 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Alignment for LLMs Requires Simpler, Reproducible, and More Measurable Objectives
Feb 17, 2025Misaligned research objectives have considerably hindered progress in adversarial robustness research over the past decade. For instance, an extensive focus on optimizing target metrics, while neglecting rigorous standardized evaluation, has led researchers to pursue ad-hoc heuristic defenses that were seemingly effective. Yet, most of these were exposed as flawed by subsequent evaluations, ultimately contributing little measurable progress to the field. In this position paper, we illustrate that current research on the robustness of large language models (LLMs) risks repeating past patterns with potentially worsened real-world implications. To address this, we argue that realigned objectives are necessary for meaningful progress in adversarial alignment. To this end, we build on established cybersecurity taxonomy to formally define differences between past and emerging threat models that apply to LLMs. Using this framework, we illustrate that progress requires disentangling adversarial alignment into addressable sub-problems and returning to core academic principles, such as measureability, reproducibility, and comparability. Although the field presents significant challenges, the fresh start on adversarial robustness offers the unique opportunity to build on past experience while avoiding previous mistakes.
Provably Reliable Conformal Prediction Sets in the Presence of Data Poisoning
Oct 13, 2024Conformal prediction provides model-agnostic and distribution-free uncertainty quantification through prediction sets that are guaranteed to include the ground truth with any user-specified probability. Yet, conformal prediction is not reliable under poisoning attacks where adversaries manipulate both training and calibration data, which can significantly alter prediction sets in practice. As a solution, we propose reliable prediction sets (RPS): the first efficient method for constructing conformal prediction sets with provable reliability guarantees under poisoning. To ensure reliability under training poisoning, we introduce smoothed score functions that reliably aggregate predictions of classifiers trained on distinct partitions of the training data. To ensure reliability under calibration poisoning, we construct multiple prediction sets, each calibrated on distinct subsets of the calibration data. We then aggregate them into a majority prediction set, which includes a class only if it appears in a majority of the individual sets. Both proposed aggregations mitigate the influence of datapoints in the training and calibration data on the final prediction set. We experimentally validate our approach on image classification tasks, achieving strong reliability while maintaining utility and preserving coverage on clean data. Overall, our approach represents an important step towards more trustworthy uncertainty quantification in the presence of data poisoning.
A Probabilistic Perspective on Unlearning and Alignment for Large Language Models
Oct 04, 2024Comprehensive evaluation of Large Language Models (LLMs) is an open research problem. Existing evaluations rely on deterministic point estimates generated via greedy decoding. However, we find that deterministic evaluations fail to capture the whole output distribution of a model, yielding inaccurate estimations of model capabilities. This is particularly problematic in critical contexts such as unlearning and alignment, where precise model evaluations are crucial. To remedy this, we introduce the first formal probabilistic evaluation framework in LLMs. Namely, we derive novel metrics with high-probability guarantees concerning the output distribution of a model. Our metrics are application-independent and allow practitioners to make more reliable estimates about model capabilities before deployment. Through a case study focused on unlearning, we reveal that deterministic evaluations falsely indicate successful unlearning, whereas our probabilistic evaluations demonstrate that most if not all of the supposedly unlearned information remains accessible in these models. Additionally, we propose a novel unlearning loss based on entropy optimization and adaptive temperature scaling, which significantly improves unlearning in probabilistic settings on recent benchmarks. Our proposed shift from point estimates to probabilistic evaluations of output distributions represents an important step toward comprehensive evaluations of LLMs. https://github.com/yascho/probabilistic-unlearning
(Provable) Adversarial Robustness for Group Equivariant Tasks: Graphs, Point Clouds, Molecules, and More
Dec 05, 2023


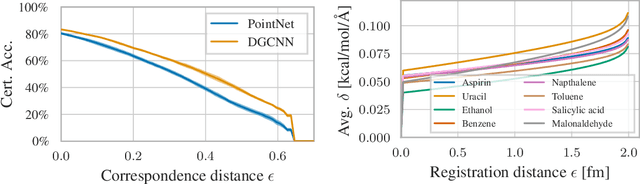
A machine learning model is traditionally considered robust if its prediction remains (almost) constant under input perturbations with small norm. However, real-world tasks like molecular property prediction or point cloud segmentation have inherent equivariances, such as rotation or permutation equivariance. In such tasks, even perturbations with large norm do not necessarily change an input's semantic content. Furthermore, there are perturbations for which a model's prediction explicitly needs to change. For the first time, we propose a sound notion of adversarial robustness that accounts for task equivariance. We then demonstrate that provable robustness can be achieved by (1) choosing a model that matches the task's equivariances (2) certifying traditional adversarial robustness. Certification methods are, however, unavailable for many models, such as those with continuous equivariances. We close this gap by developing the framework of equivariance-preserving randomized smoothing, which enables architecture-agnostic certification. We additionally derive the first architecture-specific graph edit distance certificates, i.e. sound robustness guarantees for isomorphism equivariant tasks like node classification. Overall, a sound notion of robustness is an important prerequisite for future work at the intersection of robust and geometric machine learning.
Hierarchical Randomized Smoothing
Oct 24, 2023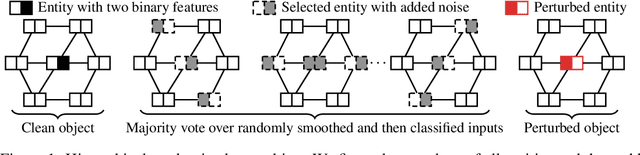
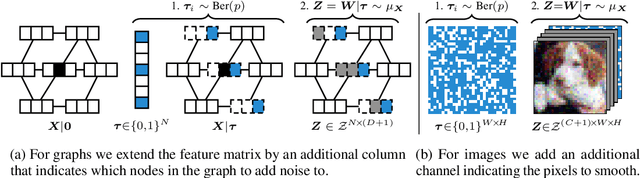
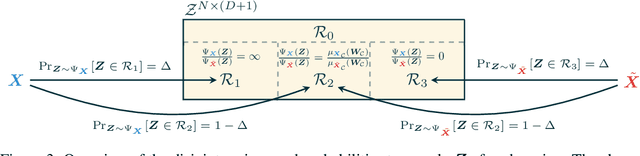
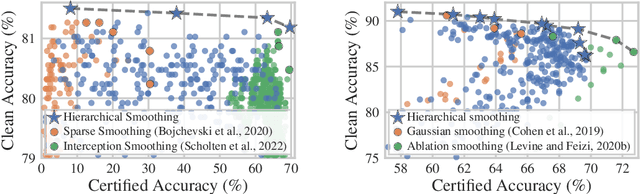
Real-world data is complex and often consists of objects that can be decomposed into multiple entities (e.g. images into pixels, graphs into interconnected nodes). Randomized smoothing is a powerful framework for making models provably robust against small changes to their inputs - by guaranteeing robustness of the majority vote when randomly adding noise before classification. Yet, certifying robustness on such complex data via randomized smoothing is challenging when adversaries do not arbitrarily perturb entire objects (e.g. images) but only a subset of their entities (e.g. pixels). As a solution, we introduce hierarchical randomized smoothing: We partially smooth objects by adding random noise only on a randomly selected subset of their entities. By adding noise in a more targeted manner than existing methods we obtain stronger robustness guarantees while maintaining high accuracy. We initialize hierarchical smoothing using different noising distributions, yielding novel robustness certificates for discrete and continuous domains. We experimentally demonstrate the importance of hierarchical smoothing in image and node classification, where it yields superior robustness-accuracy trade-offs. Overall, hierarchical smoothing is an important contribution towards models that are both - certifiably robust to perturbations and accurate.
Assessing Robustness via Score-Based Adversarial Image Generation
Oct 06, 2023

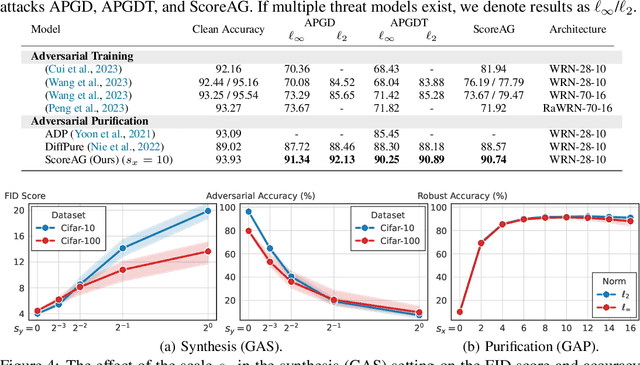
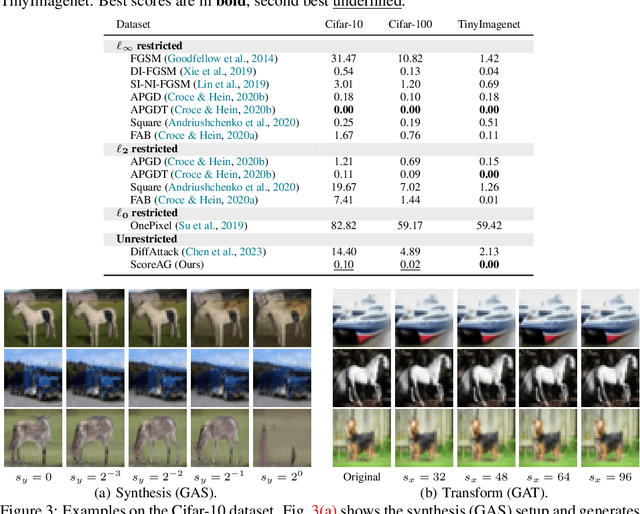
Most adversarial attacks and defenses focus on perturbations within small $\ell_p$-norm constraints. However, $\ell_p$ threat models cannot capture all relevant semantic-preserving perturbations, and hence, the scope of robustness evaluations is limited. In this work, we introduce Score-Based Adversarial Generation (ScoreAG), a novel framework that leverages the advancements in score-based generative models to generate adversarial examples beyond $\ell_p$-norm constraints, so-called unrestricted adversarial examples, overcoming their limitations. Unlike traditional methods, ScoreAG maintains the core semantics of images while generating realistic adversarial examples, either by transforming existing images or synthesizing new ones entirely from scratch. We further exploit the generative capability of ScoreAG to purify images, empirically enhancing the robustness of classifiers. Our extensive empirical evaluation demonstrates that ScoreAG matches the performance of state-of-the-art attacks and defenses across multiple benchmarks. This work highlights the importance of investigating adversarial examples bounded by semantics rather than $\ell_p$-norm constraints. ScoreAG represents an important step towards more encompassing robustness assessments.
Expressivity of Graph Neural Networks Through the Lens of Adversarial Robustness
Aug 16, 2023
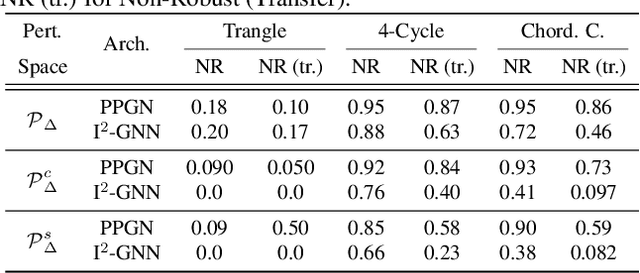
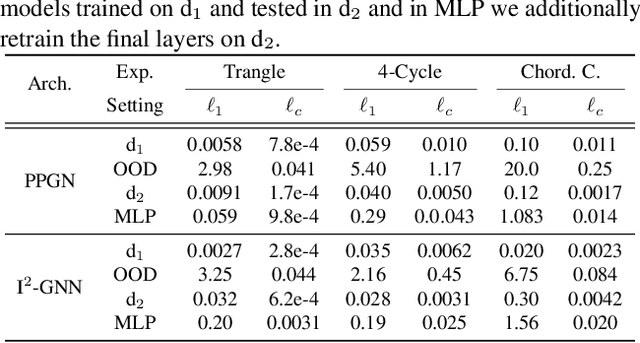
We perform the first adversarial robustness study into Graph Neural Networks (GNNs) that are provably more powerful than traditional Message Passing Neural Networks (MPNNs). In particular, we use adversarial robustness as a tool to uncover a significant gap between their theoretically possible and empirically achieved expressive power. To do so, we focus on the ability of GNNs to count specific subgraph patterns, which is an established measure of expressivity, and extend the concept of adversarial robustness to this task. Based on this, we develop efficient adversarial attacks for subgraph counting and show that more powerful GNNs fail to generalize even to small perturbations to the graph's structure. Expanding on this, we show that such architectures also fail to count substructures on out-of-distribution graphs.
Randomized Message-Interception Smoothing: Gray-box Certificates for Graph Neural Networks
Jan 05, 2023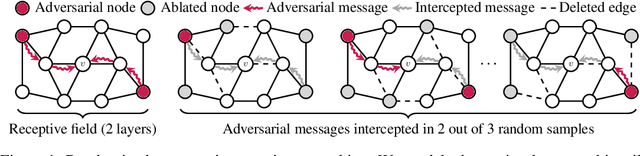
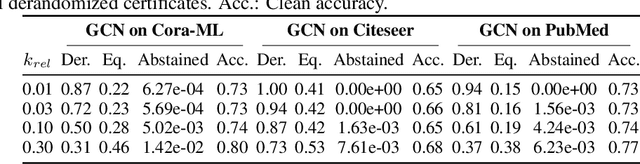
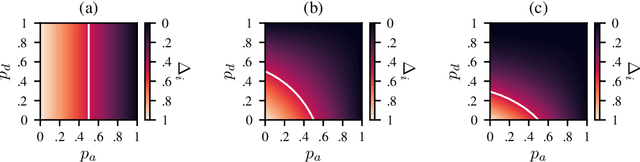
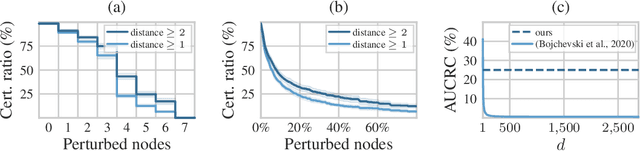
Randomized smoothing is one of the most promising frameworks for certifying the adversarial robustness of machine learning models, including Graph Neural Networks (GNNs). Yet, existing randomized smoothing certificates for GNNs are overly pessimistic since they treat the model as a black box, ignoring the underlying architecture. To remedy this, we propose novel gray-box certificates that exploit the message-passing principle of GNNs: We randomly intercept messages and carefully analyze the probability that messages from adversarially controlled nodes reach their target nodes. Compared to existing certificates, we certify robustness to much stronger adversaries that control entire nodes in the graph and can arbitrarily manipulate node features. Our certificates provide stronger guarantees for attacks at larger distances, as messages from farther-away nodes are more likely to get intercepted. We demonstrate the effectiveness of our method on various models and datasets. Since our gray-box certificates consider the underlying graph structure, we can significantly improve certifiable robustness by applying graph sparsification.