 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Approach to Simultaneous Acquisition of Real-Time MRI Video, EEG, and Surface EMG for Articulatory, Brain, and Muscle Activity During Speech Production
Mar 05, 2026Speech production is a complex process spanning neural planning, motor control, muscle activation, and articulatory kinematics. While the acoustic speech signal is the most accessible product of the speech production act, it does not directly reveal its causal neurophysiological substrates. We present the first simultaneous acquisition of real-time (dynamic) MRI, EEG, and surface EMG, capturing several key aspects of the speech production chain: brain signals, muscle activations, and articulatory movements. This multimodal acquisition paradigm presents substantial technical challenges, including MRI-induced electromagnetic interference and myogenic artifacts. To mitigate these, we introduce an artifact suppression pipeline tailored to this tri-modal setting. Once fully developed, this framework is poised to offer an unprecedented window into speech neuroscience and insights leading to brain-computer interface advances.
Towards disentangling the contributions of articulation and acoustics in multimodal phoneme recognition
May 29, 2025Although many previous studies have carried out multimodal learning with real-time MRI data that captures the audio-visual kinematics of the vocal tract during speech, these studies have been limited by their reliance on multi-speaker corpora. This prevents such models from learning a detailed relationship between acoustics and articulation due to considerable cross-speaker variability. In this study, we develop unimodal audio and video models as well as multimodal models for phoneme recognition using a long-form single-speaker MRI corpus, with the goal of disentangling and interpreting the contributions of each modality. Audio and multimodal models show similar performance on different phonetic manner classes but diverge on places of articulation. Interpretation of the models' latent space shows similar encoding of the phonetic space across audio and multimodal models, while the models' attention weights highlight differences in acoustic and articulatory timing for certain phonemes.
Articulatory Feature Prediction from Surface EMG during Speech Production
May 20, 2025



We present a model for predicting articulatory features from surface electromyography (EMG) signals during speech production. The proposed model integrates convolutional layers and a Transformer block, followed by separate predictors for articulatory features. Our approach achieves a high prediction correlation of approximately 0.9 for most articulatory features. Furthermore, we demonstrate that these predicted articulatory features can be decoded into intelligible speech waveforms. To our knowledge, this is the first method to decode speech waveforms from surface EMG via articulatory features, offering a novel approach to EMG-based speech synthesis. Additionally, we analyze the relationship between EMG electrode placement and articulatory feature predictability, providing knowledge-driven insights for optimizing EMG electrode configurations. The source code and decoded speech samples are publicly available.
Deep Speech Synthesis from MRI-Based Articulatory Representations
Jul 05, 2023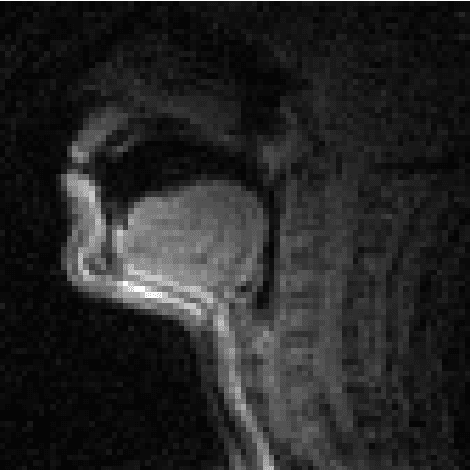
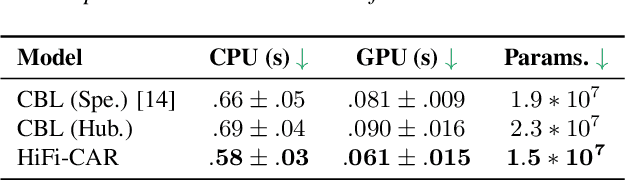
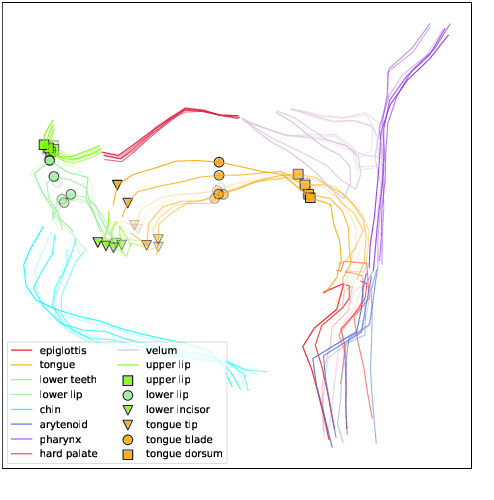
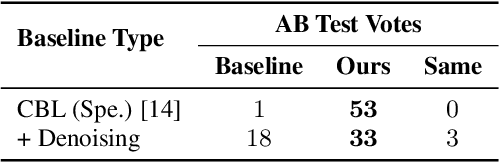
In this paper, we study articulatory synthesis, a speech synthesis method using human vocal tract information that offers a way to develop efficient, generalizable and interpretable synthesizers. While recent advances have enabled intelligible articulatory synthesis using electromagnetic articulography (EMA), these methods lack critical articulatory information like excitation and nasality, limiting generalization capabilities. To bridge this gap, we propose an alternative MRI-based feature set that covers a much more extensive articulatory space than EMA. We also introduce normalization and denoising procedures to enhance the generalizability of deep learning methods trained on MRI data. Moreover, we propose an MRI-to-speech model that improves both computational efficiency and speech fidelity. Finally, through a series of ablations, we show that the proposed MRI representation is more comprehensive than EMA and identify the most suitable MRI feature subset for articulatory synthesis.
Speaker-Independent Acoustic-to-Articulatory Speech Inversion
Feb 14, 2023



To build speech processing methods that can handle speech as naturally as humans, researchers have explored multiple ways of building an invertible mapping from speech to an interpretable space. The articulatory space is a promising inversion target, since this space captures the mechanics of speech production. To this end, we build an acoustic-to-articulatory inversion (AAI) model that leverages autoregression, adversarial training, and self supervision to generalize to unseen speakers. Our approach obtains 0.784 correlation on an electromagnetic articulography (EMA) dataset, improving the state-of-the-art by 12.5%. Additionally, we show the interpretability of these representations through directly comparing the behavior of estimated representations with speech production behavior. Finally, we propose a resynthesis-based AAI evaluation metric that does not rely on articulatory labels, demonstrating its efficacy with an 18-speaker dataset.
Articulatory Representation Learning Via Joint Factor Analysis and Neural Matrix Factorization
Oct 29, 2022Articulatory representation learning is the fundamental research in modeling neural speech production system. Our previous work has established a deep paradigm to decompose the articulatory kinematics data into gestures, which explicitly model the phonological and linguistic structure encoded with human speech production mechanism, and corresponding gestural scores. We continue with this line of work by raising two concerns: (1) The articulators are entangled together in the original algorithm such that some of the articulators do not leverage effective moving patterns, which limits the interpretability of both gestures and gestural scores; (2) The EMA data is sparsely sampled from articulators, which limits the intelligibility of learned representations. In this work, we propose a novel articulatory representation decomposition algorithm that takes the advantage of guided factor analysis to derive the articulatory-specific factors and factor scores. A neural convolutive matrix factorization algorithm is then employed on the factor scores to derive the new gestures and gestural scores. We experiment with the rtMRI corpus that captures the fine-grained vocal tract contours. Both subjective and objective evaluation results suggest that the newly proposed system delivers the articulatory representations that are intelligible, generalizable, efficient and interpretable.
Deep Speech Synthesis from Articulatory Representations
Sep 13, 2022

In the articulatory synthesis task, speech is synthesized from input features containing information about the physical behavior of the human vocal tract. This task provides a promising direction for speech synthesis research, as the articulatory space is compact, smooth, and interpretable. Current works have highlighted the potential for deep learning models to perform articulatory synthesis. However, it remains unclear whether these models can achieve the efficiency and fidelity of the human speech production system. To help bridge this gap, we propose a time-domain articulatory synthesis methodology and demonstrate its efficacy with both electromagnetic articulography (EMA) and synthetic articulatory feature inputs. Our model is computationally efficient and achieves a transcription word error rate (WER) of 18.5% for the EMA-to-speech task, yielding an improvement of 11.6% compared to prior work. Through interpolation experiments, we also highlight the generalizability and interpretability of our approach.
Deep Neural Convolutive Matrix Factorization for Articulatory Representation Decomposition
Apr 08, 2022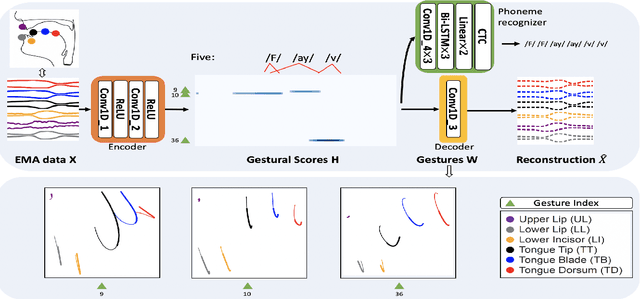
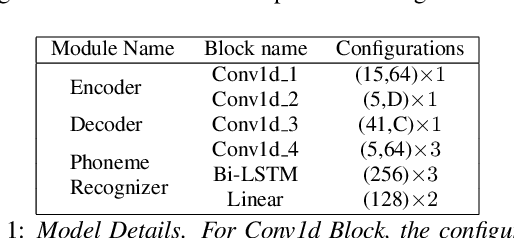
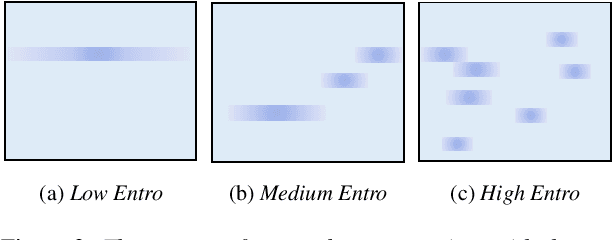
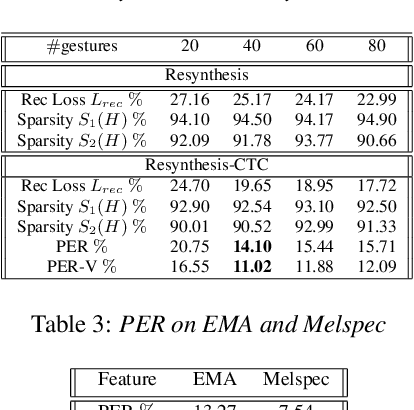
Most of the research on data-driven speech representation learning has focused on raw audios in an end-to-end manner, paying little attention to their internal phonological or gestural structure. This work, investigating the speech representations derived from articulatory kinematics signals, uses a neural implementation of convolutive sparse matrix factorization to decompose the articulatory data into interpretable gestures and gestural scores. By applying sparse constraints, the gestural scores leverage the discrete combinatorial properties of phonological gestures. Phoneme recognition experiments were additionally performed to show that gestural scores indeed code phonological information successfully. The proposed work thus makes a bridge between articulatory phonology and deep neural networks to leverage informative, intelligible, interpretable,and efficient speech representations.
A multispeaker dataset of raw and reconstructed speech production real-time MRI video and 3D volumetric images
Feb 16, 2021
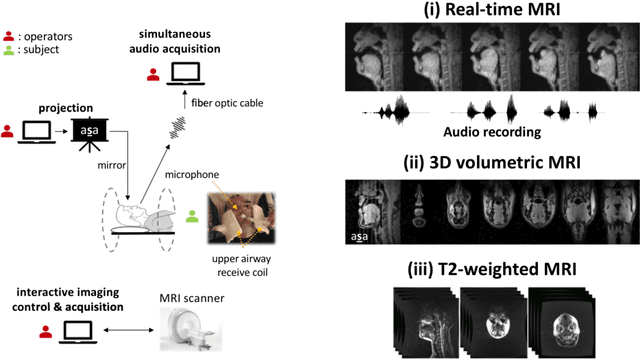
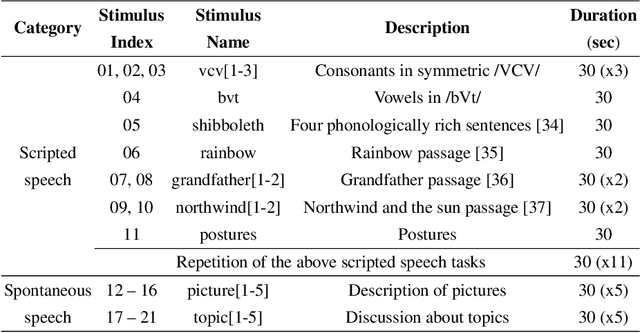
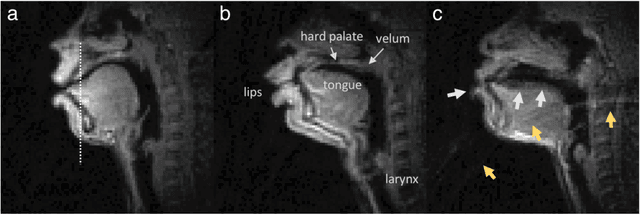
Real-time magnetic resonance imaging (RT-MRI) of human speech production is enabling significant advances in speech science, linguistics, bio-inspired speech technology development, and clinical applications. Easy access to RT-MRI is however limited, and comprehensive datasets with broad access are needed to catalyze research across numerous domains. The imaging of the rapidly moving articulators and dynamic airway shaping during speech demands high spatio-temporal resolution and robust reconstruction methods. Further, while reconstructed images have been published, to-date there is no open dataset providing raw multi-coil RT-MRI data from an optimized speech production experimental setup. Such datasets could enable new and improved methods for dynamic image reconstruction, artifact correction, feature extraction, and direct extraction of linguistically-relevant biomarkers. The present dataset offers a unique corpus of 2D sagittal-view RT-MRI videos along with synchronized audio for 75 subjects performing linguistically motivated speech tasks, alongside the corresponding first-ever public domain raw RT-MRI data. The dataset also includes 3D volumetric vocal tract MRI during sustained speech sounds and high-resolution static anatomical T2-weighted upper airway MRI for each subject.