 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-Safety Evaluations Lack Robustness
Mar 04, 2025In this paper, we argue that current safety alignment research efforts for large language models are hindered by many intertwined sources of noise, such as small datasets, methodological inconsistencies, and unreliable evaluation setups. This can, at times, make it impossible to evaluate and compare attacks and defenses fairly, thereby slowing progress. We systematically analyze the LLM safety evaluation pipeline, covering dataset curation, optimization strategies for automated red-teaming, response generation, and response evaluation using LLM judges. At each stage, we identify key issues and highlight their practical impact. We also propose a set of guidelines for reducing noise and bias in evaluations of future attack and defense papers. Lastly, we offer an opposing perspective, highlighting practical reasons for existing limitations. We believe that addressing the outlined problems in future research will improve the field's ability to generate easily comparable results and make measurable progress.
A generative approach to LLM harmfulness detection with special red flag tokens
Feb 22, 2025Most safety training methods for large language models (LLMs) based on fine-tuning rely on dramatically changing the output distribution of the model when faced with a harmful request, shifting it from an unsafe answer to a refusal to respond. These methods inherently compromise model capabilities and might make auto-regressive models vulnerable to attacks that make likely an initial token of affirmative response. To avoid that, we propose to expand the model's vocabulary with a special token we call red flag token (<rf>) and propose to fine-tune the model to generate this token at any time harmful content is generated or about to be generated. This novel safety training method effectively augments LLMs into generative classifiers of harmfulness at all times during the conversation. This method offers several advantages: it enables the model to explicitly learn the concept of harmfulness while marginally affecting the generated distribution, thus maintaining the model's utility. It also evaluates each generated answer rather than just the input prompt and provides a stronger defence against sampling-based attacks. In addition, it simplifies the evaluation of the model's robustness and reduces correlated failures when combined with a classifier. We further show an increased robustness to long contexts, and supervised fine-tuning attacks.
Adversarial Alignment for LLMs Requires Simpler, Reproducible, and More Measurable Objectives
Feb 17, 2025Misaligned research objectives have considerably hindered progress in adversarial robustness research over the past decade. For instance, an extensive focus on optimizing target metrics, while neglecting rigorous standardized evaluation, has led researchers to pursue ad-hoc heuristic defenses that were seemingly effective. Yet, most of these were exposed as flawed by subsequent evaluations, ultimately contributing little measurable progress to the field. In this position paper, we illustrate that current research on the robustness of large language models (LLMs) risks repeating past patterns with potentially worsened real-world implications. To address this, we argue that realigned objectives are necessary for meaningful progress in adversarial alignment. To this end, we build on established cybersecurity taxonomy to formally define differences between past and emerging threat models that apply to LLMs. Using this framework, we illustrate that progress requires disentangling adversarial alignment into addressable sub-problems and returning to core academic principles, such as measureability, reproducibility, and comparability. Although the field presents significant challenges, the fresh start on adversarial robustness offers the unique opportunity to build on past experience while avoiding previous mistakes.
Asynchronous RLHF: Faster and More Efficient Off-Policy RL for Language Models
Oct 23, 2024



The dominant paradigm for RLHF is online and on-policy RL: synchronously generating from the large language model (LLM) policy, labelling with a reward model, and learning using feedback on the LLM's own outputs. While performant, this paradigm is computationally inefficient. Inspired by classical deep RL literature, we propose separating generation and learning in RLHF. This enables asynchronous generation of new samples while simultaneously training on old samples, leading to faster training and more compute-optimal scaling. However, asynchronous training relies on an underexplored regime, online but off-policy RLHF: learning on samples from previous iterations of our model. To understand the challenges in this regime, we investigate a fundamental question: how much off-policyness can we tolerate for asynchronous training to speed up learning but maintain performance? Among several RLHF algorithms we tested, we find that online DPO is most robust to off-policy data, and robustness increases with the scale of the policy model. We study further compute optimizations for asynchronous RLHF but find that they come at a performance cost, giving rise to a trade-off. Finally, we verify the scalability of asynchronous RLHF by training LLaMA 3.1 8B on an instruction-following task 40% faster than a synchronous run while matching final performance.
Efficient Adversarial Training in LLMs with Continuous Attacks
May 24, 2024



Large language models (LLMs) are vulnerable to adversarial attacks that can bypass their safety guardrails. In many domains, adversarial training has proven to be one of the most promising methods to reliably improve robustness against such attacks. Yet, in the context of LLMs, current methods for adversarial training are hindered by the high computational costs required to perform discrete adversarial attacks at each training iteration. We address this problem by instead calculating adversarial attacks in the continuous embedding space of the LLM, which is orders of magnitudes more efficient. We propose a fast adversarial training algorithm (C-AdvUL) composed of two losses: the first makes the model robust on continuous embedding attacks computed on an adversarial behaviour dataset; the second ensures the usefulness of the final model by fine-tuning on utility data. Moreover, we introduce C-AdvIPO, an adversarial variant of IPO that does not require utility data for adversarially robust alignment. Our empirical evaluation on four models from different families (Gemma, Phi3, Mistral, Zephyr) and at different scales (2B, 3.8B, 7B) shows that both algorithms substantially enhance LLM robustness against discrete attacks (GCG, AutoDAN, PAIR), while maintaining utility. Our results demonstrate that robustness to continuous perturbations can extrapolate to discrete threat models. Thereby, we present a path toward scalable adversarial training algorithms for robustly aligning LLMs.
Soft Prompt Threats: Attacking Safety Alignment and Unlearning in Open-Source LLMs through the Embedding Space
Feb 14, 2024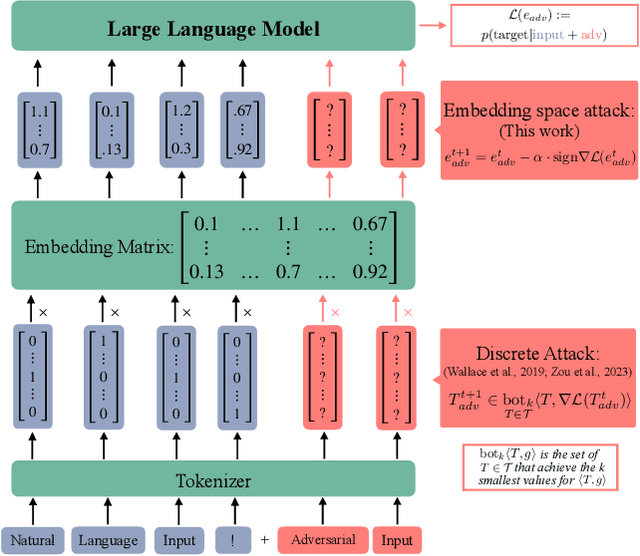
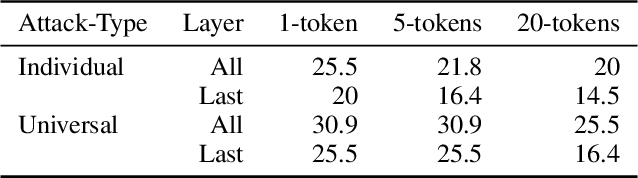

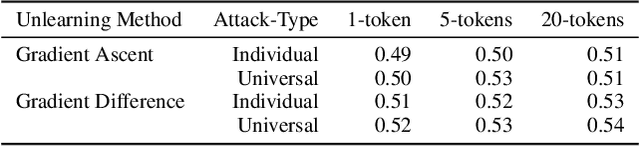
Current research in adversarial robustness of LLMs focuses on discrete input manipulations in the natural language space, which can be directly transferred to closed-source models. However, this approach neglects the steady progression of open-source models. As open-source models advance in capability, ensuring their safety also becomes increasingly imperative. Yet, attacks tailored to open-source LLMs that exploit full model access remain largely unexplored. We address this research gap and propose the embedding space attack, which directly attacks the continuous embedding representation of input tokens. We find that embedding space attacks circumvent model alignments and trigger harmful behaviors more efficiently than discrete attacks or model fine-tuning. Furthermore, we present a novel threat model in the context of unlearning and show that embedding space attacks can extract supposedly deleted information from unlearned LLMs across multiple datasets and models. Our findings highlight embedding space attacks as an important threat model in open-source LLMs. Trigger Warning: the appendix contains LLM-generated text with violence and harassment.
In-Context Learning Can Re-learn Forbidden Tasks
Feb 08, 2024Despite significant investment into safety training, large language models (LLMs) deployed in the real world still suffer from numerous vulnerabilities. One perspective on LLM safety training is that it algorithmically forbids the model from answering toxic or harmful queries. To assess the effectiveness of safety training, in this work, we study forbidden tasks, i.e., tasks the model is designed to refuse to answer. Specifically, we investigate whether in-context learning (ICL) can be used to re-learn forbidden tasks despite the explicit fine-tuning of the model to refuse them. We first examine a toy example of refusing sentiment classification to demonstrate the problem. Then, we use ICL on a model fine-tuned to refuse to summarise made-up news articles. Finally, we investigate whether ICL can undo safety training, which could represent a major security risk. For the safety task, we look at Vicuna-7B, Starling-7B, and Llama2-7B. We show that the attack works out-of-the-box on Starling-7B and Vicuna-7B but fails on Llama2-7B. Finally, we propose an ICL attack that uses the chat template tokens like a prompt injection attack to achieve a better attack success rate on Vicuna-7B and Starling-7B. Trigger Warning: the appendix contains LLM-generated text with violence, suicide, and misinformation.