 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSSDM 2.0: Time-Accurate Speech Rich Transcription with Non-Fluencies
Nov 29, 2024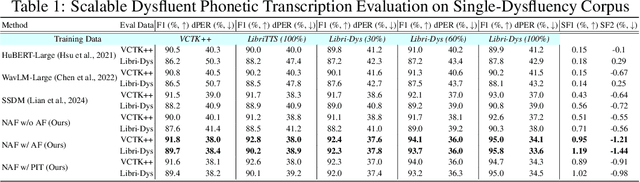
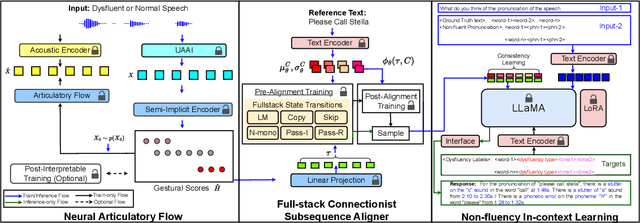

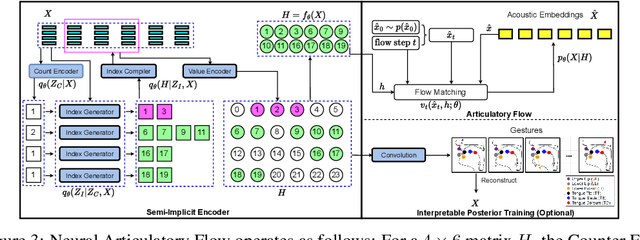
Speech is a hierarchical collection of text, prosody, emotions, dysfluencies, etc. Automatic transcription of speech that goes beyond text (words) is an underexplored problem. We focus on transcribing speech along with non-fluencies (dysfluencies). The current state-of-the-art pipeline SSDM suffers from complex architecture design, training complexity, and significant shortcomings in the local sequence aligner, and it does not explore in-context learning capacity. In this work, we propose SSDM 2.0, which tackles those shortcomings via four main contributions: (1) We propose a novel \textit{neural articulatory flow} to derive highly scalable speech representations. (2) We developed a \textit{full-stack connectionist subsequence aligner} that captures all types of dysfluencies. (3) We introduced a mispronunciation prompt pipeline and consistency learning module into LLM to leverage dysfluency \textit{in-context pronunciation learning} abilities. (4) We curated Libri-Dys and open-sourced the current largest-scale co-dysfluency corpus, \textit{Libri-Co-Dys}, for future research endeavors. In clinical experiments on pathological speech transcription, we tested SSDM 2.0 using nfvPPA corpus primarily characterized by \textit{articulatory dysfluencies}. Overall, SSDM 2.0 outperforms SSDM and all other dysfluency transcription models by a large margin. See our project demo page at \url{https://berkeley-speech-group.github.io/SSDM2.0/}.
YOLO-Stutter: End-to-end Region-Wise Speech Dysfluency Detection
Sep 09, 2024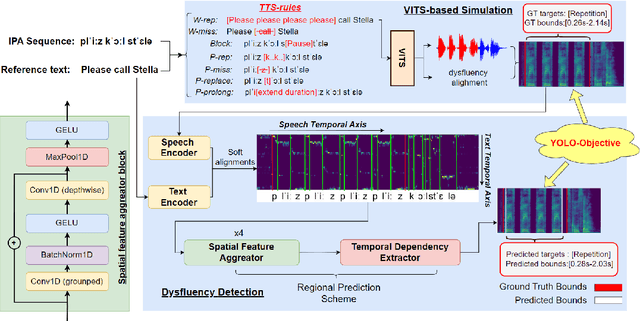
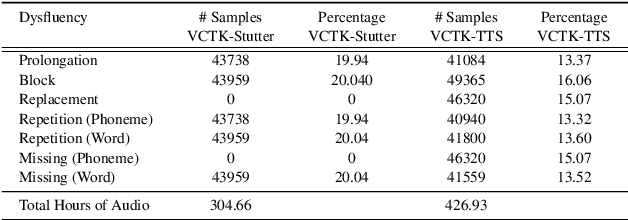
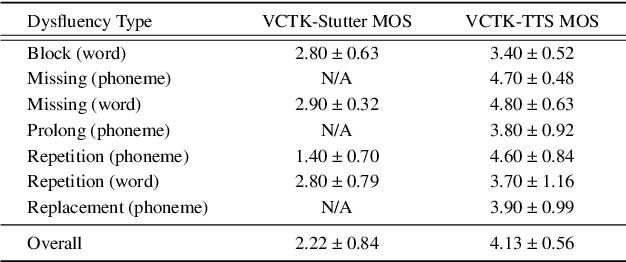

Dysfluent speech detection is the bottleneck for disordered speech analysis and spoken language learning. Current state-of-the-art models are governed by rule-based systems which lack efficiency and robustness, and are sensitive to template design. In this paper, we propose YOLO-Stutter: a first end-to-end method that detects dysfluencies in a time-accurate manner. YOLO-Stutter takes imperfect speech-text alignment as input, followed by a spatial feature aggregator, and a temporal dependency extractor to perform region-wise boundary and class predictions. We also introduce two dysfluency corpus, VCTK-Stutter and VCTK-TTS, that simulate natural spoken dysfluencies including repetition, block, missing, replacement, and prolongation. Our end-to-end method achieves state-of-the-art performance with a minimum number of trainable parameters for on both simulated data and real aphasia speech. Code and datasets are open-sourced at https://github.com/rorizzz/YOLO-Stutter
Fast, High-Quality and Parameter-Efficient Articulatory Synthesis using Differentiable DSP
Sep 04, 2024



Articulatory trajectories like electromagnetic articulography (EMA) provide a low-dimensional representation of the vocal tract filter and have been used as natural, grounded features for speech synthesis. Differentiable digital signal processing (DDSP) is a parameter-efficient framework for audio synthesis. Therefore, integrating low-dimensional EMA features with DDSP can significantly enhance the computational efficiency of speech synthesis. In this paper, we propose a fast, high-quality, and parameter-efficient DDSP articulatory vocoder that can synthesize speech from EMA, F0, and loudness. We incorporate several techniques to solve the harmonics / noise imbalance problem, and add a multi-resolution adversarial loss for better synthesis quality. Our model achieves a transcription word error rate (WER) of 6.67% and a mean opinion score (MOS) of 3.74, with an improvement of 1.63% and 0.16 compared to the state-of-the-art (SOTA) baseline. Our DDSP vocoder is 4.9x faster than the baseline on CPU during inference, and can generate speech of comparable quality with only 0.4M parameters, in contrast to the 9M parameters required by the SOTA.
Towards EMG-to-Speech with a Necklace Form Factor
Jul 31, 2024



Electrodes for decoding speech from electromyography (EMG) are typically placed on the face, requiring adhesives that are inconvenient and skin-irritating if used regularly. We explore a different device form factor, where dry electrodes are placed around the neck instead. 11-word, multi-speaker voiced EMG classifiers trained on data recorded with this device achieve 92.7% accuracy. Ablation studies reveal the importance of having more than two electrodes on the neck, and phonological analyses reveal similar classification confusions between neck-only and neck-and-face form factors. Finally, speech-EMG correlation experiments demonstrate a linear relationship between many EMG spectrogram frequency bins and self-supervised speech representation dimensions.
Speech After Gender: A Trans-Feminine Perspective on Next Steps for Speech Science and Technology
Jul 09, 2024



As experts in voice modification, trans-feminine gender-affirming voice teachers have unique perspectives on voice that confound current understandings of speaker identity. To demonstrate this, we present the Versatile Voice Dataset (VVD), a collection of three speakers modifying their voices along gendered axes. The VVD illustrates that current approaches in speaker modeling, based on categorical notions of gender and a static understanding of vocal texture, fail to account for the flexibility of the vocal tract. Utilizing publicly-available speaker embeddings, we demonstrate that gender classification systems are highly sensitive to voice modification, and speaker verification systems fail to identify voices as coming from the same speaker as voice modification becomes more drastic. As one path towards moving beyond categorical and static notions of speaker identity, we propose modeling individual qualities of vocal texture such as pitch, resonance, and weight.
Unconstrained Dysfluency Modeling for Dysfluent Speech Transcription and Detection
Dec 20, 2023Dysfluent speech modeling requires time-accurate and silence-aware transcription at both the word-level and phonetic-level. However, current research in dysfluency modeling primarily focuses on either transcription or detection, and the performance of each aspect remains limited. In this work, we present an unconstrained dysfluency modeling (UDM) approach that addresses both transcription and detection in an automatic and hierarchical manner. UDM eliminates the need for extensive manual annotation by providing a comprehensive solution. Furthermore, we introduce a simulated dysfluent dataset called VCTK++ to enhance the capabilities of UDM in phonetic transcription. Our experimental results demonstrate the effectiveness and robustness of our proposed methods in both transcription and detection tasks.
PerMod: Perceptually Grounded Voice Modification with Latent Diffusion Models
Dec 13, 2023


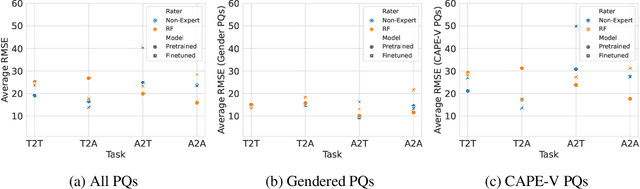
Perceptual modification of voice is an elusive goal. While non-experts can modify an image or sentence perceptually with available tools, it is not clear how to similarly modify speech along perceptual axes. Voice conversion does make it possible to convert one voice to another, but these modifications are handled by black box models, and the specifics of what perceptual qualities to modify and how to modify them are unclear. Towards allowing greater perceptual control over voice, we introduce PerMod, a conditional latent diffusion model that takes in an input voice and a perceptual qualities vector, and produces a voice with the matching perceptual qualities. Unlike prior work, PerMod generates a new voice corresponding to specific perceptual modifications. Evaluating perceptual quality vectors with RMSE from both human and predicted labels, we demonstrate that PerMod produces voices with the desired perceptual qualities for typical voices, but performs poorly on atypical voices.
UTTS: Unsupervised TTS with Conditional Disentangled Sequential Variational Auto-encoder
Jun 07, 2022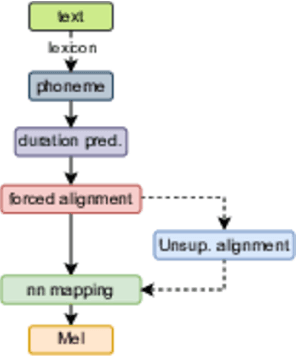

In this paper, we propose a novel unsupervised text-to-speech (UTTS) framework which does not require text-audio pairs for the TTS acoustic modeling (AM). UTTS is a multi-speaker speech synthesizer developed from the perspective of disentangled speech representation learning. The framework offers a flexible choice of a speaker's duration model, timbre feature (identity) and content for TTS inference. We leverage recent advancements in self-supervised speech representation learning as well as speech synthesis front-end techniques for the system development. Specifically, we utilize a lexicon to map input text to the phoneme sequence, which is expanded to the frame-level forced alignment (FA) with a speaker-dependent duration model. Then, we develop an alignment mapping module that converts the FA to the unsupervised alignment (UA). Finally, a Conditional Disentangled Sequential Variational Auto-encoder (C-DSVAE), serving as the self-supervised TTS AM, takes the predicted UA and a target speaker embedding to generate the mel spectrogram, which is ultimately converted to waveform with a neural vocoder. We show how our method enables speech synthesis without using a paired TTS corpus. Experiments demonstrate that UTTS can synthesize speech of high naturalness and intelligibility measured by human and objective evaluations.
Towards Improved Zero-shot Voice Conversion with Conditional DSVAE
May 11, 2022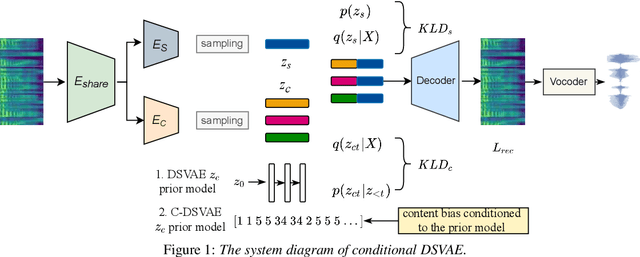

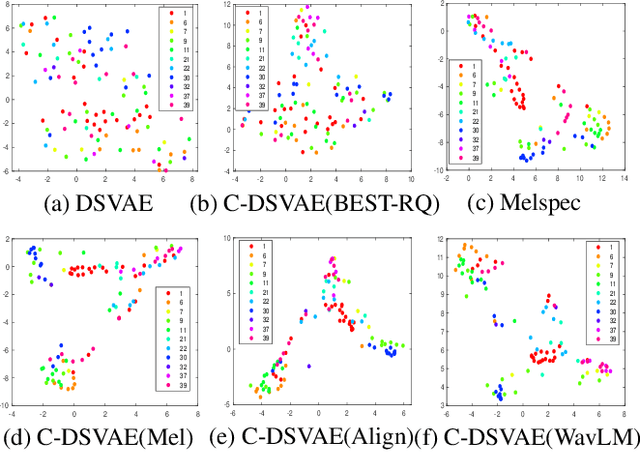
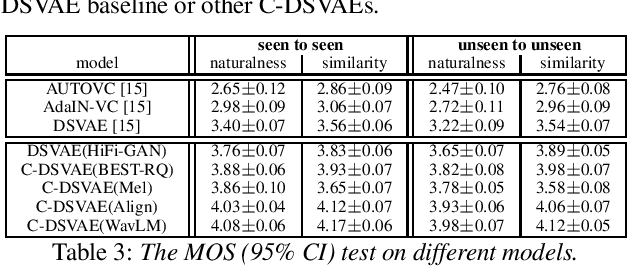
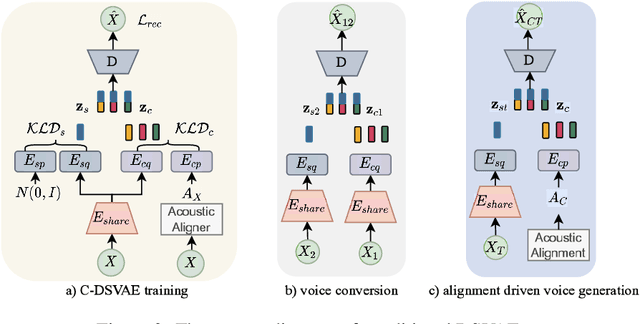
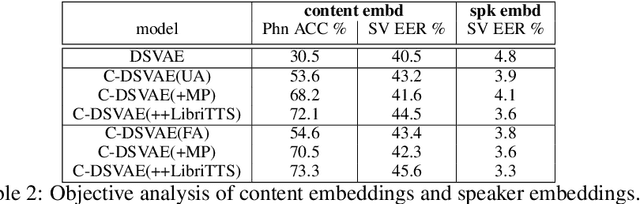
Disentangling content and speaking style information is essential for zero-shot non-parallel voice conversion (VC). Our previous study investigated a novel framework with disentangled sequential variational autoencoder (DSVAE) as the backbone for information decomposition. We have demonstrated that simultaneous disentangling content embedding and speaker embedding from one utterance is feasible for zero-shot VC. In this study, we continue the direction by raising one concern about the prior distribution of content branch in the DSVAE baseline. We find the random initialized prior distribution will force the content embedding to reduce the phonetic-structure information during the learning process, which is not a desired property. Here, we seek to achieve a better content embedding with more phonetic information preserved. We propose conditional DSVAE, a new model that enables content bias as a condition to the prior modeling and reshapes the content embedding sampled from the posterior distribution. In our experiment on the VCTK dataset, we demonstrate that content embeddings derived from the conditional DSVAE overcome the randomness and achieve a much better phoneme classification accuracy, a stabilized vocalization and a better zero-shot VC performance compared with the competitive DSVAE baseline.
Deep Neural Convolutive Matrix Factorization for Articulatory Representation Decomposition
Apr 08, 2022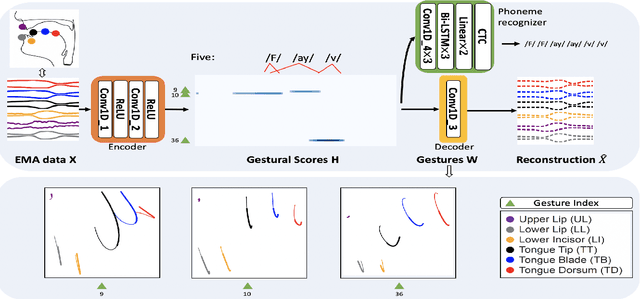
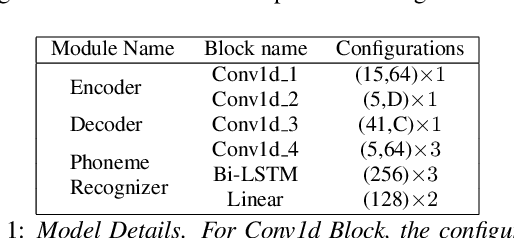
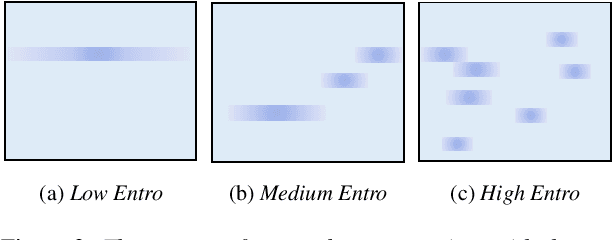
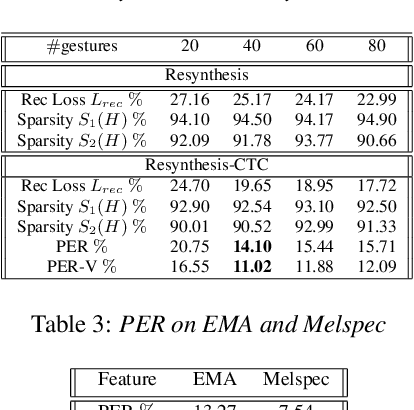
Most of the research on data-driven speech representation learning has focused on raw audios in an end-to-end manner, paying little attention to their internal phonological or gestural structure. This work, investigating the speech representations derived from articulatory kinematics signals, uses a neural implementation of convolutive sparse matrix factorization to decompose the articulatory data into interpretable gestures and gestural scores. By applying sparse constraints, the gestural scores leverage the discrete combinatorial properties of phonological gestures. Phoneme recognition experiments were additionally performed to show that gestural scores indeed code phonological information successfully. The proposed work thus makes a bridge between articulatory phonology and deep neural networks to leverage informative, intelligible, interpretable,and efficient speech representations.