 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comedy of Estimators: On KL Regularization in RL Training of LLMs
Dec 26, 2025The reasoning performance of large language models (LLMs) can be substantially improved by training them with reinforcement learning (RL). The RL objective for LLM training involves a regularization term, which is the reverse Kullback-Leibler (KL) divergence between the trained policy and the reference policy. Since computing the KL divergence exactly is intractable, various estimators are used in practice to estimate it from on-policy samples. Despite its wide adoption, including in several open-source libraries, there is no systematic study analyzing the numerous ways of incorporating KL estimators in the objective and their effect on the downstream performance of RL-trained models. Recent works show that prevailing practices for incorporating KL regularization do not provide correct gradients for stated objectives, creating a discrepancy between the objective and its implementation. In this paper, we further analyze these practices and study the gradients of several estimators configurations, revealing how design choices shape gradient bias. We substantiate these findings with empirical observations by RL fine-tuning \texttt{Qwen2.5-7B}, \texttt{Llama-3.1-8B-Instruct} and \texttt{Qwen3-4B-Instruct-2507} with different configurations and evaluating their performance on both in- and out-of-distribution tasks. Through our analysis, we observe that, in on-policy settings: (1) estimator configurations with biased gradients can result in training instabilities; and (2) using estimator configurations resulting in unbiased gradients leads to better performance on in-domain as well as out-of-domain tasks. We also investigate the performance resulting from different KL configurations in off-policy settings and observe that KL regularization can help stabilize off-policy RL training resulting from asynchronous setups.
Recursive Self-Aggregation Unlocks Deep Thinking in Large Language Models
Sep 30, 2025Test-time scaling methods improve the capabilities of large language models (LLMs) by increasing the amount of compute used during inference to make a prediction. Inference-time compute can be scaled in parallel by choosing among multiple independent solutions or sequentially through self-refinement. We propose Recursive Self-Aggregation (RSA), a test-time scaling method inspired by evolutionary methods that combines the benefits of both parallel and sequential scaling. Each step of RSA refines a population of candidate reasoning chains through aggregation of subsets to yield a population of improved solutions, which are then used as the candidate pool for the next iteration. RSA exploits the rich information embedded in the reasoning chains -- not just the final answers -- and enables bootstrapping from partially correct intermediate steps within different chains of thought. Empirically, RSA delivers substantial performance gains with increasing compute budgets across diverse tasks, model families and sizes. Notably, RSA enables Qwen3-4B-Instruct-2507 to achieve competitive performance with larger reasoning models, including DeepSeek-R1 and o3-mini (high), while outperforming purely parallel and sequential scaling strategies across AIME-25, HMMT-25, Reasoning Gym, LiveCodeBench-v6, and SuperGPQA. We further demonstrate that training the model to combine solutions via a novel aggregation-aware reinforcement learning approach yields significant performance gains. Code available at https://github.com/HyperPotatoNeo/RSA.
Solving Bayesian inverse problems with diffusion priors and off-policy RL
Mar 12, 2025This paper presents a practical application of Relative Trajectory Balance (RTB), a recently introduced off-policy reinforcement learning (RL) objective that can asymptotically solve Bayesian inverse problems optimally. We extend the original work by using RTB to train conditional diffusion model posteriors from pretrained unconditional priors for challenging linear and non-linear inverse problems in vision, and science. We use the objective alongside techniques such as off-policy backtracking exploration to improve training. Importantly, our results show that existing training-free diffusion posterior methods struggle to perform effective posterior inference in latent space due to inherent biases.
In-Context Parametric Inference: Point or Distribution Estimators?
Feb 17, 2025Bayesian and frequentist inference are two fundamental paradigms in statistical estimation. Bayesian methods treat hypotheses as random variables, incorporating priors and updating beliefs via Bayes' theorem, whereas frequentist methods assume fixed but unknown hypotheses, relying on estimators like maximum likelihood. While extensive research has compared these approaches, the frequentist paradigm of obtaining point estimates has become predominant in deep learning, as Bayesian inference is challenging due to the computational complexity and the approximation gap of posterior estimation methods. However, a good understanding of trade-offs between the two approaches is lacking in the regime of amortized estimators, where in-context learners are trained to estimate either point values via maximum likelihood or maximum a posteriori estimation, or full posteriors using normalizing flows, score-based diffusion samplers, or diagonal Gaussian approximations, conditioned on observations. To help resolve this, we conduct a rigorous comparative analysis spanning diverse problem settings, from linear models to shallow neural networks, with a robust evaluation framework assessing both in-distribution and out-of-distribution generalization on tractable tasks. Our experiments indicate that amortized point estimators generally outperform posterior inference, though the latter remain competitive in some low-dimensional problems, and we further discuss why this might be the case.
Amortized In-Context Bayesian Posterior Estimation
Feb 10, 2025Bayesian inference provides a natural way of incorporating prior beliefs and assigning a probability measure to the space of hypotheses. Current solutions rely on iterative routines like Markov Chain Monte Carlo (MCMC) sampling and Variational Inference (VI), which need to be re-run whenever new observations are available. Amortization, through conditional estimation, is a viable strategy to alleviate such difficulties and has been the guiding principle behind simulation-based inference, neural processes and in-context methods using pre-trained models. In this work, we conduct a thorough comparative analysis of amortized in-context Bayesian posterior estimation methods from the lens of different optimization objectives and architectural choices. Such methods train an amortized estimator to perform posterior parameter inference by conditioning on a set of data examples passed as context to a sequence model such as a transformer. In contrast to language models, we leverage permutation invariant architectures as the true posterior is invariant to the ordering of context examples. Our empirical study includes generalization to out-of-distribution tasks, cases where the assumed underlying model is misspecified, and transfer from simulated to real problems. Subsequently, it highlights the superiority of the reverse KL estimator for predictive problems, especially when combined with the transformer architecture and normalizing flows.
In-context learning and Occam's razor
Oct 17, 2024The goal of machine learning is generalization. While the No Free Lunch Theorem states that we cannot obtain theoretical guarantees for generalization without further assumptions, in practice we observe that simple models which explain the training data generalize best: a principle called Occam's razor. Despite the need for simple models, most current approaches in machine learning only minimize the training error, and at best indirectly promote simplicity through regularization or architecture design. Here, we draw a connection between Occam's razor and in-context learning: an emergent ability of certain sequence models like Transformers to learn at inference time from past observations in a sequence. In particular, we show that the next-token prediction loss used to train in-context learners is directly equivalent to a data compression technique called prequential coding, and that minimizing this loss amounts to jointly minimizing both the training error and the complexity of the model that was implicitly learned from context. Our theory and the empirical experiments we use to support it not only provide a normative account of in-context learning, but also elucidate the shortcomings of current in-context learning methods, suggesting ways in which they can be improved. We make our code available at https://github.com/3rdCore/PrequentialCode.
Steering Masked Discrete Diffusion Models via Discrete Denoising Posterior Prediction
Oct 10, 2024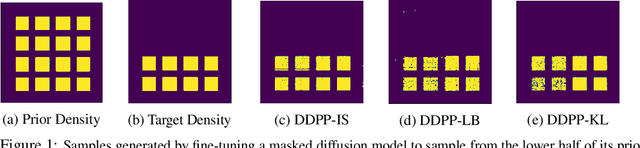

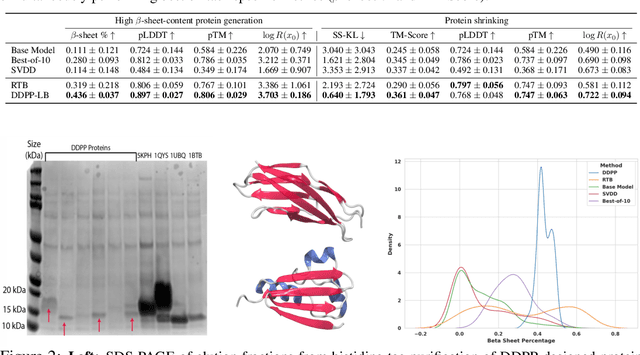

Generative modeling of discrete data underlies important applications spanning text-based agents like ChatGPT to the design of the very building blocks of life in protein sequences. However, application domains need to exert control over the generated data by steering the generative process - typically via RLHF - to satisfy a specified property, reward, or affinity metric. In this paper, we study the problem of steering Masked Diffusion Models (MDMs), a recent class of discrete diffusion models that offer a compelling alternative to traditional autoregressive models. We introduce Discrete Denoising Posterior Prediction (DDPP), a novel framework that casts the task of steering pre-trained MDMs as a problem of probabilistic inference by learning to sample from a target Bayesian posterior. Our DDPP framework leads to a family of three novel objectives that are all simulation-free, and thus scalable while applying to general non-differentiable reward functions. Empirically, we instantiate DDPP by steering MDMs to perform class-conditional pixel-level image modeling, RLHF-based alignment of MDMs using text-based rewards, and finetuning protein language models to generate more diverse secondary structures and shorter proteins. We substantiate our designs via wet-lab validation, where we observe transient expression of reward-optimized protein sequences.
Recurrent Interpolants for Probabilistic Time Series Prediction
Sep 18, 2024



Sequential models such as recurrent neural networks or transformer-based models became \textit{de facto} tools for multivariate time series forecasting in a probabilistic fashion, with applications to a wide range of datasets, such as finance, biology, medicine, etc. Despite their adeptness in capturing dependencies, assessing prediction uncertainty, and efficiency in training, challenges emerge in modeling high-dimensional complex distributions and cross-feature dependencies. To tackle these issues, recent works delve into generative modeling by employing diffusion or flow-based models. Notably, the integration of stochastic differential equations or probability flow successfully extends these methods to probabilistic time series imputation and forecasting. However, scalability issues necessitate a computational-friendly framework for large-scale generative model-based predictions. This work proposes a novel approach by blending the computational efficiency of recurrent neural networks with the high-quality probabilistic modeling of the diffusion model, which addresses challenges and advances generative models' application in time series forecasting. Our method relies on the foundation of stochastic interpolants and the extension to a broader conditional generation framework with additional control features, offering insights for future developments in this dynamic field.
Amortizing intractable inference in diffusion models for vision, language, and control
May 31, 2024



Diffusion models have emerged as effective distribution estimators in vision, language, and reinforcement learning, but their use as priors in downstream tasks poses an intractable posterior inference problem. This paper studies amortized sampling of the posterior over data, $\mathbf{x}\sim p^{\rm post}(\mathbf{x})\propto p(\mathbf{x})r(\mathbf{x})$, in a model that consists of a diffusion generative model prior $p(\mathbf{x})$ and a black-box constraint or likelihood function $r(\mathbf{x})$. We state and prove the asymptotic correctness of a data-free learning objective, relative trajectory balance, for training a diffusion model that samples from this posterior, a problem that existing methods solve only approximately or in restricted cases. Relative trajectory balance arises from the generative flow network perspective on diffusion models, which allows the use of deep reinforcement learning techniques to improve mode coverage. Experiments illustrate the broad potential of unbiased inference of arbitrary posteriors under diffusion priors: in vision (classifier guidance), language (infilling under a discrete diffusion LLM), and multimodal data (text-to-image generation). Beyond generative modeling, we apply relative trajectory balance to the problem of continuous control with a score-based behavior prior, achieving state-of-the-art results on benchmarks in offline reinforcement learning.
Does learning the right latent variables necessarily improve in-context learning?
May 29, 2024Large autoregressive models like Transformers can solve tasks through in-context learning (ICL) without learning new weights, suggesting avenues for efficiently solving new tasks. For many tasks, e.g., linear regression, the data factorizes: examples are independent given a task latent that generates the data, e.g., linear coefficients. While an optimal predictor leverages this factorization by inferring task latents, it is unclear if Transformers implicitly do so or if they instead exploit heuristics and statistical shortcuts enabled by attention layers. Both scenarios have inspired active ongoing work. In this paper, we systematically investigate the effect of explicitly inferring task latents. We minimally modify the Transformer architecture with a bottleneck designed to prevent shortcuts in favor of more structured solutions, and then compare performance against standard Transformers across various ICL tasks. Contrary to intuition and some recent works, we find little discernible difference between the two; biasing towards task-relevant latent variables does not lead to better out-of-distribution performance, in general. Curiously, we find that while the bottleneck effectively learns to extract latent task variables from context, downstream processing struggles to utilize them for robust prediction. Our study highlights the intrinsic limitations of Transformers in achieving structured ICL solutions that generalize, and shows that while inferring the right latents aids interpretability, it is not sufficient to alleviate this problem.