 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLogarithmic-time Schedules for Scaling Language Models with Momentum
Feb 05, 2026In practice, the hyperparameters $(β_1, β_2)$ and weight-decay $λ$ in AdamW are typically kept at fixed values. Is there any reason to do otherwise? We show that for large-scale language model training, the answer is yes: by exploiting the power-law structure of language data, one can design time-varying schedules for $(β_1, β_2, λ)$ that deliver substantial performance gains. We study logarithmic-time scheduling, in which the optimizer's gradient memory horizon grows with training time. Although naive variants of this are unstable, we show that suitable damping mechanisms restore stability while preserving the benefits of longer memory. Based on this, we present ADANA, an AdamW-like optimizer that couples log-time schedules with explicit damping to balance stability and performance. We empirically evaluate ADANA across transformer scalings (45M to 2.6B parameters), comparing against AdamW, Muon, and AdEMAMix. When properly tuned, ADANA achieves up to 40% compute efficiency relative to a tuned AdamW, with gains that persist--and even improve--as model scale increases. We further show that similar benefits arise when applying logarithmic-time scheduling to AdEMAMix, and that logarithmic-time weight-decay alone can yield significant improvements. Finally, we present variants of ADANA that mitigate potential failure modes and improve robustness.
Dimension-adapted Momentum Outscales SGD
May 22, 2025We investigate scaling laws for stochastic momentum algorithms with small batch on the power law random features model, parameterized by data complexity, target complexity, and model size. When trained with a stochastic momentum algorithm, our analysis reveals four distinct loss curve shapes determined by varying data-target complexities. While traditional stochastic gradient descent with momentum (SGD-M) yields identical scaling law exponents to SGD, dimension-adapted Nesterov acceleration (DANA) improves these exponents by scaling momentum hyperparameters based on model size and data complexity. This outscaling phenomenon, which also improves compute-optimal scaling behavior, is achieved by DANA across a broad range of data and target complexities, while traditional methods fall short. Extensive experiments on high-dimensional synthetic quadratics validate our theoretical predictions and large-scale text experiments with LSTMs show DANA's improved loss exponents over SGD hold in a practical setting.
LLM-Safety Evaluations Lack Robustness
Mar 04, 2025In this paper, we argue that current safety alignment research efforts for large language models are hindered by many intertwined sources of noise, such as small datasets, methodological inconsistencies, and unreliable evaluation setups. This can, at times, make it impossible to evaluate and compare attacks and defenses fairly, thereby slowing progress. We systematically analyze the LLM safety evaluation pipeline, covering dataset curation, optimization strategies for automated red-teaming, response generation, and response evaluation using LLM judges. At each stage, we identify key issues and highlight their practical impact. We also propose a set of guidelines for reducing noise and bias in evaluations of future attack and defense papers. Lastly, we offer an opposing perspective, highlighting practical reasons for existing limitations. We believe that addressing the outlined problems in future research will improve the field's ability to generate easily comparable results and make measurable progress.
A generative approach to LLM harmfulness detection with special red flag tokens
Feb 22, 2025Most safety training methods for large language models (LLMs) based on fine-tuning rely on dramatically changing the output distribution of the model when faced with a harmful request, shifting it from an unsafe answer to a refusal to respond. These methods inherently compromise model capabilities and might make auto-regressive models vulnerable to attacks that make likely an initial token of affirmative response. To avoid that, we propose to expand the model's vocabulary with a special token we call red flag token (<rf>) and propose to fine-tune the model to generate this token at any time harmful content is generated or about to be generated. This novel safety training method effectively augments LLMs into generative classifiers of harmfulness at all times during the conversation. This method offers several advantages: it enables the model to explicitly learn the concept of harmfulness while marginally affecting the generated distribution, thus maintaining the model's utility. It also evaluates each generated answer rather than just the input prompt and provides a stronger defence against sampling-based attacks. In addition, it simplifies the evaluation of the model's robustness and reduces correlated failures when combined with a classifier. We further show an increased robustness to long contexts, and supervised fine-tuning attacks.
Adversarial Alignment for LLMs Requires Simpler, Reproducible, and More Measurable Objectives
Feb 17, 2025Misaligned research objectives have considerably hindered progress in adversarial robustness research over the past decade. For instance, an extensive focus on optimizing target metrics, while neglecting rigorous standardized evaluation, has led researchers to pursue ad-hoc heuristic defenses that were seemingly effective. Yet, most of these were exposed as flawed by subsequent evaluations, ultimately contributing little measurable progress to the field. In this position paper, we illustrate that current research on the robustness of large language models (LLMs) risks repeating past patterns with potentially worsened real-world implications. To address this, we argue that realigned objectives are necessary for meaningful progress in adversarial alignment. To this end, we build on established cybersecurity taxonomy to formally define differences between past and emerging threat models that apply to LLMs. Using this framework, we illustrate that progress requires disentangling adversarial alignment into addressable sub-problems and returning to core academic principles, such as measureability, reproducibility, and comparability. Although the field presents significant challenges, the fresh start on adversarial robustness offers the unique opportunity to build on past experience while avoiding previous mistakes.
Tight Lower Bounds and Improved Convergence in Performative Prediction
Dec 04, 2024Performative prediction is a framework accounting for the shift in the data distribution induced by the prediction of a model deployed in the real world. Ensuring rapid convergence to a stable solution where the data distribution remains the same after the model deployment is crucial, especially in evolving environments. This paper extends the Repeated Risk Minimization (RRM) framework by utilizing historical datasets from previous retraining snapshots, yielding a class of algorithms that we call Affine Risk Minimizers and enabling convergence to a performatively stable point for a broader class of problems. We introduce a new upper bound for methods that use only the final iteration of the dataset and prove for the first time the tightness of both this new bound and the previous existing bounds within the same regime. We also prove that utilizing historical datasets can surpass the lower bound for last iterate RRM, and empirically observe faster convergence to the stable point on various performative prediction benchmarks. We offer at the same time the first lower bound analysis for RRM within the class of Affine Risk Minimizers, quantifying the potential improvements in convergence speed that could be achieved with other variants in our framework.
Solving Hidden Monotone Variational Inequalities with Surrogate Losses
Nov 07, 2024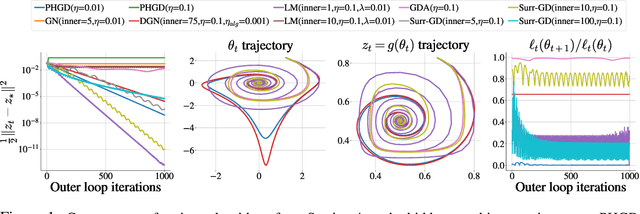
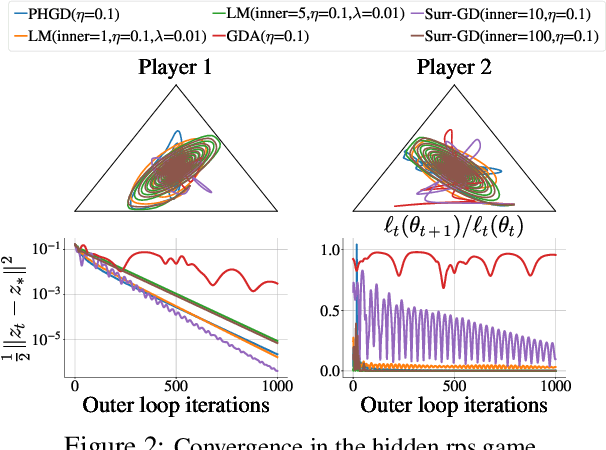
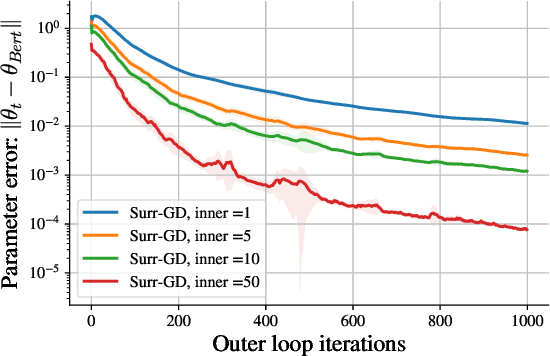
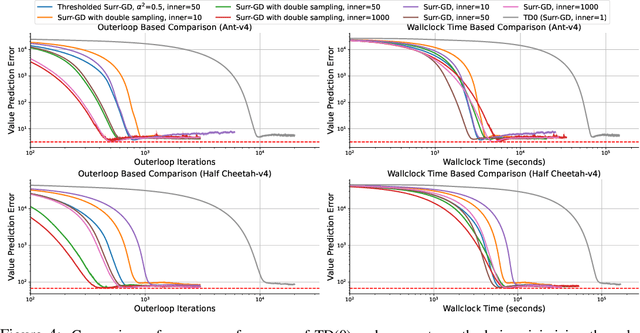
Deep learning has proven to be effective in a wide variety of loss minimization problems. However, many applications of interest, like minimizing projected Bellman error and min-max optimization, cannot be modelled as minimizing a scalar loss function but instead correspond to solving a variational inequality (VI) problem. This difference in setting has caused many practical challenges as naive gradient-based approaches from supervised learning tend to diverge and cycle in the VI case. In this work, we propose a principled surrogate-based approach compatible with deep learning to solve VIs. We show that our surrogate-based approach has three main benefits: (1) under assumptions that are realistic in practice (when hidden monotone structure is present, interpolation, and sufficient optimization of the surrogates), it guarantees convergence, (2) it provides a unifying perspective of existing methods, and (3) is amenable to existing deep learning optimizers like ADAM. Experimentally, we demonstrate our surrogate-based approach is effective in min-max optimization and minimizing projected Bellman error. Furthermore, in the deep reinforcement learning case, we propose a novel variant of TD(0) which is more compute and sample efficient.
Investigating the Benefits of Nonlinear Action Maps in Data-Driven Teleoperation
Oct 28, 2024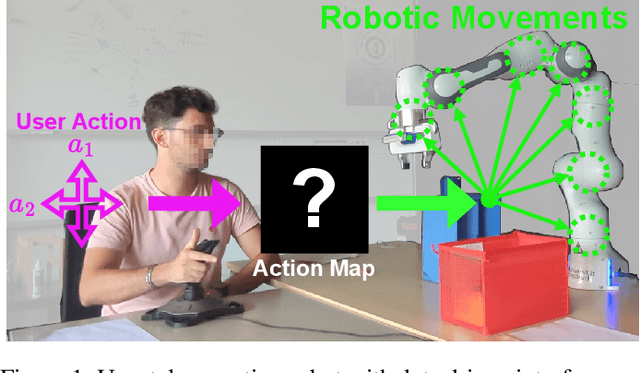

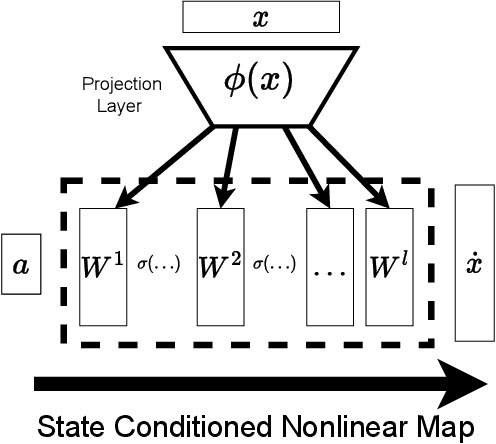

As robots become more common for both able-bodied individuals and those living with a disability, it is increasingly important that lay people be able to drive multi-degree-of-freedom platforms with low-dimensional controllers. One approach is to use state-conditioned action mapping methods to learn mappings between low-dimensional controllers and high DOF manipulators -- prior research suggests these mappings can simplify the teleoperation experience for users. Recent works suggest that neural networks predicting a local linear function are superior to the typical end-to-end multi-layer perceptrons because they allow users to more easily undo actions, providing more control over the system. However, local linear models assume actions exist on a linear subspace and may not capture nuanced actions in training data. We observe that the benefit of these mappings is being an odd function concerning user actions, and propose end-to-end nonlinear action maps which achieve this property. Unfortunately, our experiments show that such modifications offer minimal advantages over previous solutions. We find that nonlinear odd functions behave linearly for most of the control space, suggesting architecture structure improvements are not the primary factor in data-driven teleoperation. Our results suggest other avenues, such as data augmentation techniques and analysis of human behavior, are necessary for action maps to become practical in real-world applications, such as in assistive robotics to improve the quality of life of people living with w disability.
General Causal Imputation via Synthetic Interventions
Oct 28, 2024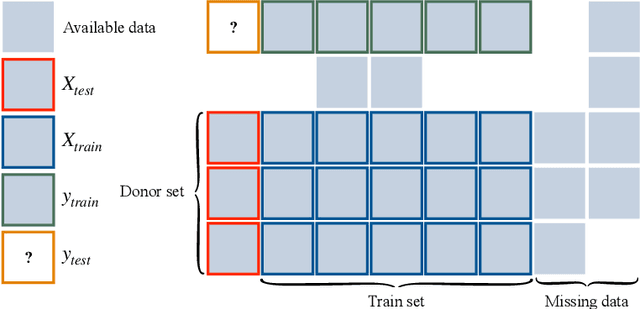
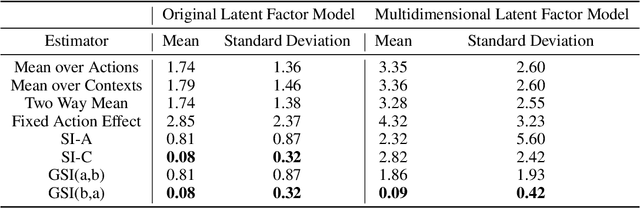
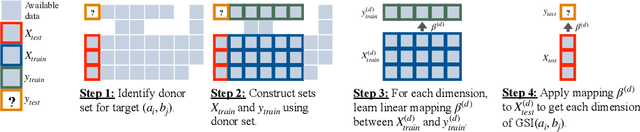
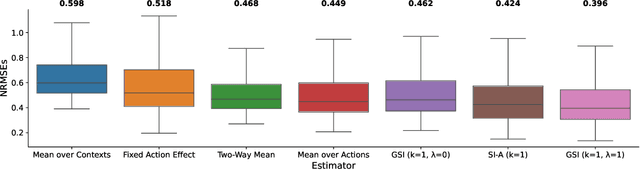
Given two sets of elements (such as cell types and drug compounds), researchers typically only have access to a limited subset of their interactions. The task of causal imputation involves using this subset to predict unobserved interactions. Squires et al. (2022) have proposed two estimators for this task based on the synthetic interventions (SI) estimator: SI-A (for actions) and SI-C (for contexts). We extend their work and introduce a novel causal imputation estimator, generalized synthetic interventions (GSI). We prove the identifiability of this estimator for data generated from a more complex latent factor model. On synthetic and real data we show empirically that it recovers or outperforms their estimators.
Performative Prediction on Games and Mechanism Design
Aug 09, 2024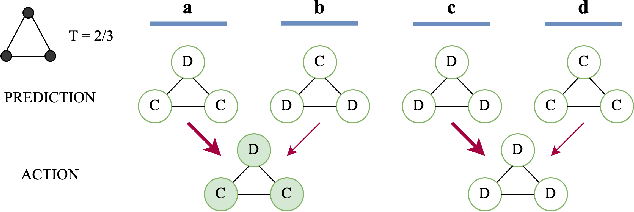
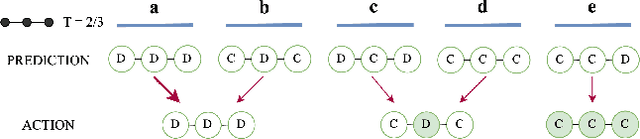
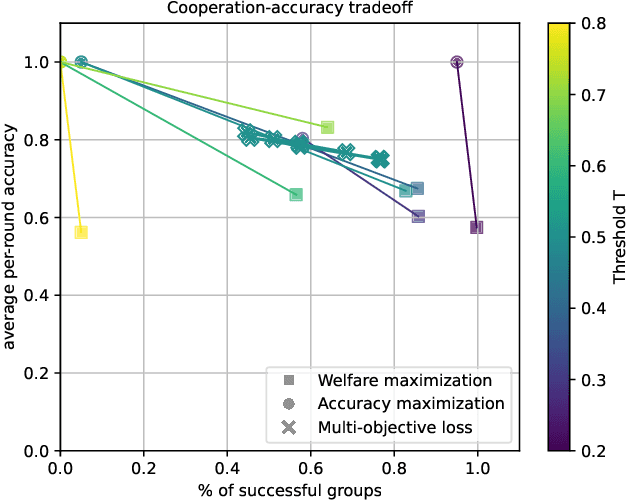
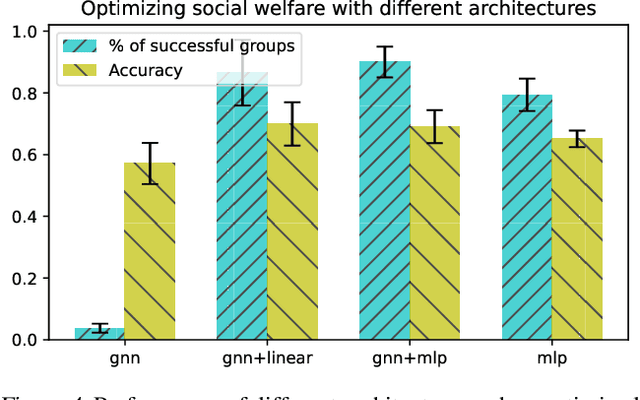
Predictions often influence the reality which they aim to predict, an effect known as performativity. Existing work focuses on accuracy maximization under this effect, but model deployment may have important unintended impacts, especially in multiagent scenarios. In this work, we investigate performative prediction in a concrete game-theoretic setting where social welfare is an alternative objective to accuracy maximization. We explore a collective risk dilemma scenario where maximising accuracy can negatively impact social welfare, when predicting collective behaviours. By assuming knowledge of a Bayesian agent behavior model, we then show how to achieve better trade-offs and use them for mechanism design.