 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasoning4Sciences: Bridging Reasoning Language Models to All Scientific Branches
May 31, 2026While Reasoning Language Models (RLMs) are rapidly emerging as powerful tools for scientific research, their impact is primarily concentrated in "hard science" fields. The slow -- or lack of -- adoption of RLMs in other branches of science is causing a widening gap in research productivity. In this survey, we provide the first comprehensive analysis of RLM adoption across 28 scientific disciplines following the classification used by the European Research Council (ERC), spanning the Social Sciences and Humanities, Physical Sciences and Engineering, and Life Sciences. We examine how RLMs are developed, evaluated, and applied across disciplines. Furthermore, we introduce a maturity-oriented assessment framework based on available domain-specific development and evaluation resources, revealing substantial disparities in RLM maturity that become even more pronounced when only publicly available resources are considered. Finally, we highlight current implementation paradigms that are gaining popularity across disciplines, current challenges, and future directions in enabling RLM adoption across science.
What properties of reasoning supervision are associated with improved downstream model quality?
May 13, 2026Validating training data for reasoning models typically requires expensive trial-and-error fine-tuning cycles. In this work, we investigate whether the utility of a reasoning dataset can be reliably predicted prior to training using intrinsic data metrics. We propose a suite of quantitative measures and evaluate their predictive power by fine-tuning 8B and 11B models on semantically distinct variants of a Polish reasoning dataset. Our analysis reveals that these intrinsic metrics demonstrate strong and significant correlations with downstream model performance. Crucially, we find that the predictors of utility are scale-dependent: smaller models rely on alignment-focused metrics to ensure precision, whereas larger models benefit from high redundancy, utilizing verbose traces to solve complex tasks. These findings establish a scale-aware framework for validating reasoning data, enabling practitioners to select effective training sets without the need for exhaustive empirical testing.
How Annotation Trains Annotators: Competence Development in Social Influence Recognition
Apr 03, 2026Human data annotation, especially when involving experts, is often treated as an objective reference. However, many annotation tasks are inherently subjective, and annotators' judgments may evolve over time. This study investigates changes in the quality of annotators' work from a competence perspective during a process of social influence recognition. The study involved 25 annotators from five different groups, including both experts and non-experts, who annotated a dataset of 1,021 dialogues with 20 social influence techniques, along with intentions, reactions, and consequences. An initial subset of 150 texts was annotated twice - before and after the main annotation process - to enable comparison. To measure competence shifts, we combined qualitative and quantitative analyses of the annotated data, semi-structured interviews with annotators, self-assessment surveys, and Large Language Model training and evaluation on the comparison dataset. The results indicate a significant increase in annotators' self-perceived competence and confidence. Moreover, observed changes in data quality suggest that the annotation process may enhance annotator competence and that this effect is more pronounced in expert groups. The observed shifts in annotator competence have a visible impact on the performance of LLMs trained on their annotated data.
PLLuM: A Family of Polish Large Language Models
Nov 05, 2025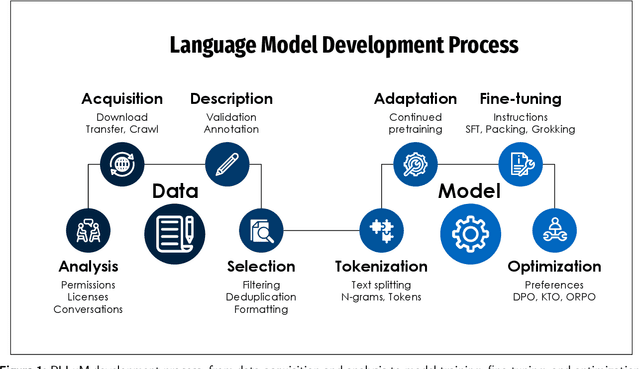
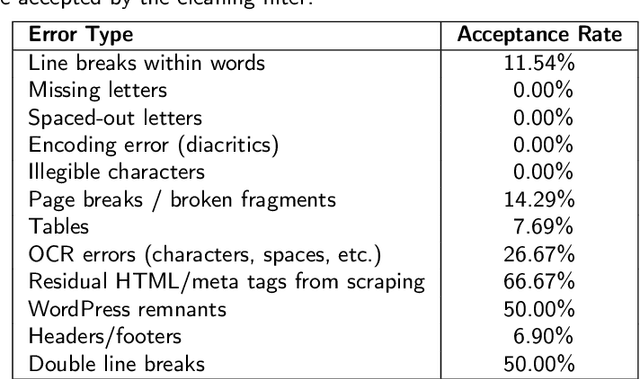
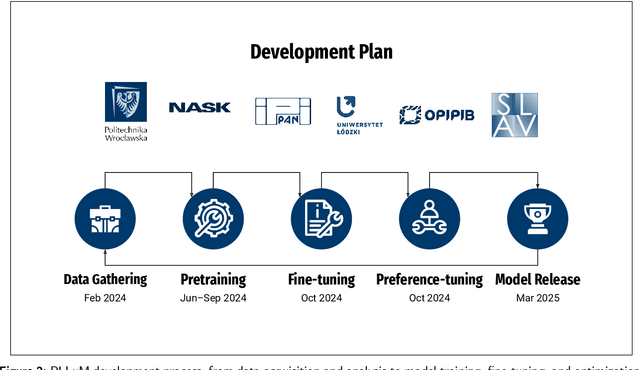

Large Language Models (LLMs) play a central role in modern artificial intelligence, yet their development has been primarily focused on English, resulting in limited support for other languages. We present PLLuM (Polish Large Language Model), the largest open-source family of foundation models tailored specifically for the Polish language. Developed by a consortium of major Polish research institutions, PLLuM addresses the need for high-quality, transparent, and culturally relevant language models beyond the English-centric commercial landscape. We describe the development process, including the construction of a new 140-billion-token Polish text corpus for pre-training, a 77k custom instructions dataset, and a 100k preference optimization dataset. A key component is a Responsible AI framework that incorporates strict data governance and a hybrid module for output correction and safety filtering. We detail the models' architecture, training procedures, and alignment techniques for both base and instruction-tuned variants, and demonstrate their utility in a downstream task within public administration. By releasing these models publicly, PLLuM aims to foster open research and strengthen sovereign AI technologies in Poland.
Eagle and Finch: RWKV with Matrix-Valued States and Dynamic Recurrence
Apr 10, 2024



We present Eagle (RWKV-5) and Finch (RWKV-6), sequence models improving upon the RWKV (RWKV-4) architecture. Our architectural design advancements include multi-headed matrix-valued states and a dynamic recurrence mechanism that improve expressivity while maintaining the inference efficiency characteristics of RNNs. We introduce a new multilingual corpus with 1.12 trillion tokens and a fast tokenizer based on greedy matching for enhanced multilinguality. We trained four Eagle models, ranging from 0.46 to 7.5 billion parameters, and two Finch models with 1.6 and 3.1 billion parameters and find that they achieve competitive performance across a wide variety of benchmarks. We release all our models on HuggingFace under the Apache 2.0 license. Models at: https://huggingface.co/RWKV Training code at: https://github.com/RWKV/RWKV-LM Inference code at: https://github.com/RWKV/ChatRWKV Time-parallel training code at: https://github.com/RWKV/RWKV-infctx-trainer
Into the Unknown: Self-Learning Large Language Models
Feb 14, 2024We address the main problem of self-learning LLM: the question of what to learn. We propose a self-learning LLM framework that enables an LLM to independently learn previously unknown knowledge through self-assessment of their own hallucinations. Using the hallucination score, we introduce a new concept of Points in The Unknown (PiUs), along with one extrinsic and three intrinsic methods for automatic PiUs identification. It facilitates the creation of a self-learning loop that focuses exclusively on the knowledge gap in Points in The Unknown, resulting in a reduced hallucination score. We also developed evaluation metrics for gauging an LLM's self-learning capability. Our experiments revealed that 7B-Mistral models that have been finetuned or aligned are capable of self-learning considerably well. Our self-learning concept allows more efficient LLM updates and opens new perspectives for knowledge exchange. It may also increase public trust in AI.
Personalized Large Language Models
Feb 14, 2024



Large language models (LLMs) have significantly advanced Natural Language Processing (NLP) tasks in recent years. However, their universal nature poses limitations in scenarios requiring personalized responses, such as recommendation systems and chatbots. This paper investigates methods to personalize LLMs, comparing fine-tuning and zero-shot reasoning approaches on subjective tasks. Results demonstrate that personalized fine-tuning improves model reasoning compared to non-personalized models. Experiments on datasets for emotion recognition and hate speech detection show consistent performance gains with personalized methods across different LLM architectures. These findings underscore the importance of personalization for enhancing LLM capabilities in subjective text perception tasks.
From Generalized Laughter to Personalized Chuckles: Unleashing the Power of Data Fusion in Subjective Humor Detection
Dec 18, 2023



The vast area of subjectivity in Natural Language Processing (NLP) poses a challenge to the solutions typically used in generalized tasks. As exploration in the scope of generalized NLP is much more advanced, it implies the tremendous gap that is still to be addressed amongst all feasible tasks where an opinion, taste, or feelings are inherent, thus creating a need for a solution, where a data fusion could take place. We have chosen the task of funniness, as it heavily relies on the sense of humor, which is fundamentally subjective. Our experiments across five personalized and four generalized datasets involving several personalized deep neural architectures have shown that the task of humor detection greatly benefits from the inclusion of personalized data in the training process. We tested five scenarios of training data fusion that focused on either generalized (majority voting) or personalized approaches to humor detection. The best results were obtained for the setup, in which all available personalized datasets were joined to train the personalized reasoning model. It boosted the prediction performance by up to approximately 35% of the macro F1 score. Such a significant gain was observed for all five personalized test sets. At the same time, the impact of the model's architecture was much less than the personalization itself. It seems that concatenating personalized datasets, even with the cost of normalizing the range of annotations across all datasets, if combined with the personalized models, results in an enormous increase in the performance of humor detection.
Towards Model-Based Data Acquisition for Subjective Multi-Task NLP Problems
Dec 13, 2023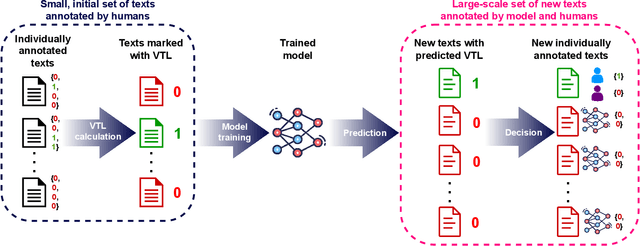
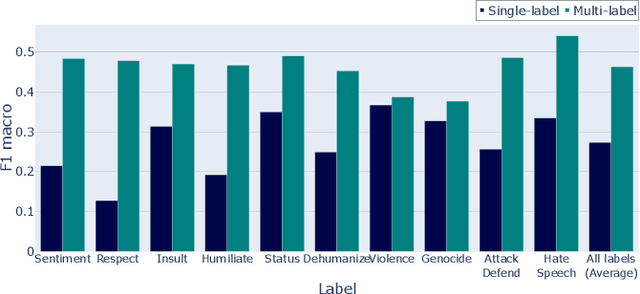
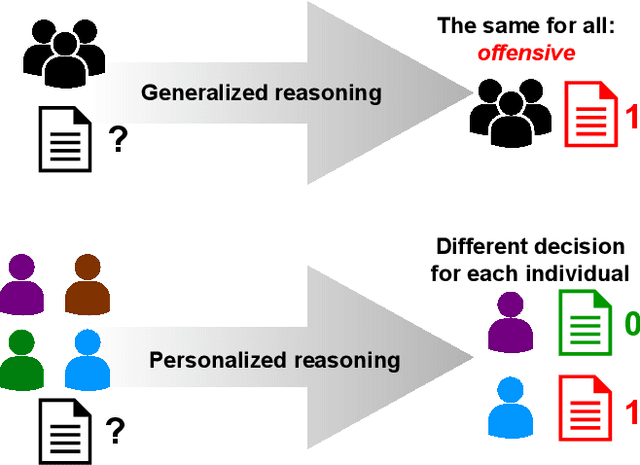
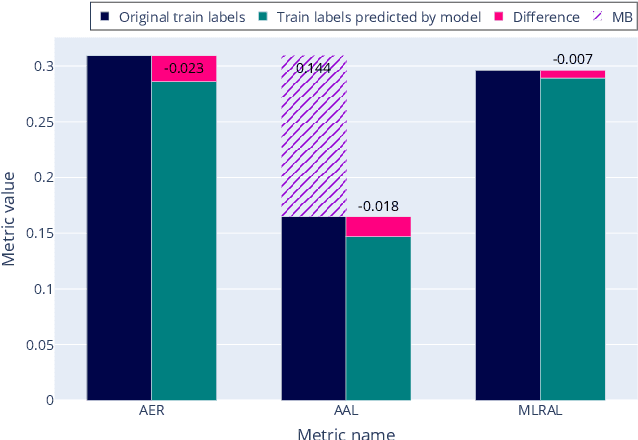
Data annotated by humans is a source of knowledge by describing the peculiarities of the problem and therefore fueling the decision process of the trained model. Unfortunately, the annotation process for subjective natural language processing (NLP) problems like offensiveness or emotion detection is often very expensive and time-consuming. One of the inevitable risks is to spend some of the funds and annotator effort on annotations that do not provide any additional knowledge about the specific task. To minimize these costs, we propose a new model-based approach that allows the selection of tasks annotated individually for each text in a multi-task scenario. The experiments carried out on three datasets, dozens of NLP tasks, and thousands of annotations show that our method allows up to 40% reduction in the number of annotations with negligible loss of knowledge. The results also emphasize the need to collect a diverse amount of data required to efficiently train a model, depending on the subjectivity of the annotation task. We also focused on measuring the relation between subjective tasks by evaluating the model in single-task and multi-task scenarios. Moreover, for some datasets, training only on the labels predicted by our model improved the efficiency of task selection as a self-supervised learning regularization technique.
Modeling Uncertainty in Personalized Emotion Prediction with Normalizing Flows
Dec 10, 2023Designing predictive models for subjective problems in natural language processing (NLP) remains challenging. This is mainly due to its non-deterministic nature and different perceptions of the content by different humans. It may be solved by Personalized Natural Language Processing (PNLP), where the model exploits additional information about the reader to make more accurate predictions. However, current approaches require complete information about the recipients to be straight embedded. Besides, the recent methods focus on deterministic inference or simple frequency-based estimations of the probabilities. In this work, we overcome this limitation by proposing a novel approach to capture the uncertainty of the forecast using conditional Normalizing Flows. This allows us to model complex multimodal distributions and to compare various models using negative log-likelihood (NLL). In addition, the new solution allows for various interpretations of possible reader perception thanks to the available sampling function. We validated our method on three challenging, subjective NLP tasks, including emotion recognition and hate speech. The comparative analysis of generalized and personalized approaches revealed that our personalized solutions significantly outperform the baseline and provide more precise uncertainty estimates. The impact on the text interpretability and uncertainty studies are presented as well. The information brought by the developed methods makes it possible to build hybrid models whose effectiveness surpasses classic solutions. In addition, an analysis and visualization of the probabilities of the given decisions for texts with high entropy of annotations and annotators with mixed views were carried out.