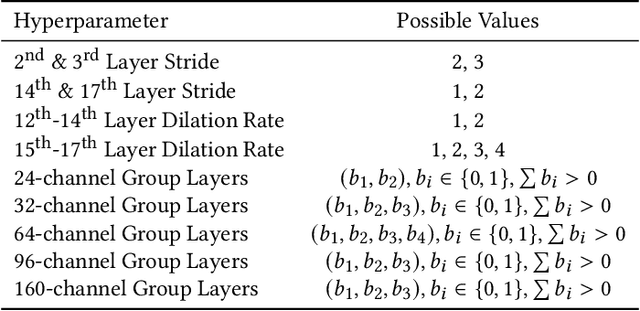
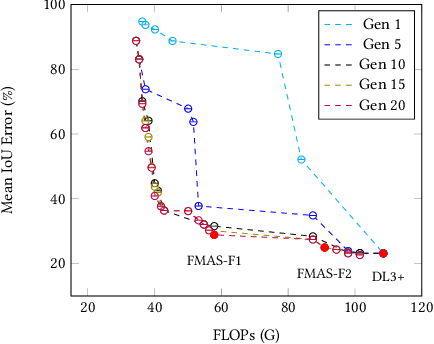
We present FMAS, a fast multi-objective neural architecture search framework for semantic segmentation. FMAS subsamples the structure and pre-trained parameters of DeepLabV3+, without fine-tuning, dramatically reducing training time during search. To further reduce candidate evaluation time, we use a subset of the validation dataset during the search. Only the final, Pareto non-dominated, candidates are ultimately fine-tuned using the complete training set. We evaluate FMAS by searching for models that effectively trade accuracy and computational cost on the PASCAL VOC 2012 dataset. FMAS finds competitive designs quickly, e.g., taking just 0.5 GPU days to discover a DeepLabV3+ variant that reduces FLOPs and parameters by 10$\%$ and 20$\%$ respectively, for less than 3$\%$ increased error. We also search on an edge device called GAP8 and use its latency as the metric. FMAS is capable of finding 2.2$\times$ faster network with 7.61$\%$ MIoU loss.
BD-KD: Balancing the Divergences for Online Knowledge Distillation
Dec 25, 2022Knowledge distillation (KD) has gained a lot of attention in the field of model compression for edge devices thanks to its effectiveness in compressing large powerful networks into smaller lower-capacity models. Online distillation, in which both the teacher and the student are learning collaboratively, has also gained much interest due to its ability to improve on the performance of the networks involved. The Kullback-Leibler (KL) divergence ensures the proper knowledge transfer between the teacher and student. However, most online KD techniques present some bottlenecks under the network capacity gap. By cooperatively and simultaneously training, the models the KL distance becomes incapable of properly minimizing the teacher's and student's distributions. Alongside accuracy, critical edge device applications are in need of well-calibrated compact networks. Confidence calibration provides a sensible way of getting trustworthy predictions. We propose BD-KD: Balancing of Divergences for online Knowledge Distillation. We show that adaptively balancing between the reverse and forward divergences shifts the focus of the training strategy to the compact student network without limiting the teacher network's learning process. We demonstrate that, by performing this balancing design at the level of the student distillation loss, we improve upon both performance accuracy and calibration of the compact student network. We conducted extensive experiments using a variety of network architectures and show improvements on multiple datasets including CIFAR-10, CIFAR-100, Tiny-ImageNet, and ImageNet. We illustrate the effectiveness of our approach through comprehensive comparisons and ablations with current state-of-the-art online and offline KD techniques.
CES-KD: Curriculum-based Expert Selection for Guided Knowledge Distillation
Sep 15, 2022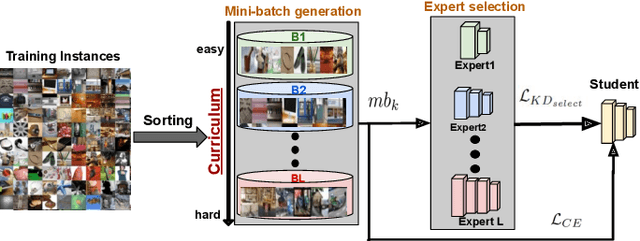
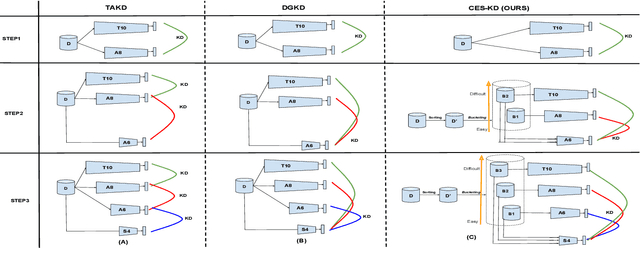
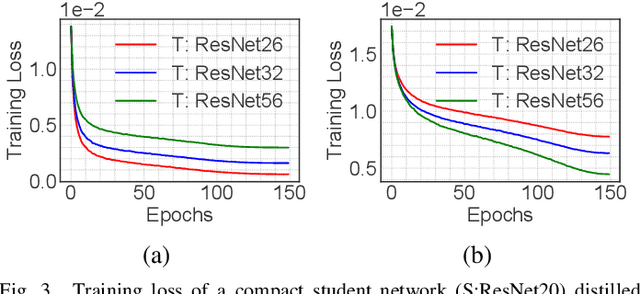
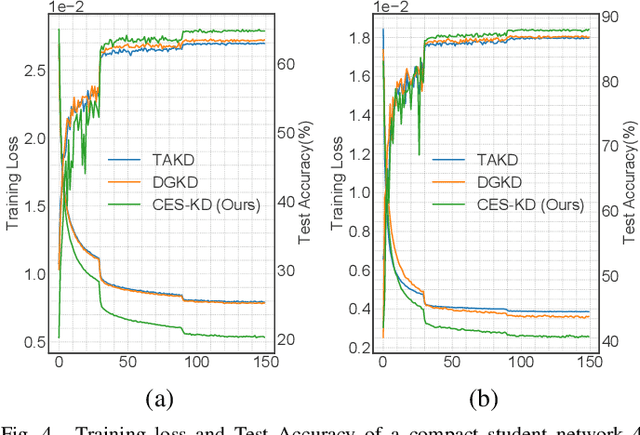
Knowledge distillation (KD) is an effective tool for compressing deep classification models for edge devices. However, the performance of KD is affected by the large capacity gap between the teacher and student networks. Recent methods have resorted to a multiple teacher assistant (TA) setting for KD, which sequentially decreases the size of the teacher model to relatively bridge the size gap between these models. This paper proposes a new technique called Curriculum Expert Selection for Knowledge Distillation (CES-KD) to efficiently enhance the learning of a compact student under the capacity gap problem. This technique is built upon the hypothesis that a student network should be guided gradually using stratified teaching curriculum as it learns easy (hard) data samples better and faster from a lower (higher) capacity teacher network. Specifically, our method is a gradual TA-based KD technique that selects a single teacher per input image based on a curriculum driven by the difficulty in classifying the image. In this work, we empirically verify our hypothesis and rigorously experiment with CIFAR-10, CIFAR-100, CINIC-10, and ImageNet datasets and show improved accuracy on VGG-like models, ResNets, and WideResNets architectures.
Efficient Fine-Tuning of Compressed Language Models with Learners
Aug 03, 2022
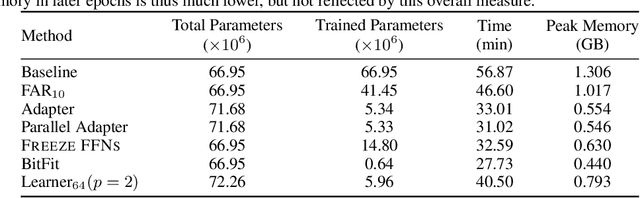

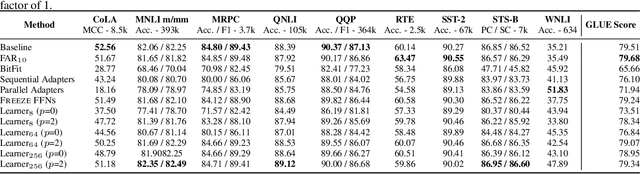
Fine-tuning BERT-based models is resource-intensive in memory, computation, and time. While many prior works aim to improve inference efficiency via compression techniques, e.g., pruning, these works do not explicitly address the computational challenges of training to downstream tasks. We introduce Learner modules and priming, novel methods for fine-tuning that exploit the overparameterization of pre-trained language models to gain benefits in convergence speed and resource utilization. Learner modules navigate the double bind of 1) training efficiently by fine-tuning a subset of parameters, and 2) training effectively by ensuring quick convergence and high metric scores. Our results on DistilBERT demonstrate that learners perform on par with or surpass the baselines. Learners train 7x fewer parameters than state-of-the-art methods on GLUE. On CoLA, learners fine-tune 20% faster, and have significantly lower resource utilization.
Efficient Fine-Tuning of BERT Models on the Edge
May 03, 2022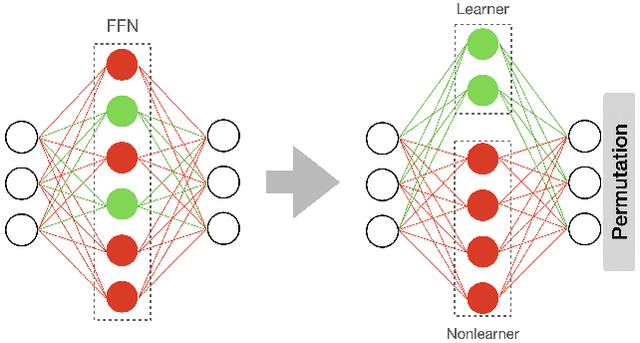
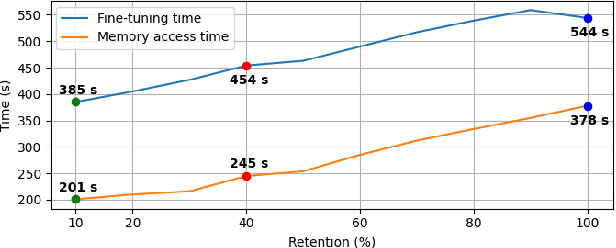

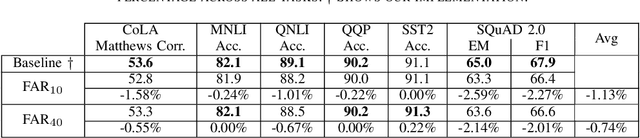
Resource-constrained devices are increasingly the deployment targets of machine learning applications. Static models, however, do not always suffice for dynamic environments. On-device training of models allows for quick adaptability to new scenarios. With the increasing size of deep neural networks, as noted with the likes of BERT and other natural language processing models, comes increased resource requirements, namely memory, computation, energy, and time. Furthermore, training is far more resource intensive than inference. Resource-constrained on-device learning is thus doubly difficult, especially with large BERT-like models. By reducing the memory usage of fine-tuning, pre-trained BERT models can become efficient enough to fine-tune on resource-constrained devices. We propose Freeze And Reconfigure (FAR), a memory-efficient training regime for BERT-like models that reduces the memory usage of activation maps during fine-tuning by avoiding unnecessary parameter updates. FAR reduces fine-tuning time on the DistilBERT model and CoLA dataset by 30%, and time spent on memory operations by 47%. More broadly, reductions in metric performance on the GLUE and SQuAD datasets are around 1% on average.
Surprisal-Triggered Conditional Computation with Neural Networks
Jun 02, 2020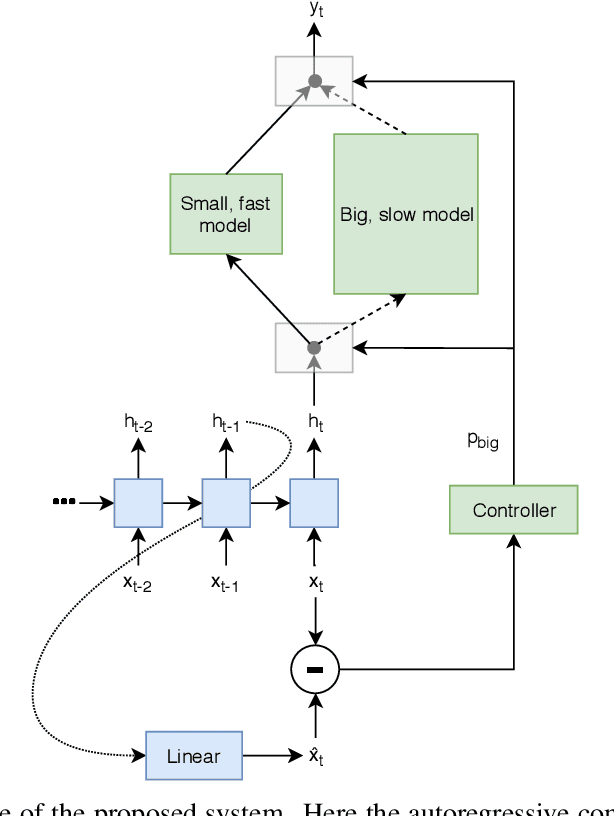

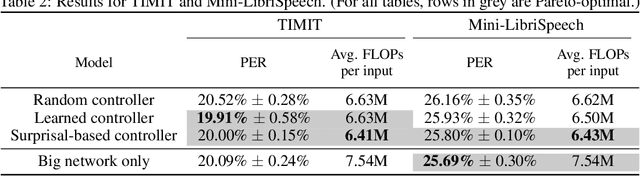
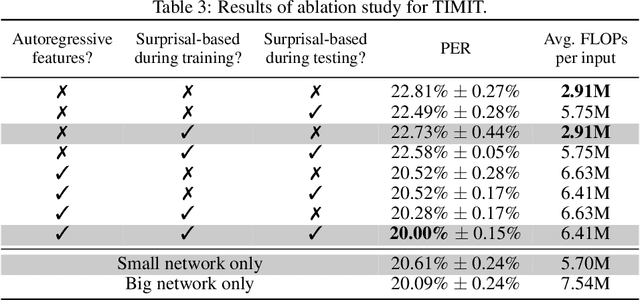
Autoregressive neural network models have been used successfully for sequence generation, feature extraction, and hypothesis scoring. This paper presents yet another use for these models: allocating more computation to more difficult inputs. In our model, an autoregressive model is used both to extract features and to predict observations in a stream of input observations. The surprisal of the input, measured as the negative log-likelihood of the current observation according to the autoregressive model, is used as a measure of input difficulty. This in turn determines whether a small, fast network, or a big, slow network, is used. Experiments on two speech recognition tasks show that our model can match the performance of a baseline in which the big network is always used with 15% fewer FLOPs.
Learning Recurrent Binary/Ternary Weights
Sep 28, 2018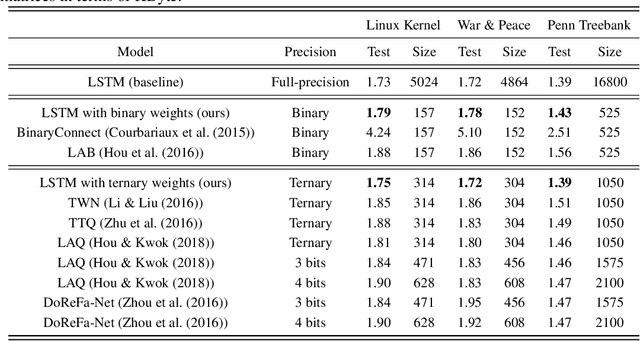
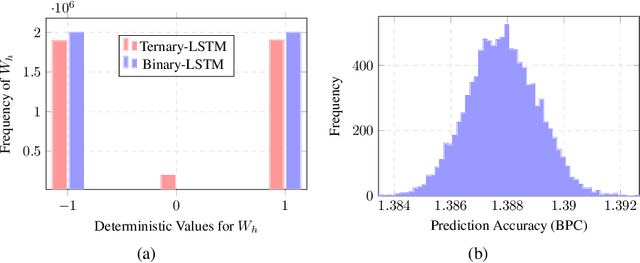

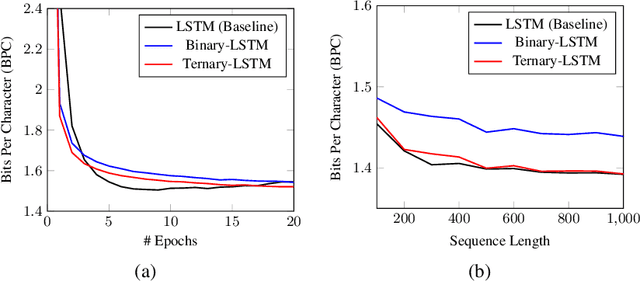
Recurrent neural networks (RNNs) have shown excellent performance in processing sequence data. However, they are both complex and memory intensive due to their recursive nature. These limitations make RNNs difficult to embed on mobile devices requiring real-time processes with limited hardware resources. To address the above issues, we introduce a method that can learn binary and ternary weights during the training phase to facilitate hardware implementations of RNNs. As a result, using this approach replaces all multiply-accumulate operations by simple accumulations, bringing significant benefits to custom hardware in terms of silicon area and power consumption. On the software side, we evaluate the performance (in terms of accuracy) of our method using long short-term memories (LSTMs) on various sequential models including sequence classification and language modeling. We demonstrate that our method achieves competitive results on the aforementioned tasks while using binary/ternary weights during the runtime. On the hardware side, we present custom hardware for accelerating the recurrent computations of LSTMs with binary/ternary weights. Ultimately, we show that LSTMs with binary/ternary weights can achieve up to 12x memory saving and 10x inference speedup compared to the full-precision implementation on an ASIC platform.
Neural Networks Designing Neural Networks: Multi-Objective Hyper-Parameter Optimization
Nov 07, 2016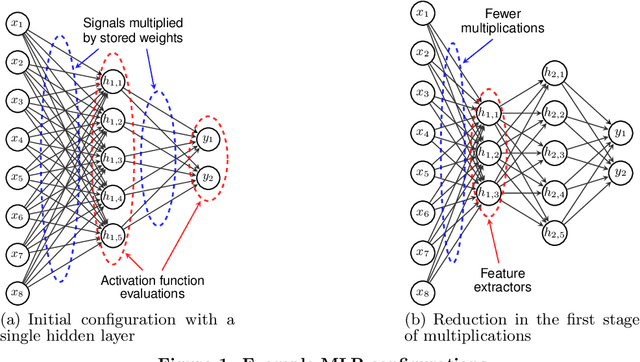

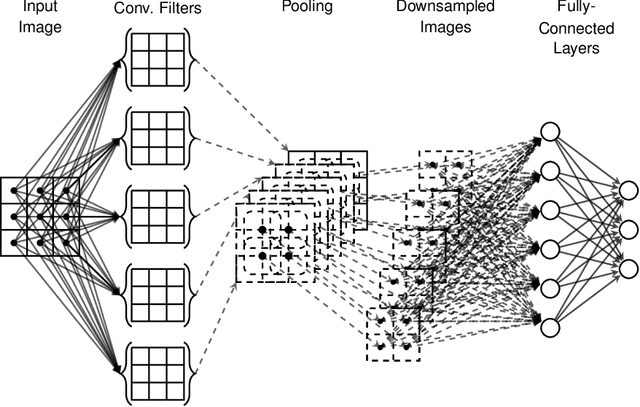
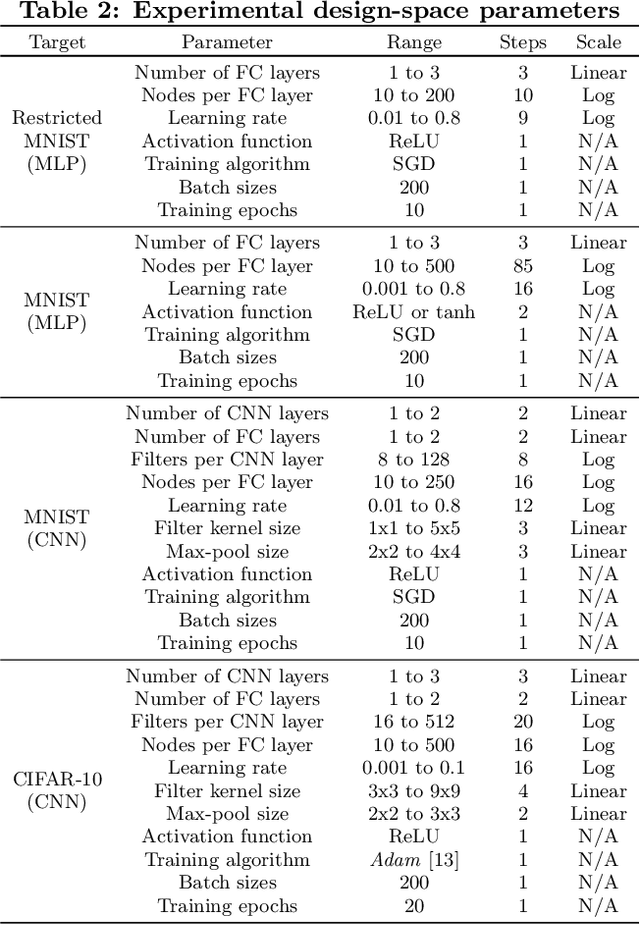
Artificial neural networks have gone through a recent rise in popularity, achieving state-of-the-art results in various fields, including image classification, speech recognition, and automated control. Both the performance and computational complexity of such models are heavily dependant on the design of characteristic hyper-parameters (e.g., number of hidden layers, nodes per layer, or choice of activation functions), which have traditionally been optimized manually. With machine learning penetrating low-power mobile and embedded areas, the need to optimize not only for performance (accuracy), but also for implementation complexity, becomes paramount. In this work, we present a multi-objective design space exploration method that reduces the number of solution networks trained and evaluated through response surface modelling. Given spaces which can easily exceed 1020 solutions, manually designing a near-optimal architecture is unlikely as opportunities to reduce network complexity, while maintaining performance, may be overlooked. This problem is exacerbated by the fact that hyper-parameters which perform well on specific datasets may yield sub-par results on others, and must therefore be designed on a per-application basis. In our work, machine learning is leveraged by training an artificial neural network to predict the performance of future candidate networks. The method is evaluated on the MNIST and CIFAR-10 image datasets, optimizing for both recognition accuracy and computational complexity. Experimental results demonstrate that the proposed method can closely approximate the Pareto-optimal front, while only exploring a small fraction of the design space.