 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAffect Decoding in Phonated and Silent Speech Production from Surface EMG
Mar 12, 2026The expression of affect is integral to spoken communication, yet, its link to underlying articulatory execution remains unclear. Measures of articulatory muscle activity such as EMG could reveal how speech production is modulated by emotion alongside acoustic speech analyses. We investigate affect decoding from facial and neck surface electromyography (sEMG) during phonated and silent speech production. For this purpose, we introduce a dataset comprising 2,780 utterances from 12 participants across 3 tasks, on which we evaluate both intra- and inter-subject decoding using a range of features and model embeddings. Our results reveal that EMG representations reliably discriminate frustration with up to 0.845 AUC, and generalize well across articulation modes. Our ablation study further demonstrates that affective signatures are embedded in facial motor activity and persist in the absence of phonation, highlighting the potential of EMG sensing for affect-aware silent speech interfaces.
Encoding Emotion Through Self-Supervised Eye Movement Reconstruction
Jan 21, 2026The relationship between emotional expression and eye movement is well-documented, with literature establishing gaze patterns are reliable indicators of emotion. However, most studies utilize specialized, high-resolution eye-tracking equipment, limiting the potential reach of findings. We investigate how eye movement can be used to predict multimodal markers of emotional expression from naturalistic, low-resolution videos. We utilize a collection of video interviews from the USC Shoah Foundation's Visual History Archive with Holocaust survivors as they recount their experiences in the Auschwitz concentration camp. Inspired by pretraining methods on language models, we develop a novel gaze detection model that uses self-supervised eye movement reconstruction that can effectively leverage unlabeled video. We use this model's encoder embeddings to fine-tune models on two downstream tasks related to emotional expression. The first is aligning eye movement with directional emotion estimates from speech. The second task is using eye gaze as a predictor of three momentary manifestations of emotional behaviors: laughing, crying/sobbing, and sighing. We find our new model is predictive of emotion outcomes and observe a positive correlation between pretraining performance and emotion processing performance for both experiments. We conclude self-supervised eye movement reconstruction is an effective method for encoding the affective signal they carry.
Informed Bootstrap Augmentation Improves EEG Decoding
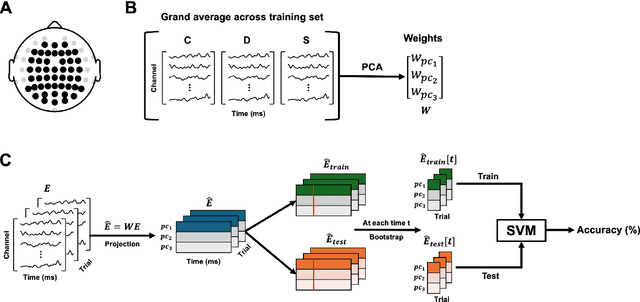
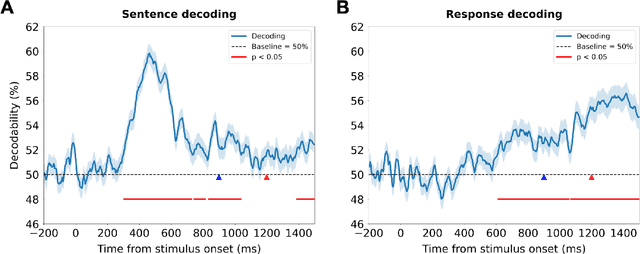
Nov 15, 2025Electroencephalography (EEG) offers detailed access to neural dynamics but remains constrained by noise and trial-by-trial variability, limiting decoding performance in data-restricted or complex paradigms. Data augmentation is often employed to enhance feature representations, yet conventional uniform averaging overlooks differences in trial informativeness and can degrade representational quality. We introduce a weighted bootstrapping approach that prioritizes more reliable trials to generate higher-quality augmented samples. In a Sentence Evaluation paradigm, weights were computed from relative ERP differences and applied during probabilistic sampling and averaging. Across conditions, weighted bootstrapping improved decoding accuracy relative to unweighted (from 68.35% to 71.25% at best), demonstrating that emphasizing reliable trials strengthens representational quality. The results demonstrate that reliability-based augmentation yields more robust and discriminative EEG representations. The code is publicly available at https://github.com/lyricists/NeuroBootstrap.
Decoding Neural Signatures of Semantic Evaluations in Depression and Suicidality
Jul 30, 2025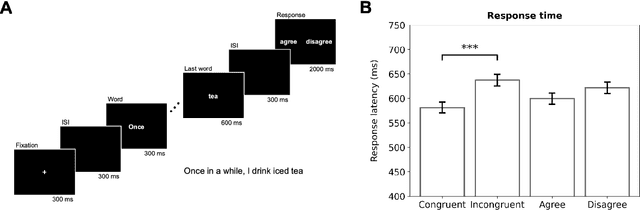
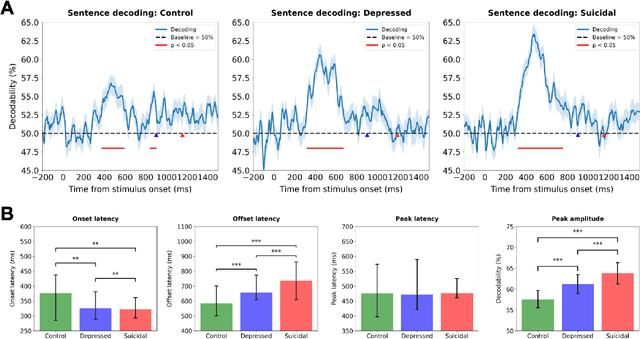
Depression and suicidality profoundly impact cognition and emotion, yet objective neurophysiological biomarkers remain elusive. We investigated the spatiotemporal neural dynamics underlying affective semantic processing in individuals with varying levels of clinical severity of depression and suicidality using multivariate decoding of electroencephalography (EEG) data. Participants (N=137) completed a sentence evaluation task involving emotionally charged self-referential statements while EEG was recorded. We identified robust, neural signatures of semantic processing, with peak decoding accuracy between 300-600 ms -- a window associated with automatic semantic evaluation and conflict monitoring. Compared to healthy controls, individuals with depression and suicidality showed earlier onset, longer duration, and greater amplitude decoding responses, along with broader cross-temporal generalization and increased activation of frontocentral and parietotemporal components. These findings suggest altered sensitivity and impaired disengagement from emotionally salient content in the clinical groups, advancing our understanding of the neurocognitive basis of mental health and providing a principled basis for developing reliable EEG-based biomarkers of depression and suicidality.
Neural Responses to Affective Sentences Reveal Signatures of Depression
Jun 06, 2025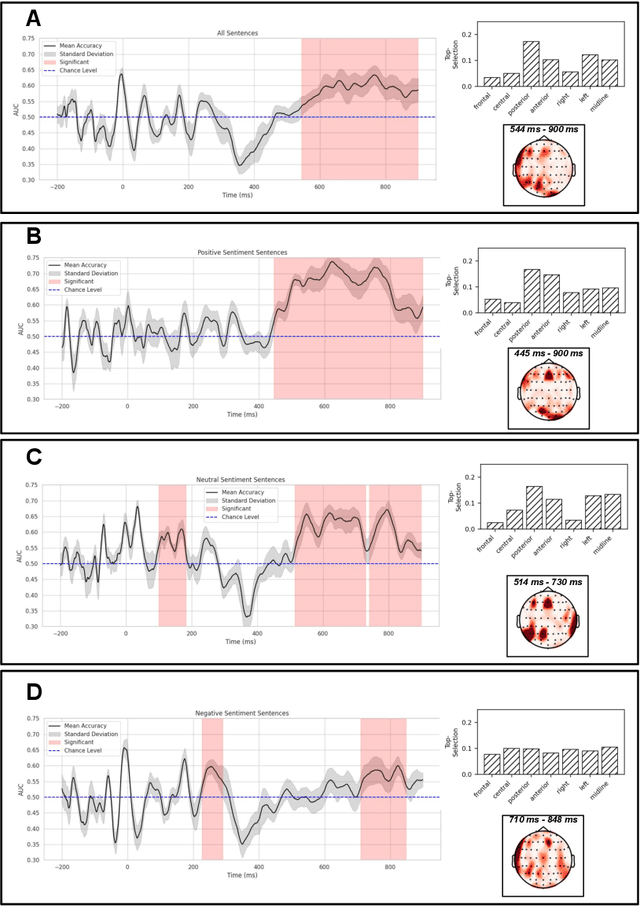
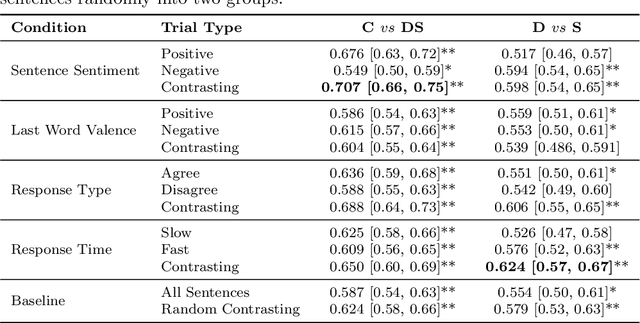
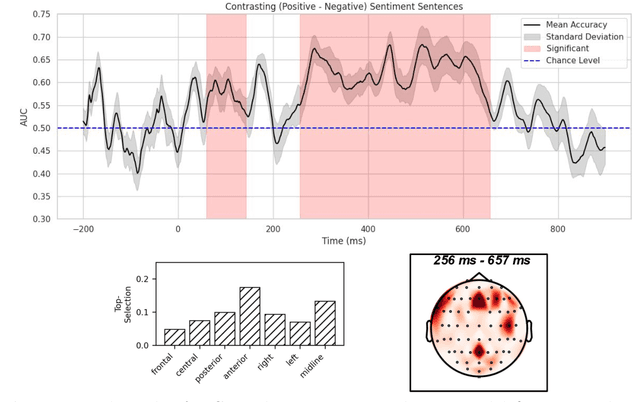

Major Depressive Disorder (MDD) is a highly prevalent mental health condition, and a deeper understanding of its neurocognitive foundations is essential for identifying how core functions such as emotional and self-referential processing are affected. We investigate how depression alters the temporal dynamics of emotional processing by measuring neural responses to self-referential affective sentences using surface electroencephalography (EEG) in healthy and depressed individuals. Our results reveal significant group-level differences in neural activity during sentence viewing, suggesting disrupted integration of emotional and self-referential information in depression. Deep learning model trained on these responses achieves an area under the receiver operating curve (AUC) of 0.707 in distinguishing healthy from depressed participants, and 0.624 in differentiating depressed subgroups with and without suicidal ideation. Spatial ablations highlight anterior electrodes associated with semantic and affective processing as key contributors. These findings suggest stable, stimulus-driven neural signatures of depression that may inform future diagnostic tools.
Articulatory Feature Prediction from Surface EMG during Speech Production
May 20, 2025



We present a model for predicting articulatory features from surface electromyography (EMG) signals during speech production. The proposed model integrates convolutional layers and a Transformer block, followed by separate predictors for articulatory features. Our approach achieves a high prediction correlation of approximately 0.9 for most articulatory features. Furthermore, we demonstrate that these predicted articulatory features can be decoded into intelligible speech waveforms. To our knowledge, this is the first method to decode speech waveforms from surface EMG via articulatory features, offering a novel approach to EMG-based speech synthesis. Additionally, we analyze the relationship between EMG electrode placement and articulatory feature predictability, providing knowledge-driven insights for optimizing EMG electrode configurations. The source code and decoded speech samples are publicly available.
Deep Learning Characterizes Depression and Suicidal Ideation from Eye Movements
Apr 29, 2025Identifying physiological and behavioral markers for mental health conditions is a longstanding challenge in psychiatry. Depression and suicidal ideation, in particular, lack objective biomarkers, with screening and diagnosis primarily relying on self-reports and clinical interviews. Here, we investigate eye tracking as a potential marker modality for screening purposes. Eye movements are directly modulated by neuronal networks and have been associated with attentional and mood-related patterns; however, their predictive value for depression and suicidality remains unclear. We recorded eye-tracking sequences from 126 young adults as they read and responded to affective sentences, and subsequently developed a deep learning framework to predict their clinical status. The proposed model included separate branches for trials of positive and negative sentiment, and used 2D time-series representations to account for both intra-trial and inter-trial variations. We were able to identify depression and suicidal ideation with an area under the receiver operating curve (AUC) of 0.793 (95% CI: 0.765-0.819) against healthy controls, and suicidality specifically with 0.826 AUC (95% CI: 0.797-0.852). The model also exhibited moderate, yet significant, accuracy in differentiating depressed from suicidal participants, with 0.609 AUC (95% CI 0.571-0.646). Discriminative patterns emerge more strongly when assessing the data relative to response generation than relative to the onset time of the final word of the sentences. The most pronounced effects were observed for negative-sentiment sentences, that are congruent to depressed and suicidal participants. Our findings highlight eye tracking as an objective tool for mental health assessment and underscore the modulatory impact of emotional stimuli on cognitive processes affecting oculomotor control.
Early Detection of Coffee Leaf Rust Through Convolutional Neural Networks Trained on Low-Resolution Images
Jul 20, 2024


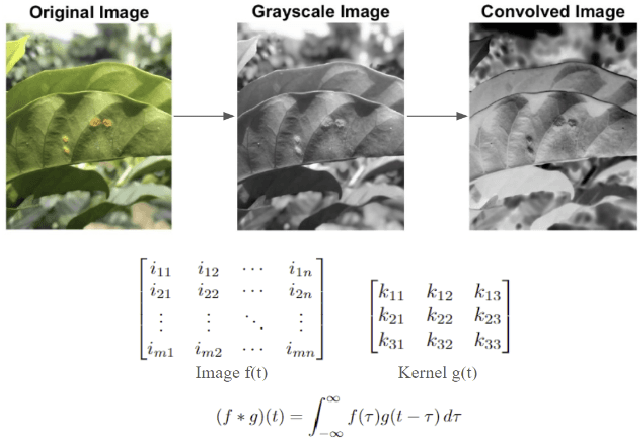
Coffee leaf rust, a foliar disease caused by the fungus Hemileia vastatrix, poses a major threat to coffee production, especially in Central America. Climate change further aggravates this issue, as it shortens the latency period between initial infection and the emergence of visible symptoms in diseases like leaf rust. Shortened latency periods can lead to more severe plant epidemics and faster spread of diseases. There is, hence, an urgent need for effective disease management strategies. To address these challenges, we explore the potential of deep learning models for enhancing early disease detection. However, deep learning models require extensive processing power and large amounts of data for model training, resources that are typically scarce. To overcome these barriers, we propose a preprocessing technique that involves convolving training images with a high-pass filter to enhance lesion-leaf contrast, significantly improving model efficacy in resource-limited environments. This method and our model demonstrated a strong performance, achieving over 90% across all evaluation metrics--including precision, recall, F1-score, and the Dice coefficient. Our experiments show that this approach outperforms other methods, including two different image preprocessing techniques and using unaltered, full-color images.
Toward Fully-End-to-End Listened Speech Decoding from EEG Signals
Jun 12, 2024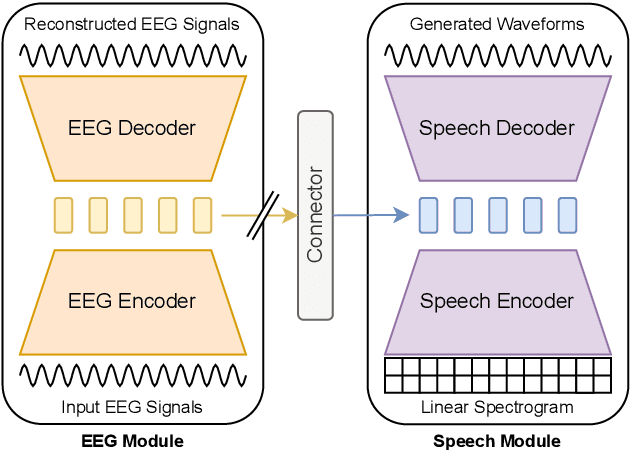



Speech decoding from EEG signals is a challenging task, where brain activity is modeled to estimate salient characteristics of acoustic stimuli. We propose FESDE, a novel framework for Fully-End-to-end Speech Decoding from EEG signals. Our approach aims to directly reconstruct listened speech waveforms given EEG signals, where no intermediate acoustic feature processing step is required. The proposed method consists of an EEG module and a speech module along with a connector. The EEG module learns to better represent EEG signals, while the speech module generates speech waveforms from model representations. The connector learns to bridge the distributions of the latent spaces of EEG and speech. The proposed framework is both simple and efficient, by allowing single-step inference, and outperforms prior works on objective metrics. A fine-grained phoneme analysis is conducted to unveil model characteristics of speech decoding. The source code is available here: github.com/lee-jhwn/fesde.
Evaluating Atypical Gaze Patterns through Vision Models: The Case of Cortical Visual Impairment
Feb 15, 2024

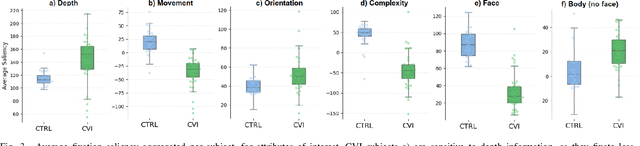
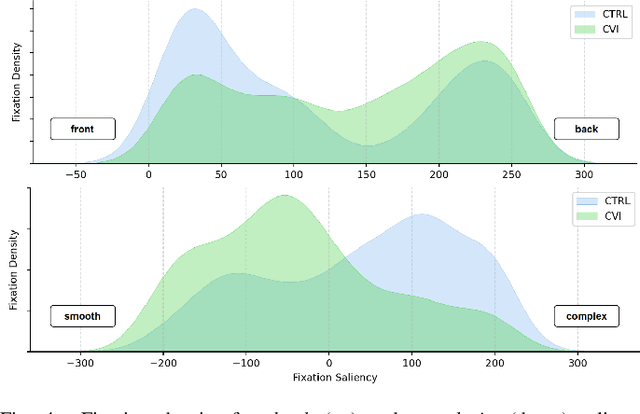
A wide range of neurological and cognitive disorders exhibit distinct behavioral markers aside from their clinical manifestations. Cortical Visual Impairment (CVI) is a prime example of such conditions, resulting from damage to visual pathways in the brain, and adversely impacting low- and high-level visual function. The characteristics impacted by CVI are primarily described qualitatively, challenging the establishment of an objective, evidence-based measure of CVI severity. To study those characteristics, we propose to create visual saliency maps by adequately prompting deep vision models with attributes of clinical interest. After extracting saliency maps for a curated set of stimuli, we evaluate fixation traces on those from children with CVI through eye tracking technology. Our experiments reveal significant gaze markers that verify clinical knowledge and yield nuanced discriminability when compared to those of age-matched control subjects. Using deep learning to unveil atypical visual saliency is an important step toward establishing an eye-tracking signature for severe neurodevelopmental disorders, like CVI.