 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlashLips: 100-FPS Mask-Free Latent Lip-Sync using Reconstruction Instead of Diffusion or GANs
Dec 23, 2025We present FlashLips, a two-stage, mask-free lip-sync system that decouples lips control from rendering and achieves real-time performance running at over 100 FPS on a single GPU, while matching the visual quality of larger state-of-the-art models. Stage 1 is a compact, one-step latent-space editor that reconstructs an image using a reference identity, a masked target frame, and a low-dimensional lips-pose vector, trained purely with reconstruction losses - no GANs or diffusion. To remove explicit masks at inference, we use self-supervision: we generate mouth-altered variants of the target image, that serve as pseudo ground truth for fine-tuning, teaching the network to localize edits to the lips while preserving the rest. Stage 2 is an audio-to-pose transformer trained with a flow-matching objective to predict lips-poses vectors from speech. Together, these stages form a simple and stable pipeline that combines deterministic reconstruction with robust audio control, delivering high perceptual quality and faster-than-real-time speed.
KeySync: A Robust Approach for Leakage-free Lip Synchronization in High Resolution
May 01, 2025Lip synchronization, known as the task of aligning lip movements in an existing video with new input audio, is typically framed as a simpler variant of audio-driven facial animation. However, as well as suffering from the usual issues in talking head generation (e.g., temporal consistency), lip synchronization presents significant new challenges such as expression leakage from the input video and facial occlusions, which can severely impact real-world applications like automated dubbing, but are often neglected in existing works. To address these shortcomings, we present KeySync, a two-stage framework that succeeds in solving the issue of temporal consistency, while also incorporating solutions for leakage and occlusions using a carefully designed masking strategy. We show that KeySync achieves state-of-the-art results in lip reconstruction and cross-synchronization, improving visual quality and reducing expression leakage according to LipLeak, our novel leakage metric. Furthermore, we demonstrate the effectiveness of our new masking approach in handling occlusions and validate our architectural choices through several ablation studies. Code and model weights can be found at https://antonibigata.github.io/KeySync.
KeyFace: Expressive Audio-Driven Facial Animation for Long Sequences via KeyFrame Interpolation
Mar 03, 2025Current audio-driven facial animation methods achieve impressive results for short videos but suffer from error accumulation and identity drift when extended to longer durations. Existing methods attempt to mitigate this through external spatial control, increasing long-term consistency but compromising the naturalness of motion. We propose KeyFace, a novel two-stage diffusion-based framework, to address these issues. In the first stage, keyframes are generated at a low frame rate, conditioned on audio input and an identity frame, to capture essential facial expressions and movements over extended periods of time. In the second stage, an interpolation model fills in the gaps between keyframes, ensuring smooth transitions and temporal coherence. To further enhance realism, we incorporate continuous emotion representations and handle a wide range of non-speech vocalizations (NSVs), such as laughter and sighs. We also introduce two new evaluation metrics for assessing lip synchronization and NSV generation. Experimental results show that KeyFace outperforms state-of-the-art methods in generating natural, coherent facial animations over extended durations, successfully encompassing NSVs and continuous emotions.
AutoLoRA: AutoGuidance Meets Low-Rank Adaptation for Diffusion Models
Oct 04, 2024



Low-rank adaptation (LoRA) is a fine-tuning technique that can be applied to conditional generative diffusion models. LoRA utilizes a small number of context examples to adapt the model to a specific domain, character, style, or concept. However, due to the limited data utilized during training, the fine-tuned model performance is often characterized by strong context bias and a low degree of variability in the generated images. To solve this issue, we introduce AutoLoRA, a novel guidance technique for diffusion models fine-tuned with the LoRA approach. Inspired by other guidance techniques, AutoLoRA searches for a trade-off between consistency in the domain represented by LoRA weights and sample diversity from the base conditional diffusion model. Moreover, we show that incorporating classifier-free guidance for both LoRA fine-tuned and base models leads to generating samples with higher diversity and better quality. The experimental results for several fine-tuned LoRA domains show superiority over existing guidance techniques on selected metrics.
Dimma: Semi-supervised Low Light Image Enhancement with Adaptive Dimming
Oct 14, 2023



Enhancing low-light images while maintaining natural colors is a challenging problem due to camera processing variations and limited access to photos with ground-truth lighting conditions. The latter is a crucial factor for supervised methods that achieve good results on paired datasets but do not handle out-of-domain data well. On the other hand, unsupervised methods, while able to generalize, often yield lower-quality enhancements. To fill this gap, we propose Dimma, a semi-supervised approach that aligns with any camera by utilizing a small set of image pairs to replicate scenes captured under extreme lighting conditions taken by that specific camera. We achieve that by introducing a convolutional mixture density network that generates distorted colors of the scene based on the illumination differences. Additionally, our approach enables accurate grading of the dimming factor, which provides a wide range of control and flexibility in adjusting the brightness levels during the low-light image enhancement process. To further improve the quality of our results, we introduce an architecture based on a conditional UNet. The lightness value provided by the user serves as the conditional input to generate images with the desired lightness. Our approach using only few image pairs achieves competitive results compared to fully supervised methods. Moreover, when trained on the full dataset, our model surpasses state-of-the-art methods in some metrics and closely approaches them in others.
Self-supervised adversarial masking for 3D point cloud representation learning
Jul 11, 2023Self-supervised methods have been proven effective for learning deep representations of 3D point cloud data. Although recent methods in this domain often rely on random masking of inputs, the results of this approach can be improved. We introduce PointCAM, a novel adversarial method for learning a masking function for point clouds. Our model utilizes a self-distillation framework with an online tokenizer for 3D point clouds. Compared to previous techniques that optimize patch-level and object-level objectives, we postulate applying an auxiliary network that learns how to select masks instead of choosing them randomly. Our results show that the learned masking function achieves state-of-the-art or competitive performance on various downstream tasks. The source code is available at https://github.com/szacho/pointcam.
Diffused Heads: Diffusion Models Beat GANs on Talking-Face Generation
Jan 06, 2023



Talking face generation has historically struggled to produce head movements and natural facial expressions without guidance from additional reference videos. Recent developments in diffusion-based generative models allow for more realistic and stable data synthesis and their performance on image and video generation has surpassed that of other generative models. In this work, we present an autoregressive diffusion model that requires only one identity image and audio sequence to generate a video of a realistic talking human head. Our solution is capable of hallucinating head movements, facial expressions, such as blinks, and preserving a given background. We evaluate our model on two different datasets, achieving state-of-the-art results on both of them.
Continual learning on 3D point clouds with random compressed rehearsal
May 20, 2022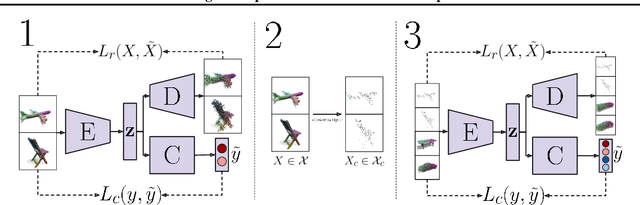

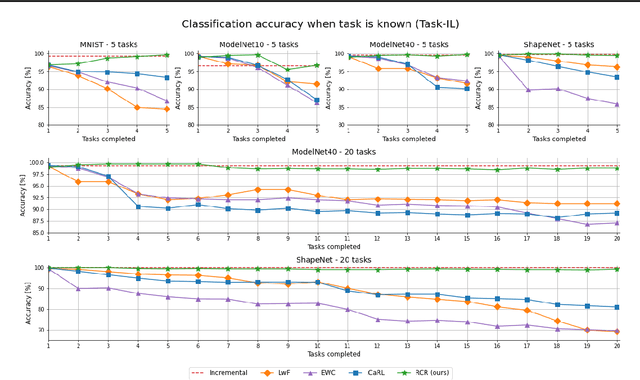

Contemporary deep neural networks offer state-of-the-art results when applied to visual reasoning, e.g., in the context of 3D point cloud data. Point clouds are important datatype for precise modeling of three-dimensional environments, but effective processing of this type of data proves to be challenging. In the world of large, heavily-parameterized network architectures and continuously-streamed data, there is an increasing need for machine learning models that can be trained on additional data. Unfortunately, currently available models cannot fully leverage training on additional data without losing their past knowledge. Combating this phenomenon, called catastrophic forgetting, is one of the main objectives of continual learning. Continual learning for deep neural networks has been an active field of research, primarily in 2D computer vision, natural language processing, reinforcement learning, and robotics. However, in 3D computer vision, there are hardly any continual learning solutions specifically designed to take advantage of point cloud structure. This work proposes a novel neural network architecture capable of continual learning on 3D point cloud data. We utilize point cloud structure properties for preserving a heavily compressed set of past data. By using rehearsal and reconstruction as regularization methods of the learning process, our approach achieves a significant decrease of catastrophic forgetting compared to the existing solutions on several most popular point cloud datasets considering two continual learning settings: when a task is known beforehand, and in the challenging scenario of when task information is unknown to the model.
Information Retrieval for ZeroSpeech 2021: The Submission by University of Wroclaw
Jun 22, 2021

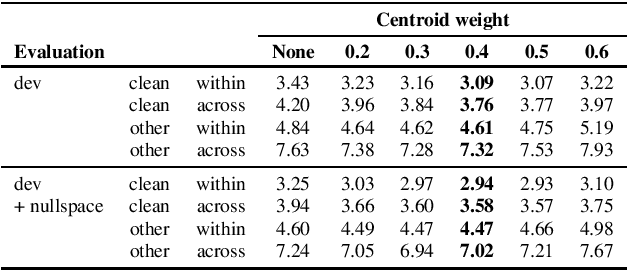
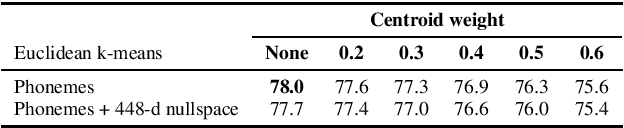
We present a number of low-resource approaches to the tasks of the Zero Resource Speech Challenge 2021. We build on the unsupervised representations of speech proposed by the organizers as a baseline, derived from CPC and clustered with the k-means algorithm. We demonstrate that simple methods of refining those representations can narrow the gap, or even improve upon the solutions which use a high computational budget. The results lead to the conclusion that the CPC-derived representations are still too noisy for training language models, but stable enough for simpler forms of pattern matching and retrieval.
Aligned Contrastive Predictive Coding
Apr 29, 2021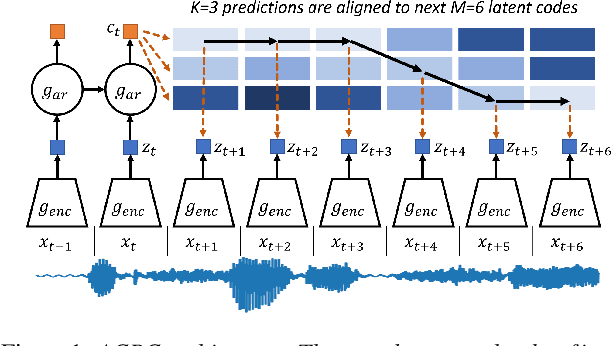

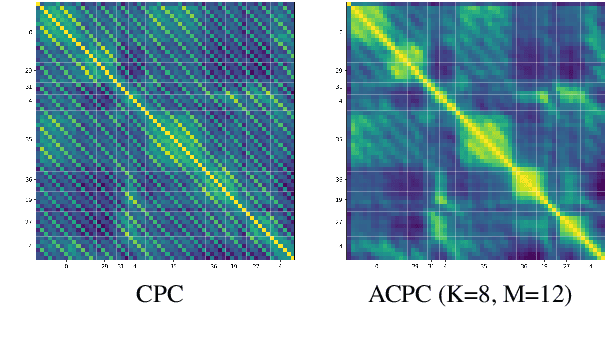
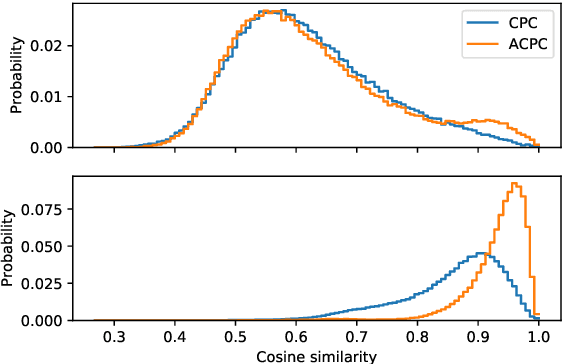
We investigate the possibility of forcing a self-supervised model trained using a contrastive predictive loss to extract slowly varying latent representations. Rather than producing individual predictions for each of the future representations, the model emits a sequence of predictions shorter than that of the upcoming representations to which they will be aligned. In this way, the prediction network solves a simpler task of predicting the next symbols, but not their exact timing, while the encoding network is trained to produce piece-wise constant latent codes. We evaluate the model on a speech coding task and demonstrate that the proposed Aligned Contrastive Predictive Coding (ACPC) leads to higher linear phone prediction accuracy and lower ABX error rates, while being slightly faster to train due to the reduced number of prediction heads.