 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Concept Anchoring for Interpretable and Controllable Neural Representations
Dec 13, 2025We introduce Sparse Concept Anchoring, a method that biases latent space to position a targeted subset of concepts while allowing others to self-organize, using only minimal supervision (labels for <0.1% of examples per anchored concept). Training combines activation normalization, a separation regularizer, and anchor or subspace regularizers that attract rare labeled examples to predefined directions or axis-aligned subspaces. The anchored geometry enables two practical interventions: reversible behavioral steering that projects out a concept's latent component at inference, and permanent removal via targeted weight ablation of anchored dimensions. Experiments on structured autoencoders show selective attenuation of targeted concepts with negligible impact on orthogonal features, and complete elimination with reconstruction error approaching theoretical bounds. Sparse Concept Anchoring therefore provides a practical pathway to interpretable, steerable behavior in learned representations.
Unifying Perspectives: Plausible Counterfactual Explanations on Global, Group-wise, and Local Levels
May 27, 2024Growing regulatory and societal pressures demand increased transparency in AI, particularly in understanding the decisions made by complex machine learning models. Counterfactual Explanations (CFs) have emerged as a promising technique within Explainable AI (xAI), offering insights into individual model predictions. However, to understand the systemic biases and disparate impacts of AI models, it is crucial to move beyond local CFs and embrace global explanations, which offer a~holistic view across diverse scenarios and populations. Unfortunately, generating Global Counterfactual Explanations (GCEs) faces challenges in computational complexity, defining the scope of "global," and ensuring the explanations are both globally representative and locally plausible. We introduce a novel unified approach for generating Local, Group-wise, and Global Counterfactual Explanations for differentiable classification models via gradient-based optimization to address these challenges. This framework aims to bridge the gap between individual and systemic insights, enabling a deeper understanding of model decisions and their potential impact on diverse populations. Our approach further innovates by incorporating a probabilistic plausibility criterion, enhancing actionability and trustworthiness. By offering a cohesive solution to the optimization and plausibility challenges in GCEs, our work significantly advances the interpretability and accountability of AI models, marking a step forward in the pursuit of transparent AI.
Probabilistically Plausible Counterfactual Explanations with Normalizing Flows
May 27, 2024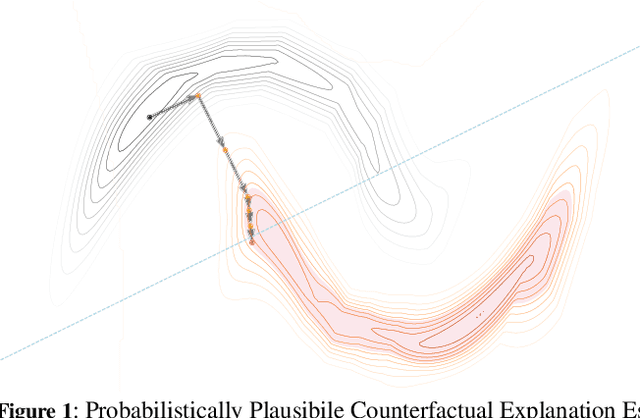
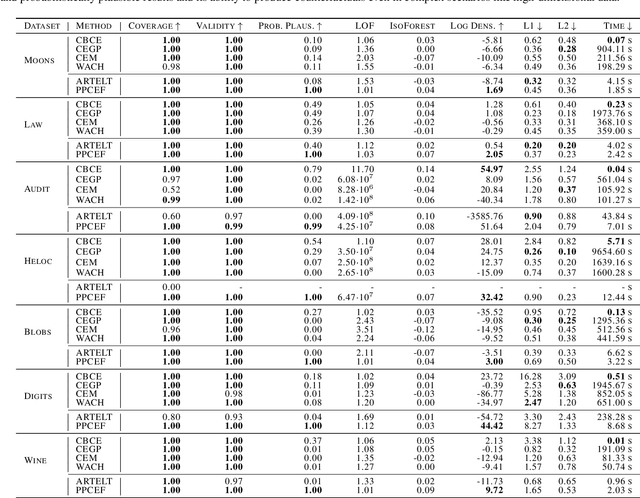
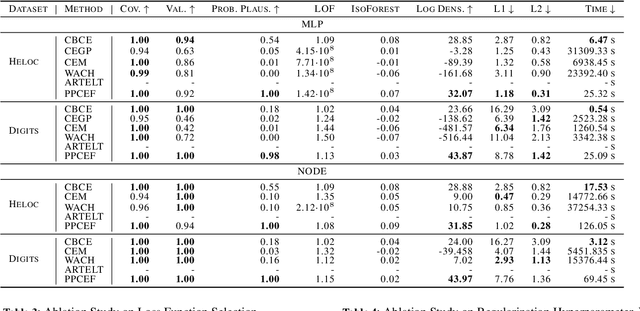
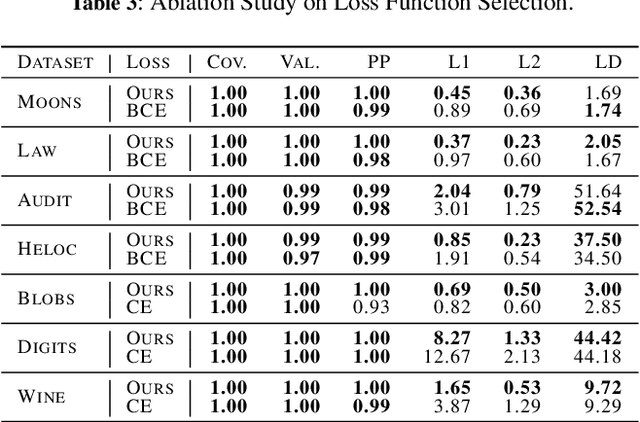
We present PPCEF, a novel method for generating probabilistically plausible counterfactual explanations (CFs). PPCEF advances beyond existing methods by combining a probabilistic formulation that leverages the data distribution with the optimization of plausibility within a unified framework. Compared to reference approaches, our method enforces plausibility by directly optimizing the explicit density function without assuming a particular family of parametrized distributions. This ensures CFs are not only valid (i.e., achieve class change) but also align with the underlying data's probability density. For that purpose, our approach leverages normalizing flows as powerful density estimators to capture the complex high-dimensional data distribution. Furthermore, we introduce a novel loss that balances the trade-off between achieving class change and maintaining closeness to the original instance while also incorporating a probabilistic plausibility term. PPCEF's unconstrained formulation allows for efficient gradient-based optimization with batch processing, leading to orders of magnitude faster computation compared to prior methods. Moreover, the unconstrained formulation of PPCEF allows for the seamless integration of future constraints tailored to specific counterfactual properties. Finally, extensive evaluations demonstrate PPCEF's superiority in generating high-quality, probabilistically plausible counterfactual explanations in high-dimensional tabular settings. This makes PPCEF a powerful tool for not only interpreting complex machine learning models but also for improving fairness, accountability, and trust in AI systems.
Modeling Uncertainty in Personalized Emotion Prediction with Normalizing Flows
Dec 10, 2023Designing predictive models for subjective problems in natural language processing (NLP) remains challenging. This is mainly due to its non-deterministic nature and different perceptions of the content by different humans. It may be solved by Personalized Natural Language Processing (PNLP), where the model exploits additional information about the reader to make more accurate predictions. However, current approaches require complete information about the recipients to be straight embedded. Besides, the recent methods focus on deterministic inference or simple frequency-based estimations of the probabilities. In this work, we overcome this limitation by proposing a novel approach to capture the uncertainty of the forecast using conditional Normalizing Flows. This allows us to model complex multimodal distributions and to compare various models using negative log-likelihood (NLL). In addition, the new solution allows for various interpretations of possible reader perception thanks to the available sampling function. We validated our method on three challenging, subjective NLP tasks, including emotion recognition and hate speech. The comparative analysis of generalized and personalized approaches revealed that our personalized solutions significantly outperform the baseline and provide more precise uncertainty estimates. The impact on the text interpretability and uncertainty studies are presented as well. The information brought by the developed methods makes it possible to build hybrid models whose effectiveness surpasses classic solutions. In addition, an analysis and visualization of the probabilities of the given decisions for texts with high entropy of annotations and annotators with mixed views were carried out.
TreeFlow: Going beyond Tree-based Gaussian Probabilistic Regression
Jun 08, 2022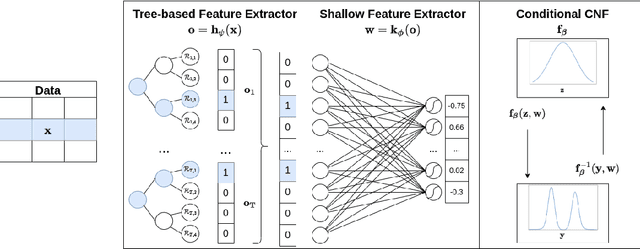
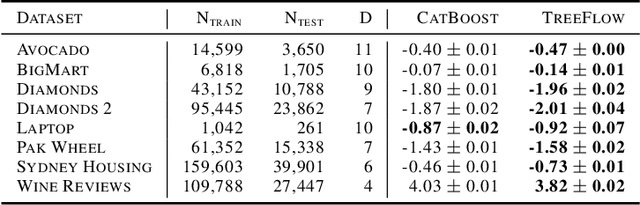

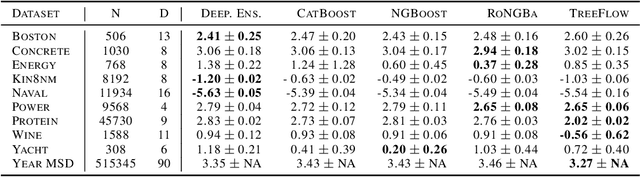
The tree-based ensembles are known for their outstanding performance for classification and regression problems characterized by feature vectors represented by mixed-type variables from various ranges and domains. However, considering regression problems, they are primarily designed to provide deterministic responses or model the uncertainty of the output with a Gaussian distribution. In this work, we introduce TreeFlow, the tree-based approach that combines the benefits of using tree ensembles with capabilities of modeling flexible probability distributions using normalizing flows. The main idea of the solution is to use a tree-based model as a feature extractor and combine it with a conditional variant of normalizing flow. Consequently, our approach is capable of modeling complex distributions for the regression outputs. We evaluate the proposed method on challenging regression benchmarks with varying volume, feature characteristics, and target dimensionality. We obtain the SOTA results on datasets with non-gaussian target distributions and competitive results on gaussian ones compared to tree-based regression baselines.
Flow Plugin Network for conditional generation
Oct 07, 2021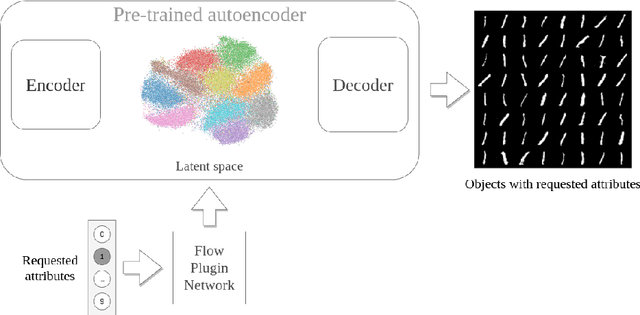
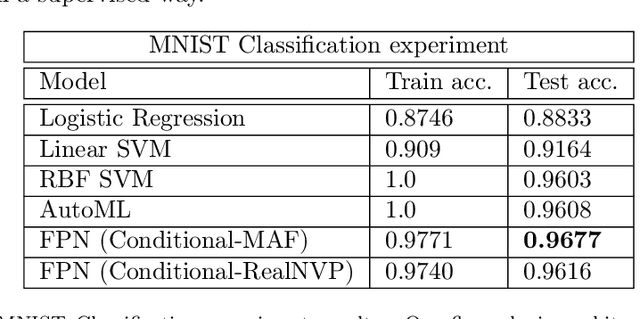
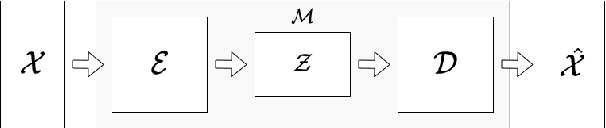
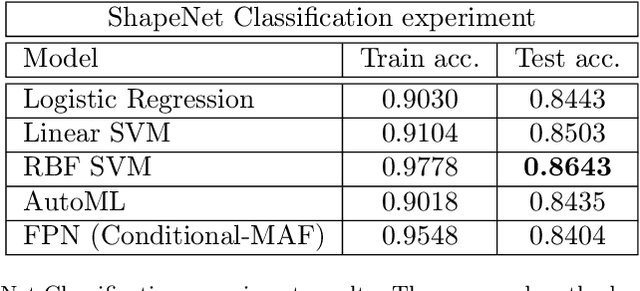
Generative models have gained many researchers' attention in the last years resulting in models such as StyleGAN for human face generation or PointFlow for the 3D point cloud generation. However, by default, we cannot control its sampling process, i.e., we cannot generate a sample with a specific set of attributes. The current approach is model retraining with additional inputs and different architecture, which requires time and computational resources. We propose a novel approach that enables to a generation of objects with a given set of attributes without retraining the base model. For this purpose, we utilize the normalizing flow models - Conditional Masked Autoregressive Flow and Conditional Real NVP, as a Flow Plugin Network (FPN).
PluGeN: Multi-Label Conditional Generation From Pre-Trained Models
Sep 18, 2021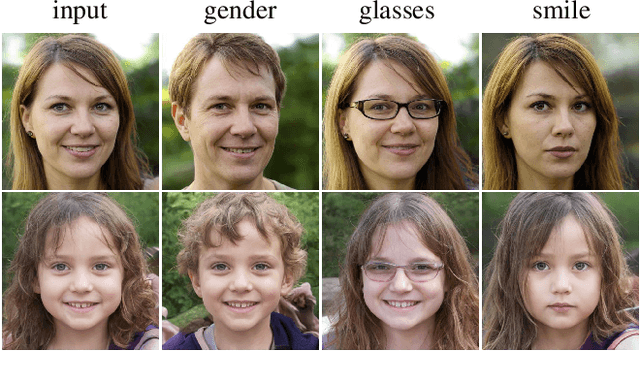
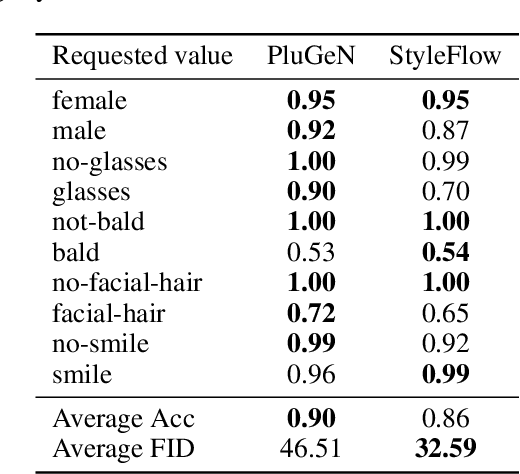
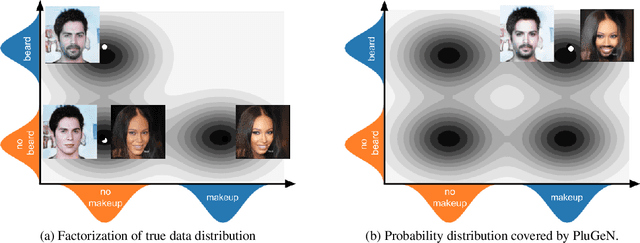
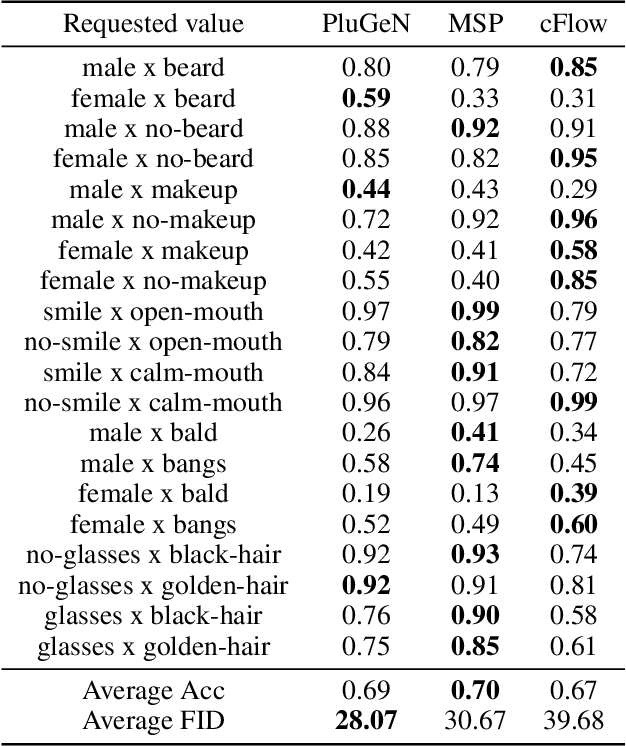
Modern generative models achieve excellent quality in a variety of tasks including image or text generation and chemical molecule modeling. However, existing methods often lack the essential ability to generate examples with requested properties, such as the age of the person in the photo or the weight of the generated molecule. Incorporating such additional conditioning factors would require rebuilding the entire architecture and optimizing the parameters from scratch. Moreover, it is difficult to disentangle selected attributes so that to perform edits of only one attribute while leaving the others unchanged. To overcome these limitations we propose PluGeN (Plugin Generative Network), a simple yet effective generative technique that can be used as a plugin to pre-trained generative models. The idea behind our approach is to transform the entangled latent representation using a flow-based module into a multi-dimensional space where the values of each attribute are modeled as an independent one-dimensional distribution. In consequence, PluGeN can generate new samples with desired attributes as well as manipulate labeled attributes of existing examples. Due to the disentangling of the latent representation, we are even able to generate samples with rare or unseen combinations of attributes in the dataset, such as a young person with gray hair, men with make-up, or women with beards. We combined PluGeN with GAN and VAE models and applied it to conditional generation and manipulation of images and chemical molecule modeling. Experiments demonstrate that PluGeN preserves the quality of backbone models while adding the ability to control the values of labeled attributes.