 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStutter-Solver: End-to-end Multi-lingual Dysfluency Detection
Sep 15, 2024Current de-facto dysfluency modeling methods utilize template matching algorithms which are not generalizable to out-of-domain real-world dysfluencies across languages, and are not scalable with increasing amounts of training data. To handle these problems, we propose Stutter-Solver: an end-to-end framework that detects dysfluency with accurate type and time transcription, inspired by the YOLO object detection algorithm. Stutter-Solver can handle co-dysfluencies and is a natural multi-lingual dysfluency detector. To leverage scalability and boost performance, we also introduce three novel dysfluency corpora: VCTK-Pro, VCTK-Art, and AISHELL3-Pro, simulating natural spoken dysfluencies including repetition, block, missing, replacement, and prolongation through articulatory-encodec and TTS-based methods. Our approach achieves state-of-the-art performance on all available dysfluency corpora. Code and datasets are open-sourced at https://github.com/eureka235/Stutter-Solver
YOLO-Stutter: End-to-end Region-Wise Speech Dysfluency Detection
Sep 09, 2024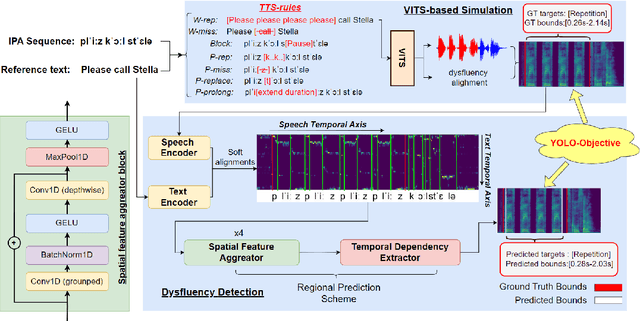
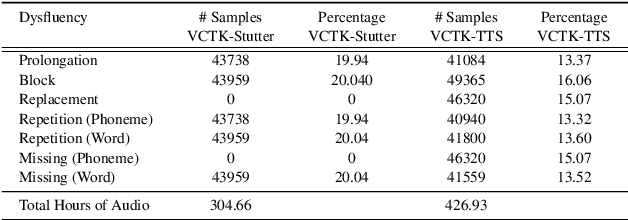
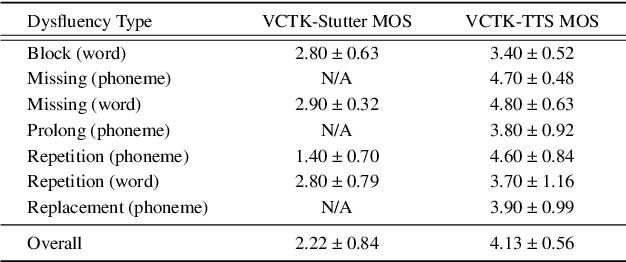

Dysfluent speech detection is the bottleneck for disordered speech analysis and spoken language learning. Current state-of-the-art models are governed by rule-based systems which lack efficiency and robustness, and are sensitive to template design. In this paper, we propose YOLO-Stutter: a first end-to-end method that detects dysfluencies in a time-accurate manner. YOLO-Stutter takes imperfect speech-text alignment as input, followed by a spatial feature aggregator, and a temporal dependency extractor to perform region-wise boundary and class predictions. We also introduce two dysfluency corpus, VCTK-Stutter and VCTK-TTS, that simulate natural spoken dysfluencies including repetition, block, missing, replacement, and prolongation. Our end-to-end method achieves state-of-the-art performance with a minimum number of trainable parameters for on both simulated data and real aphasia speech. Code and datasets are open-sourced at https://github.com/rorizzz/YOLO-Stutter