 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling Uncertainty in Personalized Emotion Prediction with Normalizing Flows
Dec 10, 2023Designing predictive models for subjective problems in natural language processing (NLP) remains challenging. This is mainly due to its non-deterministic nature and different perceptions of the content by different humans. It may be solved by Personalized Natural Language Processing (PNLP), where the model exploits additional information about the reader to make more accurate predictions. However, current approaches require complete information about the recipients to be straight embedded. Besides, the recent methods focus on deterministic inference or simple frequency-based estimations of the probabilities. In this work, we overcome this limitation by proposing a novel approach to capture the uncertainty of the forecast using conditional Normalizing Flows. This allows us to model complex multimodal distributions and to compare various models using negative log-likelihood (NLL). In addition, the new solution allows for various interpretations of possible reader perception thanks to the available sampling function. We validated our method on three challenging, subjective NLP tasks, including emotion recognition and hate speech. The comparative analysis of generalized and personalized approaches revealed that our personalized solutions significantly outperform the baseline and provide more precise uncertainty estimates. The impact on the text interpretability and uncertainty studies are presented as well. The information brought by the developed methods makes it possible to build hybrid models whose effectiveness surpasses classic solutions. In addition, an analysis and visualization of the probabilities of the given decisions for texts with high entropy of annotations and annotators with mixed views were carried out.
Continual learning on 3D point clouds with random compressed rehearsal
May 20, 2022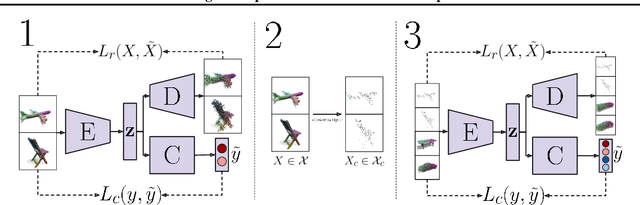

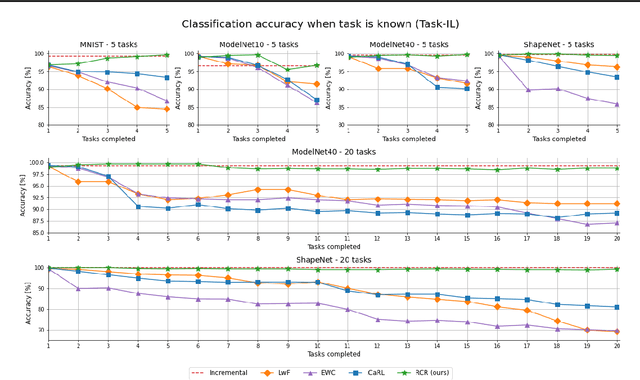

Contemporary deep neural networks offer state-of-the-art results when applied to visual reasoning, e.g., in the context of 3D point cloud data. Point clouds are important datatype for precise modeling of three-dimensional environments, but effective processing of this type of data proves to be challenging. In the world of large, heavily-parameterized network architectures and continuously-streamed data, there is an increasing need for machine learning models that can be trained on additional data. Unfortunately, currently available models cannot fully leverage training on additional data without losing their past knowledge. Combating this phenomenon, called catastrophic forgetting, is one of the main objectives of continual learning. Continual learning for deep neural networks has been an active field of research, primarily in 2D computer vision, natural language processing, reinforcement learning, and robotics. However, in 3D computer vision, there are hardly any continual learning solutions specifically designed to take advantage of point cloud structure. This work proposes a novel neural network architecture capable of continual learning on 3D point cloud data. We utilize point cloud structure properties for preserving a heavily compressed set of past data. By using rehearsal and reconstruction as regularization methods of the learning process, our approach achieves a significant decrease of catastrophic forgetting compared to the existing solutions on several most popular point cloud datasets considering two continual learning settings: when a task is known beforehand, and in the challenging scenario of when task information is unknown to the model.
HyperShot: Few-Shot Learning by Kernel HyperNetworks
Mar 21, 2022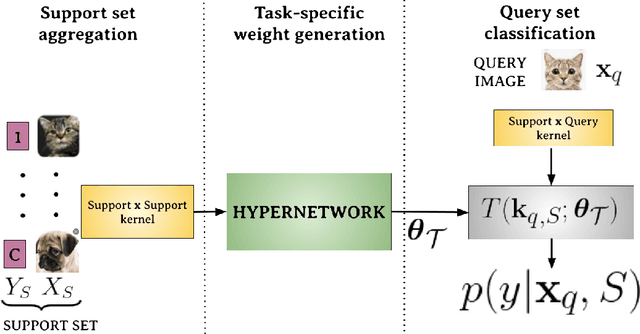
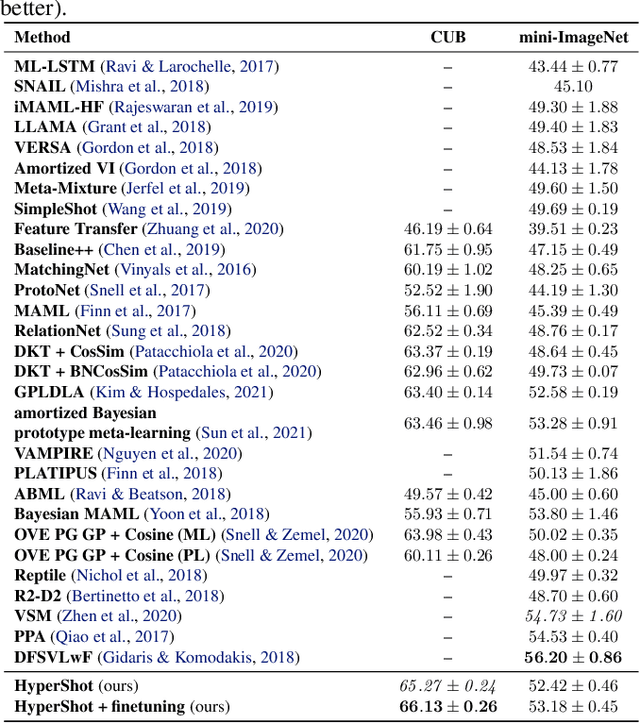
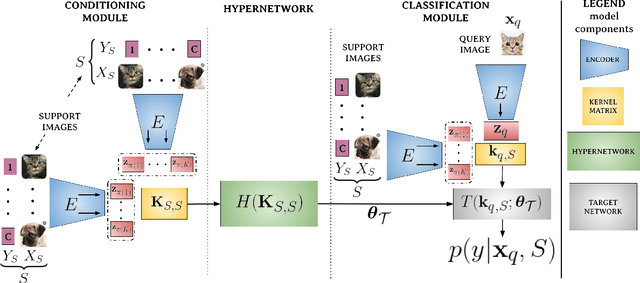
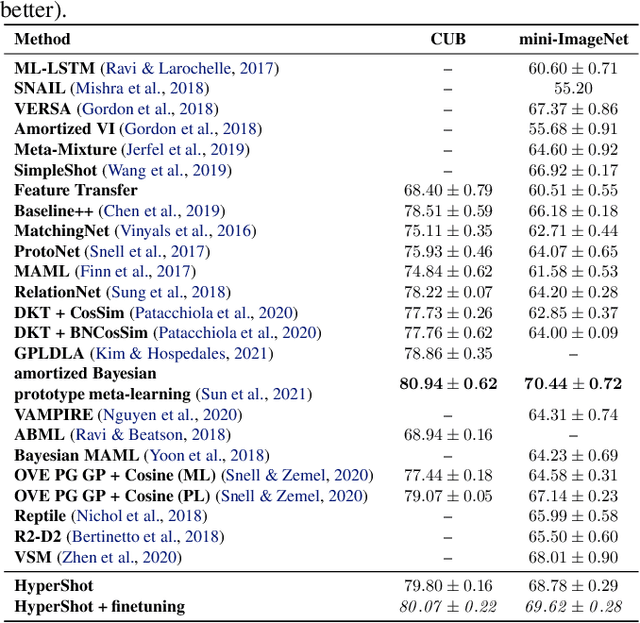
Few-shot models aim at making predictions using a minimal number of labeled examples from a given task. The main challenge in this area is the one-shot setting where only one element represents each class. We propose HyperShot - the fusion of kernels and hypernetwork paradigm. Compared to reference approaches that apply a gradient-based adjustment of the parameters, our model aims to switch the classification module parameters depending on the task's embedding. In practice, we utilize a hypernetwork, which takes the aggregated information from support data and returns the classifier's parameters handcrafted for the considered problem. Moreover, we introduce the kernel-based representation of the support examples delivered to hypernetwork to create the parameters of the classification module. Consequently, we rely on relations between embeddings of the support examples instead of direct feature values provided by the backbone models. Thanks to this approach, our model can adapt to highly different tasks.