 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonitoring the Internal Monologue: Probe Trajectories Reveal Reasoning Dynamics
May 18, 2026Large Reasoning Models (LRMs) introduce new opportunities for safety monitoring through their Chain of Thought (CoT) reasoning. However, CoT is not always faithful to the model's final output, undermining its reliability as a monitoring tool. To address this, we investigate the hidden representations of LRMs to determine whether future behavior can be predicted from prompt and CoT representations. By evaluating a probe at each generated token, we construct a probe trajectory, the continuous evolution of a concept's probability across the reasoning process. We find that future model behavior is more distinguishable when examined over the full trajectory than from a single static prediction. To characterize these temporal dynamics, we extract signal-processing features that capture volatility, trend, and steady-state behavior, significantly improving the separation of future model states. We also present two methodological insights. First, template-based training data achieves near-parity with dynamically generated model responses, eliminating the need for a costly initial inference and labeling. Second, the choice of pooling operation is critical: average-pooling and last-token methods collapse to near-random performance, while max-pooling achieves up to 95% AUROC and yields stable probe trajectories. Using four datasets and four reasoning models across the domains of safety and mathematics, we demonstrate that trajectory features encode task-specific dynamics that improve outcome separability. These findings establish probe trajectories as a complementary framework for monitoring LRM behavior. Warning: This article contains potentially harmful content.
Hi-fi functional priors by learning activations
Aug 12, 2025



Function-space priors in Bayesian Neural Networks (BNNs) provide a more intuitive approach to embedding beliefs directly into the model's output, thereby enhancing regularization, uncertainty quantification, and risk-aware decision-making. However, imposing function-space priors on BNNs is challenging. We address this task through optimization techniques that explore how trainable activations can accommodate higher-complexity priors and match intricate target function distributions. We investigate flexible activation models, including Pade functions and piecewise linear functions, and discuss the learning challenges related to identifiability, loss construction, and symmetries. Our empirical findings indicate that even BNNs with a single wide hidden layer when equipped with flexible trainable activation, can effectively achieve desired function-space priors.
Solving Bayesian inverse problems with diffusion priors and off-policy RL
Mar 12, 2025This paper presents a practical application of Relative Trajectory Balance (RTB), a recently introduced off-policy reinforcement learning (RL) objective that can asymptotically solve Bayesian inverse problems optimally. We extend the original work by using RTB to train conditional diffusion model posteriors from pretrained unconditional priors for challenging linear and non-linear inverse problems in vision, and science. We use the objective alongside techniques such as off-policy backtracking exploration to improve training. Importantly, our results show that existing training-free diffusion posterior methods struggle to perform effective posterior inference in latent space due to inherent biases.
SEMU: Singular Value Decomposition for Efficient Machine Unlearning
Feb 11, 2025



While the capabilities of generative foundational models have advanced rapidly in recent years, methods to prevent harmful and unsafe behaviors remain underdeveloped. Among the pressing challenges in AI safety, machine unlearning (MU) has become increasingly critical to meet upcoming safety regulations. Most existing MU approaches focus on altering the most significant parameters of the model. However, these methods often require fine-tuning substantial portions of the model, resulting in high computational costs and training instabilities, which are typically mitigated by access to the original training dataset. In this work, we address these limitations by leveraging Singular Value Decomposition (SVD) to create a compact, low-dimensional projection that enables the selective forgetting of specific data points. We propose Singular Value Decomposition for Efficient Machine Unlearning (SEMU), a novel approach designed to optimize MU in two key aspects. First, SEMU minimizes the number of model parameters that need to be modified, effectively removing unwanted knowledge while making only minimal changes to the model's weights. Second, SEMU eliminates the dependency on the original training dataset, preserving the model's previously acquired knowledge without additional data requirements. Extensive experiments demonstrate that SEMU achieves competitive performance while significantly improving efficiency in terms of both data usage and the number of modified parameters.
Outsourced diffusion sampling: Efficient posterior inference in latent spaces of generative models
Feb 10, 2025
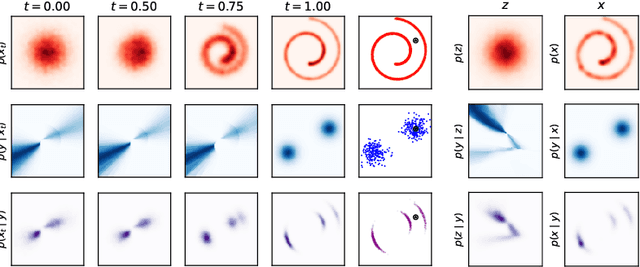


Any well-behaved generative model over a variable $\mathbf{x}$ can be expressed as a deterministic transformation of an exogenous ('outsourced') Gaussian noise variable $\mathbf{z}$: $\mathbf{x}=f_\theta(\mathbf{z})$. In such a model (e.g., a VAE, GAN, or continuous-time flow-based model), sampling of the target variable $\mathbf{x} \sim p_\theta(\mathbf{x})$ is straightforward, but sampling from a posterior distribution of the form $p(\mathbf{x}\mid\mathbf{y}) \propto p_\theta(\mathbf{x})r(\mathbf{x},\mathbf{y})$, where $r$ is a constraint function depending on an auxiliary variable $\mathbf{y}$, is generally intractable. We propose to amortize the cost of sampling from such posterior distributions with diffusion models that sample a distribution in the noise space ($\mathbf{z}$). These diffusion samplers are trained by reinforcement learning algorithms to enforce that the transformed samples $f_\theta(\mathbf{z})$ are distributed according to the posterior in the data space ($\mathbf{x}$). For many models and constraints of interest, the posterior in the noise space is smoother than the posterior in the data space, making it more amenable to such amortized inference. Our method enables conditional sampling under unconditional GAN, (H)VAE, and flow-based priors, comparing favorably both with current amortized and non-amortized inference methods. We demonstrate the proposed outsourced diffusion sampling in several experiments with large pretrained prior models: conditional image generation, reinforcement learning with human feedback, and protein structure generation.
From discrete-time policies to continuous-time diffusion samplers: Asymptotic equivalences and faster training
Jan 10, 2025We study the problem of training neural stochastic differential equations, or diffusion models, to sample from a Boltzmann distribution without access to target samples. Existing methods for training such models enforce time-reversal of the generative and noising processes, using either differentiable simulation or off-policy reinforcement learning (RL). We prove equivalences between families of objectives in the limit of infinitesimal discretization steps, linking entropic RL methods (GFlowNets) with continuous-time objects (partial differential equations and path space measures). We further show that an appropriate choice of coarse time discretization during training allows greatly improved sample efficiency and the use of time-local objectives, achieving competitive performance on standard sampling benchmarks with reduced computational cost.
High-Fidelity Transfer of Functional Priors for Wide Bayesian Neural Networks by Learning Activations
Oct 21, 2024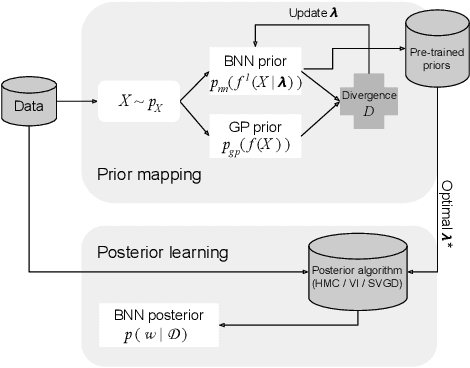



Function-space priors in Bayesian Neural Networks provide a more intuitive approach to embedding beliefs directly into the model's output, thereby enhancing regularization, uncertainty quantification, and risk-aware decision-making. However, imposing function-space priors on BNNs is challenging. We address this task through optimization techniques that explore how trainable activations can accommodate complex priors and match intricate target function distributions. We discuss critical learning challenges, including identifiability, loss construction, and symmetries that arise in this context. Furthermore, we enable evidence maximization to facilitate model selection by conditioning the functional priors on additional hyperparameters. Our empirical findings demonstrate that even BNNs with a single wide hidden layer, when equipped with these adaptive trainable activations and conditioning strategies, can effectively achieve high-fidelity function-space priors, providing a robust and flexible framework for enhancing Bayesian neural network performance.
AutoLoRA: AutoGuidance Meets Low-Rank Adaptation for Diffusion Models
Oct 04, 2024



Low-rank adaptation (LoRA) is a fine-tuning technique that can be applied to conditional generative diffusion models. LoRA utilizes a small number of context examples to adapt the model to a specific domain, character, style, or concept. However, due to the limited data utilized during training, the fine-tuned model performance is often characterized by strong context bias and a low degree of variability in the generated images. To solve this issue, we introduce AutoLoRA, a novel guidance technique for diffusion models fine-tuned with the LoRA approach. Inspired by other guidance techniques, AutoLoRA searches for a trade-off between consistency in the domain represented by LoRA weights and sample diversity from the base conditional diffusion model. Moreover, we show that incorporating classifier-free guidance for both LoRA fine-tuned and base models leads to generating samples with higher diversity and better quality. The experimental results for several fine-tuned LoRA domains show superiority over existing guidance techniques on selected metrics.
Amortizing intractable inference in diffusion models for vision, language, and control
May 31, 2024



Diffusion models have emerged as effective distribution estimators in vision, language, and reinforcement learning, but their use as priors in downstream tasks poses an intractable posterior inference problem. This paper studies amortized sampling of the posterior over data, $\mathbf{x}\sim p^{\rm post}(\mathbf{x})\propto p(\mathbf{x})r(\mathbf{x})$, in a model that consists of a diffusion generative model prior $p(\mathbf{x})$ and a black-box constraint or likelihood function $r(\mathbf{x})$. We state and prove the asymptotic correctness of a data-free learning objective, relative trajectory balance, for training a diffusion model that samples from this posterior, a problem that existing methods solve only approximately or in restricted cases. Relative trajectory balance arises from the generative flow network perspective on diffusion models, which allows the use of deep reinforcement learning techniques to improve mode coverage. Experiments illustrate the broad potential of unbiased inference of arbitrary posteriors under diffusion priors: in vision (classifier guidance), language (infilling under a discrete diffusion LLM), and multimodal data (text-to-image generation). Beyond generative modeling, we apply relative trajectory balance to the problem of continuous control with a score-based behavior prior, achieving state-of-the-art results on benchmarks in offline reinforcement learning.
On diffusion models for amortized inference: Benchmarking and improving stochastic control and sampling
Feb 13, 2024
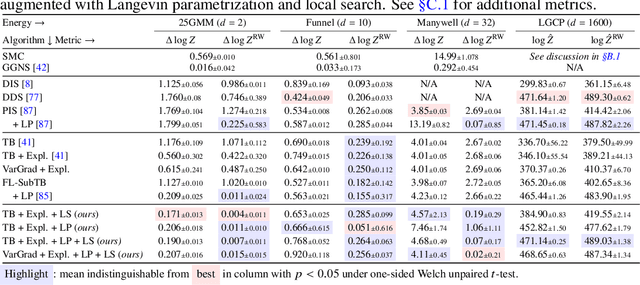
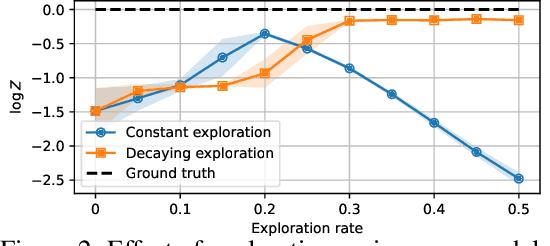
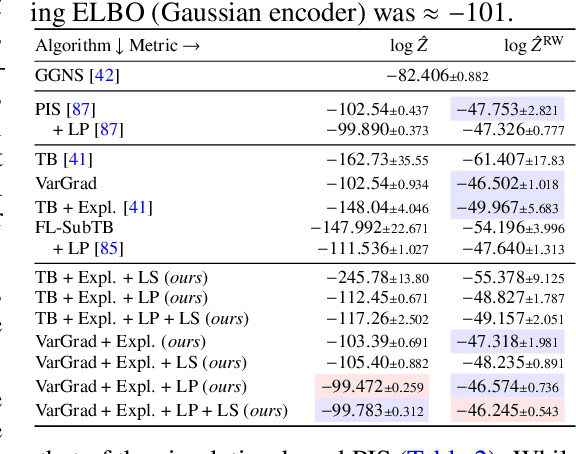
We study the problem of training diffusion models to sample from a distribution with a given unnormalized density or energy function. We benchmark several diffusion-structured inference methods, including simulation-based variational approaches and off-policy methods (continuous generative flow networks). Our results shed light on the relative advantages of existing algorithms while bringing into question some claims from past work. We also propose a novel exploration strategy for off-policy methods, based on local search in the target space with the use of a replay buffer, and show that it improves the quality of samples on a variety of target distributions. Our code for the sampling methods and benchmarks studied is made public at https://github.com/GFNOrg/gfn-diffusion as a base for future work on diffusion models for amortized inference.