 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinual learning on 3D point clouds with random compressed rehearsal
May 20, 2022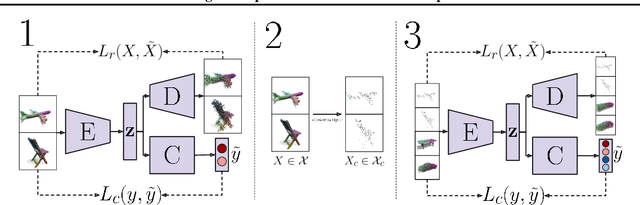

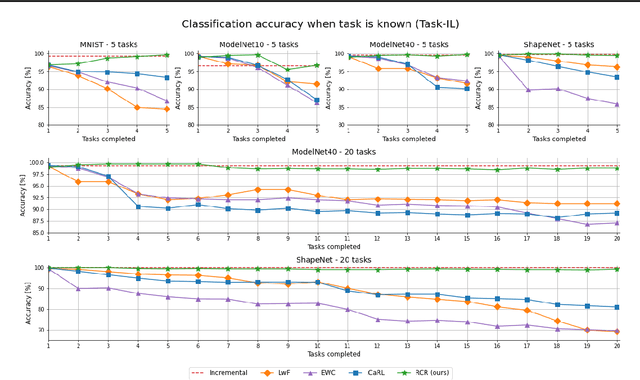

Contemporary deep neural networks offer state-of-the-art results when applied to visual reasoning, e.g., in the context of 3D point cloud data. Point clouds are important datatype for precise modeling of three-dimensional environments, but effective processing of this type of data proves to be challenging. In the world of large, heavily-parameterized network architectures and continuously-streamed data, there is an increasing need for machine learning models that can be trained on additional data. Unfortunately, currently available models cannot fully leverage training on additional data without losing their past knowledge. Combating this phenomenon, called catastrophic forgetting, is one of the main objectives of continual learning. Continual learning for deep neural networks has been an active field of research, primarily in 2D computer vision, natural language processing, reinforcement learning, and robotics. However, in 3D computer vision, there are hardly any continual learning solutions specifically designed to take advantage of point cloud structure. This work proposes a novel neural network architecture capable of continual learning on 3D point cloud data. We utilize point cloud structure properties for preserving a heavily compressed set of past data. By using rehearsal and reconstruction as regularization methods of the learning process, our approach achieves a significant decrease of catastrophic forgetting compared to the existing solutions on several most popular point cloud datasets considering two continual learning settings: when a task is known beforehand, and in the challenging scenario of when task information is unknown to the model.
Representing Point Clouds with Generative Conditional Invertible Flow Networks
Oct 07, 2020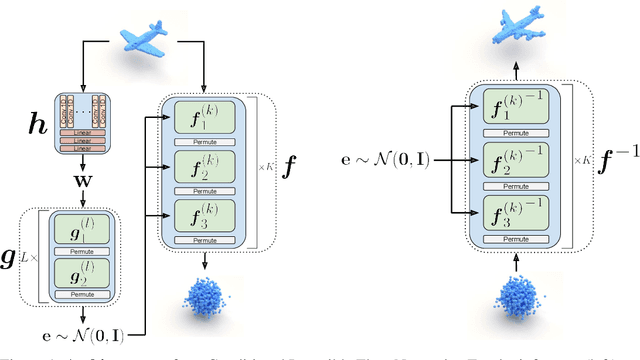
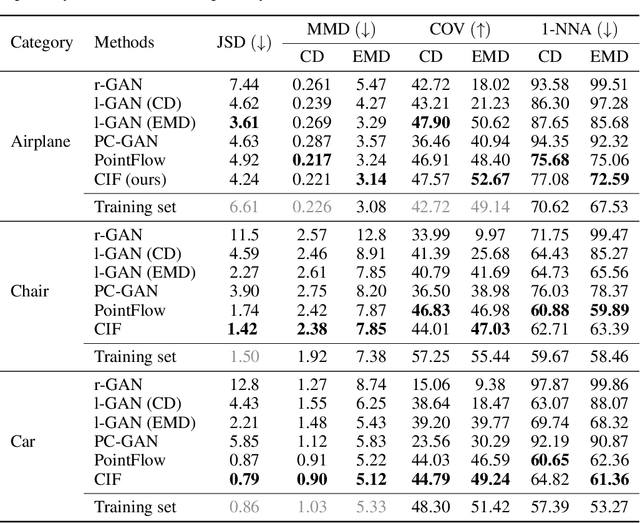


In this paper, we propose a simple yet effective method to represent point clouds as sets of samples drawn from a cloud-specific probability distribution. This interpretation matches intrinsic characteristics of point clouds: the number of points and their ordering within a cloud is not important as all points are drawn from the proximity of the object boundary. We postulate to represent each cloud as a parameterized probability distribution defined by a generative neural network. Once trained, such a model provides a natural framework for point cloud manipulation operations, such as aligning a new cloud into a default spatial orientation. To exploit similarities between same-class objects and to improve model performance, we turn to weight sharing: networks that model densities of points belonging to objects in the same family share all parameters with the exception of a small, object-specific embedding vector. We show that these embedding vectors capture semantic relationships between objects. Our method leverages generative invertible flow networks to learn embeddings as well as to generate point clouds. Thanks to this formulation and contrary to similar approaches, we are able to train our model in an end-to-end fashion. As a result, our model offers competitive or superior quantitative results on benchmark datasets, while enabling unprecedented capabilities to perform cloud manipulation tasks, such as point cloud registration and regeneration, by a generative network.
Hypernetwork approach to generating point clouds
Feb 10, 2020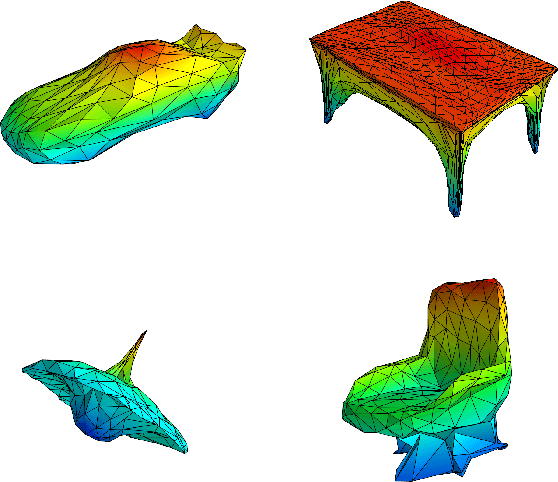
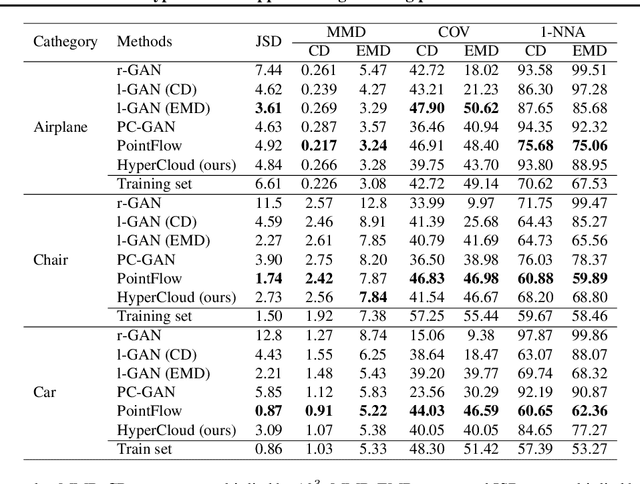
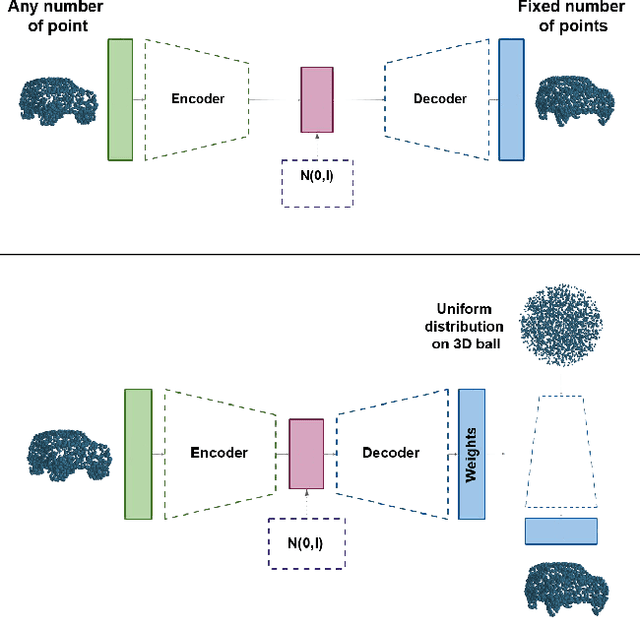

In this work, we propose a novel method for generating 3D point clouds that leverage properties of hyper networks. Contrary to the existing methods that learn only the representation of a 3D object, our approach simultaneously finds a representation of the object and its 3D surface. The main idea of our HyperCloud method is to build a hyper network that returns weights of a particular neural network (target network) trained to map points from a uniform unit ball distribution into a 3D shape. As a consequence, a particular 3D shape can be generated using point-by-point sampling from the assumed prior distribution and transforming sampled points with the target network. Since the hyper network is based on an auto-encoder architecture trained to reconstruct realistic 3D shapes, the target network weights can be considered a parametrization of the surface of a 3D shape, and not a standard representation of point cloud usually returned by competitive approaches. The proposed architecture allows finding mesh-based representation of 3D objects in a generative manner while providing point clouds en pair in quality with the state-of-the-art methods.
Conditional Invertible Flow for Point Cloud Generation
Oct 16, 2019
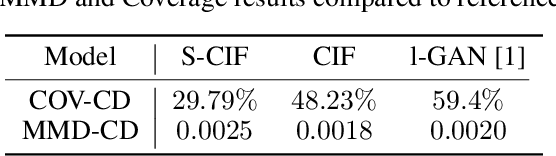

This paper focuses on a novel generative approach for 3D point clouds that makes use of invertible flow-based models. The main idea of the method is to treat a point cloud as a probability density in 3D space that is modeled using a cloud-specific neural network. To capture the similarity between point clouds we rely on parameter sharing among networks, with each cloud having only a small embedding vector that defines it. We use invertible flows networks to generate the individual point clouds, and to regularize the embedding vectors. We evaluate the generative capabilities of the model both in qualitative and quantitative manner.
Generative Adversarial Networks: recent developments
Mar 16, 2019In traditional generative modeling, good data representation is very often a base for a good machine learning model. It can be linked to good representations encoding more explanatory factors that are hidden in the original data. With the invention of Generative Adversarial Networks (GANs), a subclass of generative models that are able to learn representations in an unsupervised and semi-supervised fashion, we are now able to adversarially learn good mappings from a simple prior distribution to a target data distribution. This paper presents an overview of recent developments in GANs with a focus on learning latent space representations.
Semi-supervised learning with Bidirectional GANs
Nov 28, 2018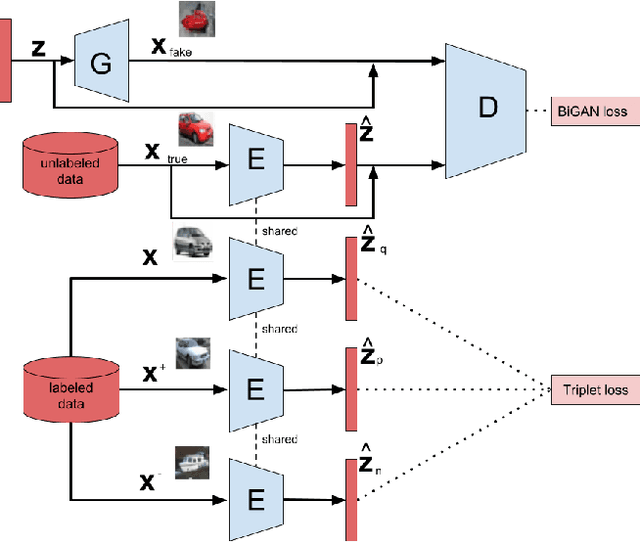


In this work we introduce a novel approach to train Bidirectional Generative Adversarial Model (BiGAN) in a semi-supervised manner. The presented method utilizes triplet loss function as an additional component of the objective function used to train discriminative data representation in the latent space of the BiGAN model. This representation can be further used as a seed for generating artificial images, but also as a good feature embedding for classification and image retrieval tasks. We evaluate the quality of the proposed method in the two mentioned challenging tasks using two benchmark datasets: CIFAR10 and SVHN.
Adversarial Autoencoders for Generating 3D Point Clouds
Nov 19, 2018
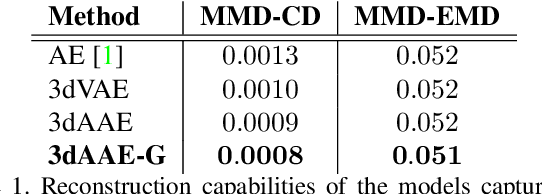
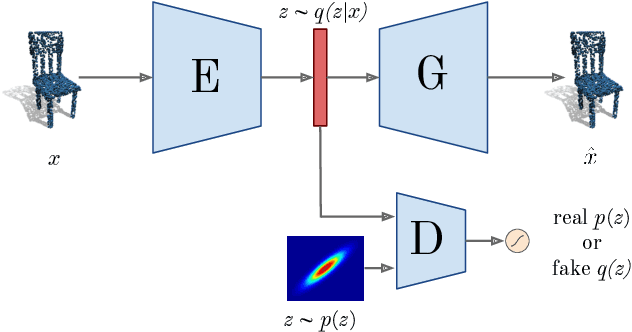

Deep generative architectures provide a way to model not only images, but also complex, 3-dimensional objects, such as point clouds. In this work, we present a novel method to obtain meaningful representations of 3D shapes that can be used for clustering and reconstruction. Contrary to existing methods for 3D point cloud generation that train separate decoupled models for representation learning and generation, our approach is the first end-to-end solution that allows to simultaneously learn a latent space of representation and generate 3D shape out of it. To achieve this goal, we extend a deep Adversarial Autoencoder model (AAE) to accept 3D input and create 3D output. Thanks to our end-to-end training regime, the resulting method called 3D Adversarial Autoencoder (3dAAE) obtains either binary or continuous latent space that covers much wider portion of training data distribution, hence allowing smooth interpolation between the shapes. Finally, our extensive quantitative evaluation shows that 3dAAE provides state-of-the-art results on a set of benchmark tasks.