 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA generative approach to LLM harmfulness detection with special red flag tokens
Feb 22, 2025Most safety training methods for large language models (LLMs) based on fine-tuning rely on dramatically changing the output distribution of the model when faced with a harmful request, shifting it from an unsafe answer to a refusal to respond. These methods inherently compromise model capabilities and might make auto-regressive models vulnerable to attacks that make likely an initial token of affirmative response. To avoid that, we propose to expand the model's vocabulary with a special token we call red flag token (<rf>) and propose to fine-tune the model to generate this token at any time harmful content is generated or about to be generated. This novel safety training method effectively augments LLMs into generative classifiers of harmfulness at all times during the conversation. This method offers several advantages: it enables the model to explicitly learn the concept of harmfulness while marginally affecting the generated distribution, thus maintaining the model's utility. It also evaluates each generated answer rather than just the input prompt and provides a stronger defence against sampling-based attacks. In addition, it simplifies the evaluation of the model's robustness and reduces correlated failures when combined with a classifier. We further show an increased robustness to long contexts, and supervised fine-tuning attacks.
Learning diverse attacks on large language models for robust red-teaming and safety tuning
May 28, 2024Red-teaming, or identifying prompts that elicit harmful responses, is a critical step in ensuring the safe and responsible deployment of large language models (LLMs). Developing effective protection against many modes of attack prompts requires discovering diverse attacks. Automated red-teaming typically uses reinforcement learning to fine-tune an attacker language model to generate prompts that elicit undesirable responses from a target LLM, as measured, for example, by an auxiliary toxicity classifier. We show that even with explicit regularization to favor novelty and diversity, existing approaches suffer from mode collapse or fail to generate effective attacks. As a flexible and probabilistically principled alternative, we propose to use GFlowNet fine-tuning, followed by a secondary smoothing phase, to train the attacker model to generate diverse and effective attack prompts. We find that the attacks generated by our method are effective against a wide range of target LLMs, both with and without safety tuning, and transfer well between target LLMs. Finally, we demonstrate that models safety-tuned using a dataset of red-teaming prompts generated by our method are robust to attacks from other RL-based red-teaming approaches.
Soft Prompt Threats: Attacking Safety Alignment and Unlearning in Open-Source LLMs through the Embedding Space
Feb 14, 2024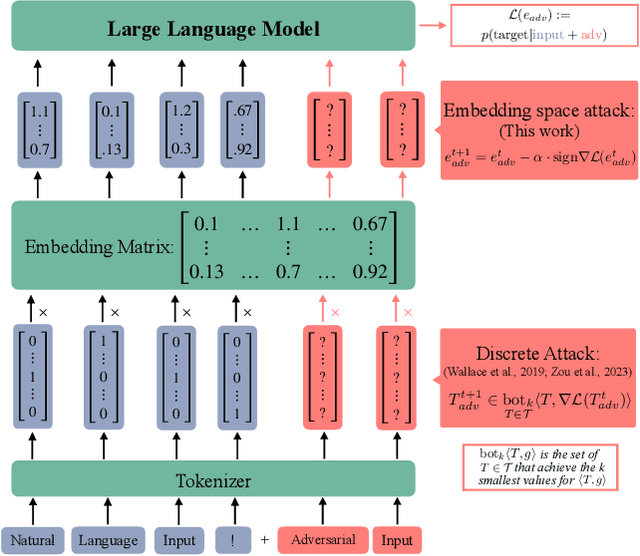
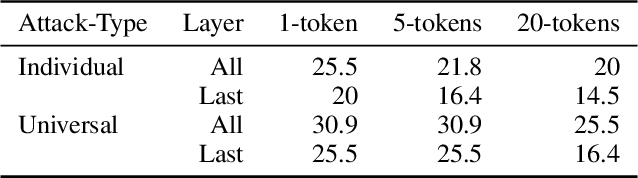

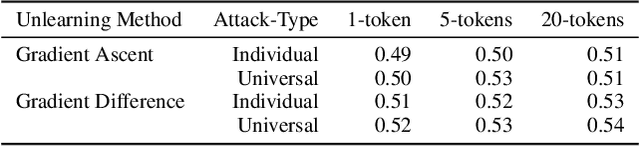
Current research in adversarial robustness of LLMs focuses on discrete input manipulations in the natural language space, which can be directly transferred to closed-source models. However, this approach neglects the steady progression of open-source models. As open-source models advance in capability, ensuring their safety also becomes increasingly imperative. Yet, attacks tailored to open-source LLMs that exploit full model access remain largely unexplored. We address this research gap and propose the embedding space attack, which directly attacks the continuous embedding representation of input tokens. We find that embedding space attacks circumvent model alignments and trigger harmful behaviors more efficiently than discrete attacks or model fine-tuning. Furthermore, we present a novel threat model in the context of unlearning and show that embedding space attacks can extract supposedly deleted information from unlearned LLMs across multiple datasets and models. Our findings highlight embedding space attacks as an important threat model in open-source LLMs. Trigger Warning: the appendix contains LLM-generated text with violence and harassment.
In-Context Learning Can Re-learn Forbidden Tasks
Feb 08, 2024Despite significant investment into safety training, large language models (LLMs) deployed in the real world still suffer from numerous vulnerabilities. One perspective on LLM safety training is that it algorithmically forbids the model from answering toxic or harmful queries. To assess the effectiveness of safety training, in this work, we study forbidden tasks, i.e., tasks the model is designed to refuse to answer. Specifically, we investigate whether in-context learning (ICL) can be used to re-learn forbidden tasks despite the explicit fine-tuning of the model to refuse them. We first examine a toy example of refusing sentiment classification to demonstrate the problem. Then, we use ICL on a model fine-tuned to refuse to summarise made-up news articles. Finally, we investigate whether ICL can undo safety training, which could represent a major security risk. For the safety task, we look at Vicuna-7B, Starling-7B, and Llama2-7B. We show that the attack works out-of-the-box on Starling-7B and Vicuna-7B but fails on Llama2-7B. Finally, we propose an ICL attack that uses the chat template tokens like a prompt injection attack to achieve a better attack success rate on Vicuna-7B and Starling-7B. Trigger Warning: the appendix contains LLM-generated text with violence, suicide, and misinformation.
Adversarial Attacks and Defenses in Large Language Models: Old and New Threats
Oct 30, 2023

Over the past decade, there has been extensive research aimed at enhancing the robustness of neural networks, yet this problem remains vastly unsolved. Here, one major impediment has been the overestimation of the robustness of new defense approaches due to faulty defense evaluations. Flawed robustness evaluations necessitate rectifications in subsequent works, dangerously slowing down the research and providing a false sense of security. In this context, we will face substantial challenges associated with an impending adversarial arms race in natural language processing, specifically with closed-source Large Language Models (LLMs), such as ChatGPT, Google Bard, or Anthropic's Claude. We provide a first set of prerequisites to improve the robustness assessment of new approaches and reduce the amount of faulty evaluations. Additionally, we identify embedding space attacks on LLMs as another viable threat model for the purposes of generating malicious content in open-sourced models. Finally, we demonstrate on a recently proposed defense that, without LLM-specific best practices in place, it is easy to overestimate the robustness of a new approach.
Raising the Bar for Certified Adversarial Robustness with Diffusion Models
May 17, 2023Certified defenses against adversarial attacks offer formal guarantees on the robustness of a model, making them more reliable than empirical methods such as adversarial training, whose effectiveness is often later reduced by unseen attacks. Still, the limited certified robustness that is currently achievable has been a bottleneck for their practical adoption. Gowal et al. and Wang et al. have shown that generating additional training data using state-of-the-art diffusion models can considerably improve the robustness of adversarial training. In this work, we demonstrate that a similar approach can substantially improve deterministic certified defenses. In addition, we provide a list of recommendations to scale the robustness of certified training approaches. One of our main insights is that the generalization gap, i.e., the difference between the training and test accuracy of the original model, is a good predictor of the magnitude of the robustness improvement when using additional generated data. Our approach achieves state-of-the-art deterministic robustness certificates on CIFAR-10 for the $\ell_2$ ($\epsilon = 36/255$) and $\ell_\infty$ ($\epsilon = 8/255$) threat models, outperforming the previous best results by $+3.95\%$ and $+1.39\%$, respectively. Furthermore, we report similar improvements for CIFAR-100.
Sarah Frank-Wolfe: Methods for Constrained Optimization with Best Rates and Practical Features
Apr 23, 2023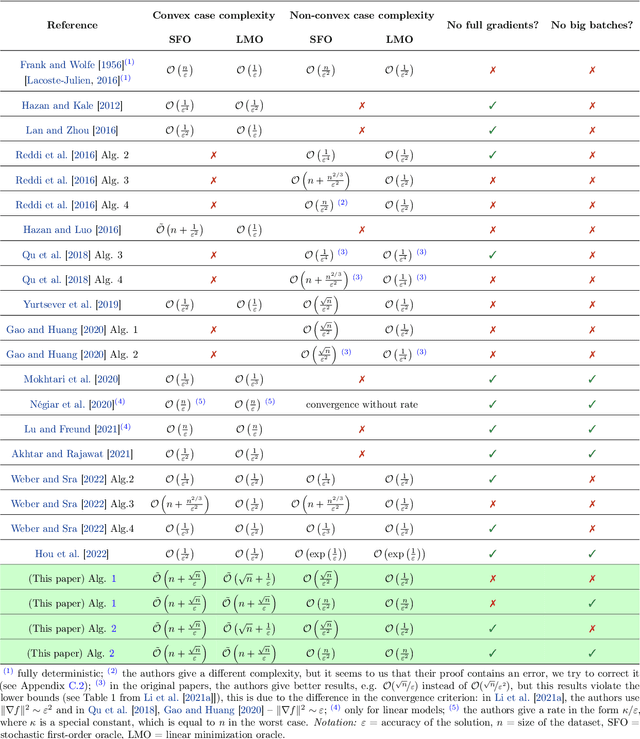
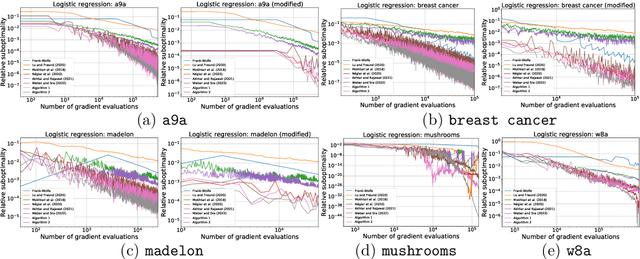
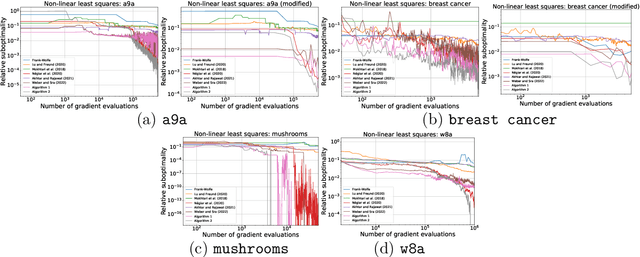
The Frank-Wolfe (FW) method is a popular approach for solving optimization problems with structured constraints that arise in machine learning applications. In recent years, stochastic versions of FW have gained popularity, motivated by large datasets for which the computation of the full gradient is prohibitively expensive. In this paper, we present two new variants of the FW algorithms for stochastic finite-sum minimization. Our algorithms have the best convergence guarantees of existing stochastic FW approaches for both convex and non-convex objective functions. Our methods do not have the issue of permanently collecting large batches, which is common to many stochastic projection-free approaches. Moreover, our second approach does not require either large batches or full deterministic gradients, which is a typical weakness of many techniques for finite-sum problems. The faster theoretical rates of our approaches are confirmed experimentally.
Dissecting adaptive methods in GANs
Oct 09, 2022



Adaptive methods are a crucial component widely used for training generative adversarial networks (GANs). While there has been some work to pinpoint the "marginal value of adaptive methods" in standard tasks, it remains unclear why they are still critical for GAN training. In this paper, we formally study how adaptive methods help train GANs; inspired by the grafting method proposed in arXiv:2002.11803 [cs.LG], we separate the magnitude and direction components of the Adam updates, and graft them to the direction and magnitude of SGDA updates respectively. By considering an update rule with the magnitude of the Adam update and the normalized direction of SGD, we empirically show that the adaptive magnitude of Adam is key for GAN training. This motivates us to have a closer look at the class of normalized stochastic gradient descent ascent (nSGDA) methods in the context of GAN training. We propose a synthetic theoretical framework to compare the performance of nSGDA and SGDA for GAN training with neural networks. We prove that in that setting, GANs trained with nSGDA recover all the modes of the true distribution, whereas the same networks trained with SGDA (and any learning rate configuration) suffer from mode collapse. The critical insight in our analysis is that normalizing the gradients forces the discriminator and generator to be updated at the same pace. We also experimentally show that for several datasets, Adam's performance can be recovered with nSGDA methods.
Clipped Stochastic Methods for Variational Inequalities with Heavy-Tailed Noise
Jun 02, 2022


Stochastic first-order methods such as Stochastic Extragradient (SEG) or Stochastic Gradient Descent-Ascent (SGDA) for solving smooth minimax problems and, more generally, variational inequality problems (VIP) have been gaining a lot of attention in recent years due to the growing popularity of adversarial formulations in machine learning. However, while high-probability convergence bounds are known to reflect the actual behavior of stochastic methods more accurately, most convergence results are provided in expectation. Moreover, the only known high-probability complexity results have been derived under restrictive sub-Gaussian (light-tailed) noise and bounded domain Assump. [Juditsky et al., 2011]. In this work, we prove the first high-probability complexity results with logarithmic dependence on the confidence level for stochastic methods for solving monotone and structured non-monotone VIPs with non-sub-Gaussian (heavy-tailed) noise and unbounded domains. In the monotone case, our results match the best-known ones in the light-tails case [Juditsky et al., 2011], and are novel for structured non-monotone problems such as negative comonotone, quasi-strongly monotone, and/or star-cocoercive ones. We achieve these results by studying SEG and SGDA with clipping. In addition, we numerically validate that the gradient noise of many practical GAN formulations is heavy-tailed and show that clipping improves the performance of SEG/SGDA.