 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Role of Causal Features in Strategic Classification for Robustness and Alignment
May 26, 2026In strategic classification, an institution (e.g., a bank) anticipates adaptation from users who change their features to increase utility in a classification task (e.g., loan repayment). Since a key challenge is the distribution shift induced by users, we turn to causal models, which have been shown to bound the worst-case out-of-distribution (OOD) risk, and establish several new results that link causality and strategic classification. First, we show that causal classification leads to optimal classification error after any sufficiently large adaptation, when the noise is bounded in a certain way. Second, when these assumptions do not hold, we show OOD cross-entropy risk of optimal classifiers decomposes into an OOD bias term and a term arising from not using all observable features, allowing us to understand when causal classifiers have an advantage. Finally, we show that the use of causal features can allow alignment of long-term incentives between institutions and users, contrasting with previous work that highlights social costs of such approaches. We validate our theory empirically on synthetic data, finding that our results predict behavior in practice.
A Compression Perspective on Simplicity Bias
Mar 26, 2026Deep neural networks exhibit a simplicity bias, a well-documented tendency to favor simple functions over complex ones. In this work, we cast new light on this phenomenon through the lens of the Minimum Description Length principle, formalizing supervised learning as a problem of optimal two-part lossless compression. Our theory explains how simplicity bias governs feature selection in neural networks through a fundamental trade-off between model complexity (the cost of describing the hypothesis) and predictive power (the cost of describing the data). Our framework predicts that as the amount of available training data increases, learners transition through qualitatively different features -- from simple spurious shortcuts to complex features -- only when the reduction in data encoding cost justifies the increased model complexity. Consequently, we identify distinct data regimes where increasing data promotes robustness by ruling out trivial shortcuts, and conversely, regimes where limiting data can act as a form of complexity-based regularization, preventing the learning of unreliable complex environmental cues. We validate our theory on a semi-synthetic benchmark showing that the feature selection of neural networks follows the same trajectory of solutions as optimal two-part compressors.
Who Guards the Guardians? The Challenges of Evaluating Identifiability of Learned Representations
Feb 27, 2026Identifiability in representation learning is commonly evaluated using standard metrics (e.g., MCC, DCI, R^2) on synthetic benchmarks with known ground-truth factors. These metrics are assumed to reflect recovery up to the equivalence class guaranteed by identifiability theory. We show that this assumption holds only under specific structural conditions: each metric implicitly encodes assumptions about both the data-generating process (DGP) and the encoder. When these assumptions are violated, metrics become misspecified and can produce systematic false positives and false negatives. Such failures occur both within classical identifiability regimes and in post-hoc settings where identifiability is most needed. We introduce a taxonomy separating DGP assumptions from encoder geometry, use it to characterise the validity domains of existing metrics, and release an evaluation suite for reproducible stress testing and comparison.
Causality is Key for Interpretability Claims to Generalise
Feb 18, 2026Interpretability research on large language models (LLMs) has yielded important insights into model behaviour, yet recurring pitfalls persist: findings that do not generalise, and causal interpretations that outrun the evidence. Our position is that causal inference specifies what constitutes a valid mapping from model activations to invariant high-level structures, the data or assumptions needed to achieve it, and the inferences it can support. Specifically, Pearl's causal hierarchy clarifies what an interpretability study can justify. Observations establish associations between model behaviour and internal components. Interventions (e.g., ablations or activation patching) support claims how these edits affect a behavioural metric (\eg, average change in token probabilities) over a set of prompts. However, counterfactual claims -- i.e., asking what the model output would have been for the same prompt under an unobserved intervention -- remain largely unverifiable without controlled supervision. We show how causal representation learning (CRL) operationalises this hierarchy, specifying which variables are recoverable from activations and under what assumptions. Together, these motivate a diagnostic framework that helps practitioners select methods and evaluations matching claims to evidence such that findings generalise.
From Isolation to Entanglement: When Do Interpretability Methods Identify and Disentangle Known Concepts?
Dec 17, 2025A central goal of interpretability is to recover representations of causally relevant concepts from the activations of neural networks. The quality of these concept representations is typically evaluated in isolation, and under implicit independence assumptions that may not hold in practice. Thus, it is unclear whether common featurization methods - including sparse autoencoders (SAEs) and sparse probes - recover disentangled representations of these concepts. This study proposes a multi-concept evaluation setting where we control the correlations between textual concepts, such as sentiment, domain, and tense, and analyze performance under increasing correlations between them. We first evaluate the extent to which featurizers can learn disentangled representations of each concept under increasing correlational strengths. We observe a one-to-many relationship from concepts to features: features correspond to no more than one concept, but concepts are distributed across many features. Then, we perform steering experiments, measuring whether each concept is independently manipulable. Even when trained on uniform distributions of concepts, SAE features generally affect many concepts when steered, indicating that they are neither selective nor independent; nonetheless, features affect disjoint subspaces. These results suggest that correlational metrics for measuring disentanglement are generally not sufficient for establishing independence when steering, and that affecting disjoint subspaces is not sufficient for concept selectivity. These results underscore the importance of compositional evaluations in interpretability research.
The Landscape of Causal Discovery Data: Grounding Causal Discovery in Real-World Applications
Dec 02, 2024

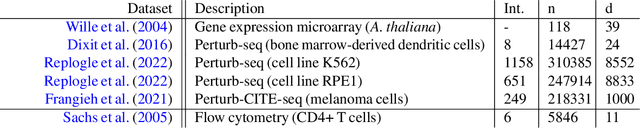

Causal discovery aims to automatically uncover causal relationships from data, a capability with significant potential across many scientific disciplines. However, its real-world applications remain limited. Current methods often rely on unrealistic assumptions and are evaluated only on simple synthetic toy datasets, often with inadequate evaluation metrics. In this paper, we substantiate these claims by performing a systematic review of the recent causal discovery literature. We present applications in biology, neuroscience, and Earth sciences - fields where causal discovery holds promise for addressing key challenges. We highlight available simulated and real-world datasets from these domains and discuss common assumption violations that have spurred the development of new methods. Our goal is to encourage the community to adopt better evaluation practices by utilizing realistic datasets and more adequate metrics.
General Causal Imputation via Synthetic Interventions
Oct 28, 2024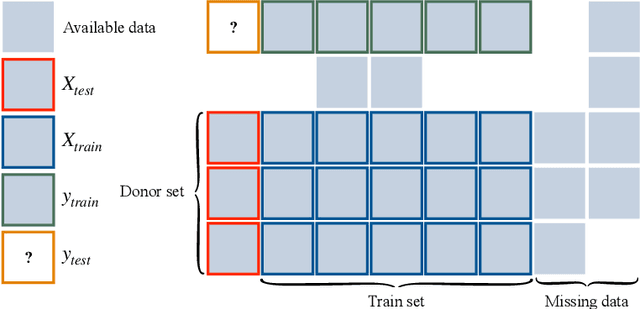
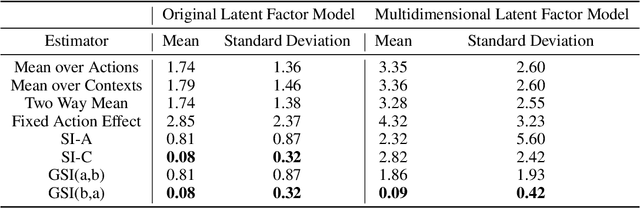
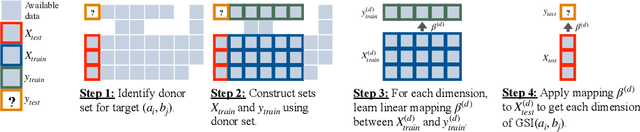
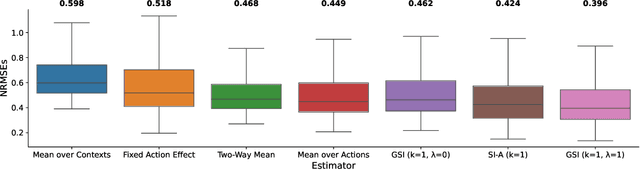
Given two sets of elements (such as cell types and drug compounds), researchers typically only have access to a limited subset of their interactions. The task of causal imputation involves using this subset to predict unobserved interactions. Squires et al. (2022) have proposed two estimators for this task based on the synthetic interventions (SI) estimator: SI-A (for actions) and SI-C (for contexts). We extend their work and introduce a novel causal imputation estimator, generalized synthetic interventions (GSI). We prove the identifiability of this estimator for data generated from a more complex latent factor model. On synthetic and real data we show empirically that it recovers or outperforms their estimators.
In-context learning and Occam's razor
Oct 17, 2024The goal of machine learning is generalization. While the No Free Lunch Theorem states that we cannot obtain theoretical guarantees for generalization without further assumptions, in practice we observe that simple models which explain the training data generalize best: a principle called Occam's razor. Despite the need for simple models, most current approaches in machine learning only minimize the training error, and at best indirectly promote simplicity through regularization or architecture design. Here, we draw a connection between Occam's razor and in-context learning: an emergent ability of certain sequence models like Transformers to learn at inference time from past observations in a sequence. In particular, we show that the next-token prediction loss used to train in-context learners is directly equivalent to a data compression technique called prequential coding, and that minimizing this loss amounts to jointly minimizing both the training error and the complexity of the model that was implicitly learned from context. Our theory and the empirical experiments we use to support it not only provide a normative account of in-context learning, but also elucidate the shortcomings of current in-context learning methods, suggesting ways in which they can be improved. We make our code available at https://github.com/3rdCore/PrequentialCode.
Causal Representation Learning in Temporal Data via Single-Parent Decoding
Oct 09, 2024



Scientific research often seeks to understand the causal structure underlying high-level variables in a system. For example, climate scientists study how phenomena, such as El Ni\~no, affect other climate processes at remote locations across the globe. However, scientists typically collect low-level measurements, such as geographically distributed temperature readings. From these, one needs to learn both a mapping to causally-relevant latent variables, such as a high-level representation of the El Ni\~no phenomenon and other processes, as well as the causal model over them. The challenge is that this task, called causal representation learning, is highly underdetermined from observational data alone, requiring other constraints during learning to resolve the indeterminacies. In this work, we consider a temporal model with a sparsity assumption, namely single-parent decoding: each observed low-level variable is only affected by a single latent variable. Such an assumption is reasonable in many scientific applications that require finding groups of low-level variables, such as extracting regions from geographically gridded measurement data in climate research or capturing brain regions from neural activity data. We demonstrate the identifiability of the resulting model and propose a differentiable method, Causal Discovery with Single-parent Decoding (CDSD), that simultaneously learns the underlying latents and a causal graph over them. We assess the validity of our theoretical results using simulated data and showcase the practical validity of our method in an application to real-world data from the climate science field.
Sparsity regularization via tree-structured environments for disentangled representations
Jun 10, 2024

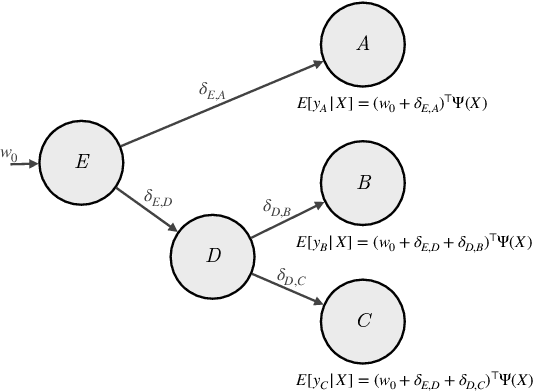
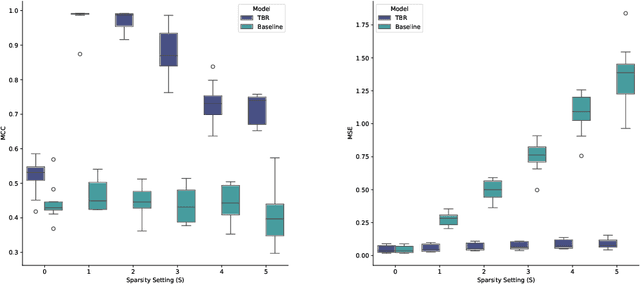
Many causal systems such as biological processes in cells can only be observed indirectly via measurements, such as gene expression. Causal representation learning -- the task of correctly mapping low-level observations to latent causal variables -- could advance scientific understanding by enabling inference of latent variables such as pathway activation. In this paper, we develop methods for inferring latent variables from multiple related datasets (environments) and tasks. As a running example, we consider the task of predicting a phenotype from gene expression, where we often collect data from multiple cell types or organisms that are related in known ways. The key insight is that the mapping from latent variables driven by gene expression to the phenotype of interest changes sparsely across closely related environments. To model sparse changes, we introduce Tree-Based Regularization (TBR), an objective that minimizes both prediction error and regularizes closely related environments to learn similar predictors. We prove that under assumptions about the degree of sparse changes, TBR identifies the true latent variables up to some simple transformations. We evaluate the theory empirically with both simulations and ground-truth gene expression data. We find that TBR recovers the latent causal variables better than related methods across these settings, even under settings that violate some assumptions of the theory.