 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSolving Hidden Monotone Variational Inequalities with Surrogate Losses
Nov 07, 2024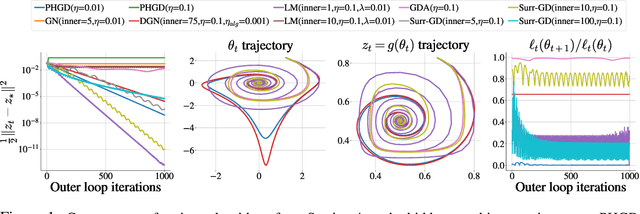
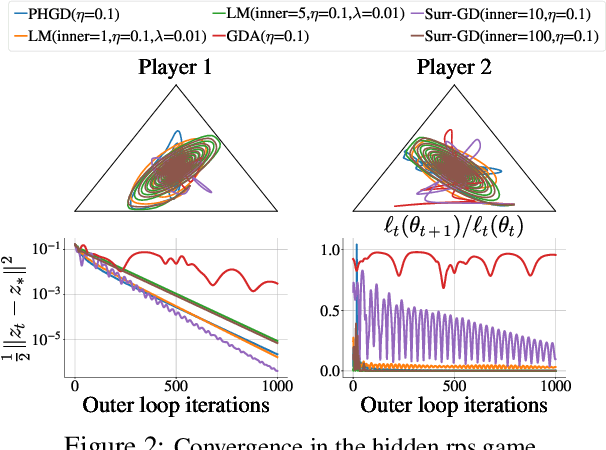
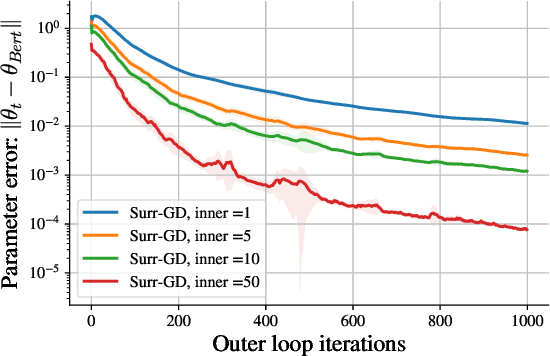
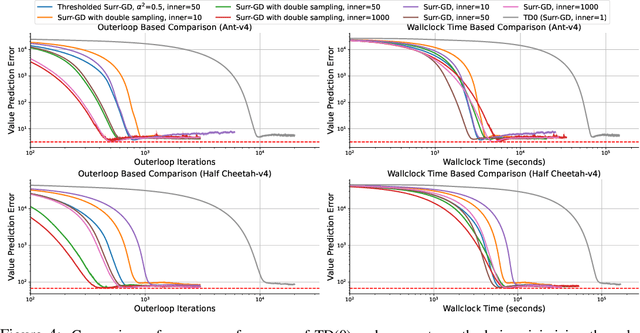
Deep learning has proven to be effective in a wide variety of loss minimization problems. However, many applications of interest, like minimizing projected Bellman error and min-max optimization, cannot be modelled as minimizing a scalar loss function but instead correspond to solving a variational inequality (VI) problem. This difference in setting has caused many practical challenges as naive gradient-based approaches from supervised learning tend to diverge and cycle in the VI case. In this work, we propose a principled surrogate-based approach compatible with deep learning to solve VIs. We show that our surrogate-based approach has three main benefits: (1) under assumptions that are realistic in practice (when hidden monotone structure is present, interpolation, and sufficient optimization of the surrogates), it guarantees convergence, (2) it provides a unifying perspective of existing methods, and (3) is amenable to existing deep learning optimizers like ADAM. Experimentally, we demonstrate our surrogate-based approach is effective in min-max optimization and minimizing projected Bellman error. Furthermore, in the deep reinforcement learning case, we propose a novel variant of TD(0) which is more compute and sample efficient.
Expected flow networks in stochastic environments and two-player zero-sum games
Oct 04, 2023



Generative flow networks (GFlowNets) are sequential sampling models trained to match a given distribution. GFlowNets have been successfully applied to various structured object generation tasks, sampling a diverse set of high-reward objects quickly. We propose expected flow networks (EFlowNets), which extend GFlowNets to stochastic environments. We show that EFlowNets outperform other GFlowNet formulations in stochastic tasks such as protein design. We then extend the concept of EFlowNets to adversarial environments, proposing adversarial flow networks (AFlowNets) for two-player zero-sum games. We show that AFlowNets learn to find above 80% of optimal moves in Connect-4 via self-play and outperform AlphaZero in tournaments.
Efficient Fine-Tuning of Compressed Language Models with Learners
Aug 03, 2022
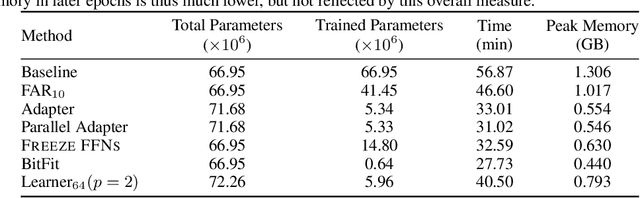

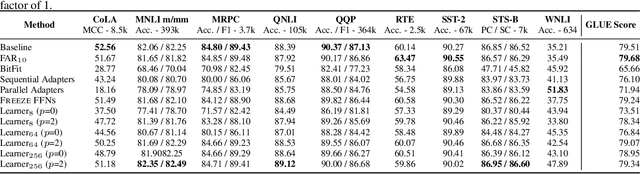
Fine-tuning BERT-based models is resource-intensive in memory, computation, and time. While many prior works aim to improve inference efficiency via compression techniques, e.g., pruning, these works do not explicitly address the computational challenges of training to downstream tasks. We introduce Learner modules and priming, novel methods for fine-tuning that exploit the overparameterization of pre-trained language models to gain benefits in convergence speed and resource utilization. Learner modules navigate the double bind of 1) training efficiently by fine-tuning a subset of parameters, and 2) training effectively by ensuring quick convergence and high metric scores. Our results on DistilBERT demonstrate that learners perform on par with or surpass the baselines. Learners train 7x fewer parameters than state-of-the-art methods on GLUE. On CoLA, learners fine-tune 20% faster, and have significantly lower resource utilization.
Efficient Fine-Tuning of BERT Models on the Edge
May 03, 2022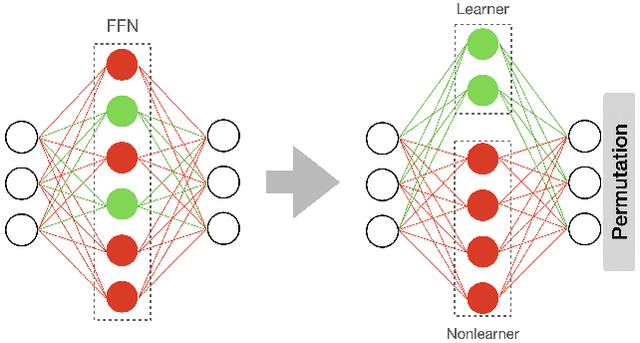
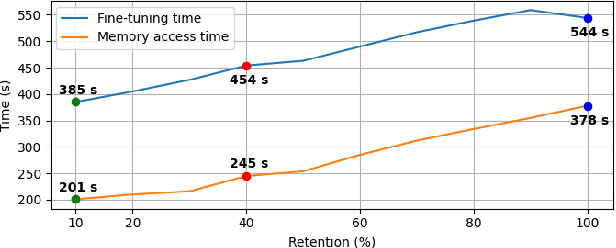

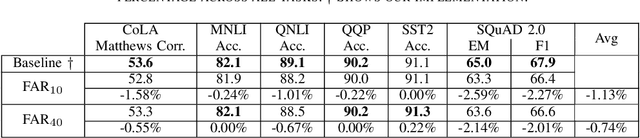
Resource-constrained devices are increasingly the deployment targets of machine learning applications. Static models, however, do not always suffice for dynamic environments. On-device training of models allows for quick adaptability to new scenarios. With the increasing size of deep neural networks, as noted with the likes of BERT and other natural language processing models, comes increased resource requirements, namely memory, computation, energy, and time. Furthermore, training is far more resource intensive than inference. Resource-constrained on-device learning is thus doubly difficult, especially with large BERT-like models. By reducing the memory usage of fine-tuning, pre-trained BERT models can become efficient enough to fine-tune on resource-constrained devices. We propose Freeze And Reconfigure (FAR), a memory-efficient training regime for BERT-like models that reduces the memory usage of activation maps during fine-tuning by avoiding unnecessary parameter updates. FAR reduces fine-tuning time on the DistilBERT model and CoLA dataset by 30%, and time spent on memory operations by 47%. More broadly, reductions in metric performance on the GLUE and SQuAD datasets are around 1% on average.