 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLCS-CTC: Leveraging Soft Alignments to Enhance Phonetic Transcription Robustness
Aug 05, 2025Phonetic speech transcription is crucial for fine-grained linguistic analysis and downstream speech applications. While Connectionist Temporal Classification (CTC) is a widely used approach for such tasks due to its efficiency, it often falls short in recognition performance, especially under unclear and nonfluent speech. In this work, we propose LCS-CTC, a two-stage framework for phoneme-level speech recognition that combines a similarity-aware local alignment algorithm with a constrained CTC training objective. By predicting fine-grained frame-phoneme cost matrices and applying a modified Longest Common Subsequence (LCS) algorithm, our method identifies high-confidence alignment zones which are used to constrain the CTC decoding path space, thereby reducing overfitting and improving generalization ability, which enables both robust recognition and text-free forced alignment. Experiments on both LibriSpeech and PPA demonstrate that LCS-CTC consistently outperforms vanilla CTC baselines, suggesting its potential to unify phoneme modeling across fluent and non-fluent speech.
Analysis and Evaluation of Synthetic Data Generation in Speech Dysfluency Detection
May 28, 2025Speech dysfluency detection is crucial for clinical diagnosis and language assessment, but existing methods are limited by the scarcity of high-quality annotated data. Although recent advances in TTS model have enabled synthetic dysfluency generation, existing synthetic datasets suffer from unnatural prosody and limited contextual diversity. To address these limitations, we propose LLM-Dys -- the most comprehensive dysfluent speech corpus with LLM-enhanced dysfluency simulation. This dataset captures 11 dysfluency categories spanning both word and phoneme levels. Building upon this resource, we improve an end-to-end dysfluency detection framework. Experimental validation demonstrates state-of-the-art performance. All data, models, and code are open-sourced at https://github.com/Berkeley-Speech-Group/LLM-Dys.
Dysfluent WFST: A Framework for Zero-Shot Speech Dysfluency Transcription and Detection
May 22, 2025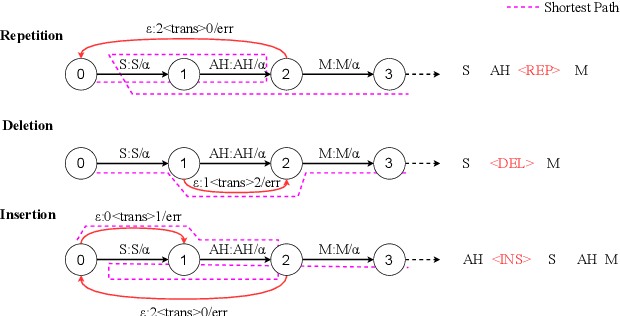

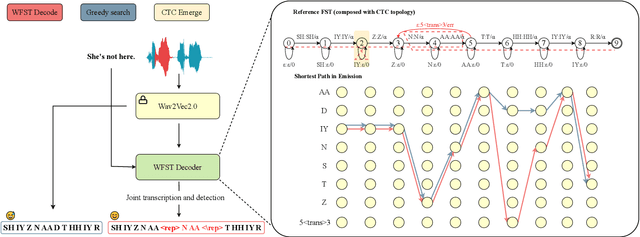
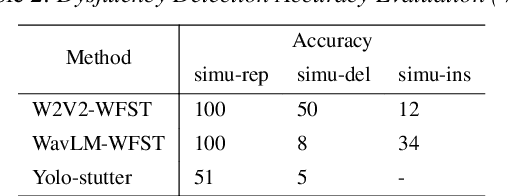
Automatic detection of speech dysfluency aids speech-language pathologists in efficient transcription of disordered speech, enhancing diagnostics and treatment planning. Traditional methods, often limited to classification, provide insufficient clinical insight, and text-independent models misclassify dysfluency, especially in context-dependent cases. This work introduces Dysfluent-WFST, a zero-shot decoder that simultaneously transcribes phonemes and detects dysfluency. Unlike previous models, Dysfluent-WFST operates with upstream encoders like WavLM and requires no additional training. It achieves state-of-the-art performance in both phonetic error rate and dysfluency detection on simulated and real speech data. Our approach is lightweight, interpretable, and effective, demonstrating that explicit modeling of pronunciation behavior in decoding, rather than complex architectures, is key to improving dysfluency processing systems.
SSDM 2.0: Time-Accurate Speech Rich Transcription with Non-Fluencies
Nov 29, 2024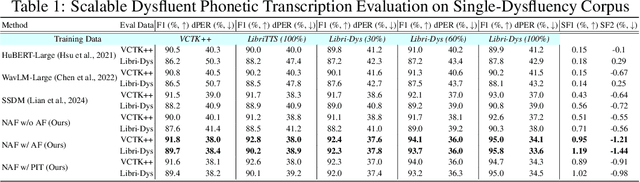
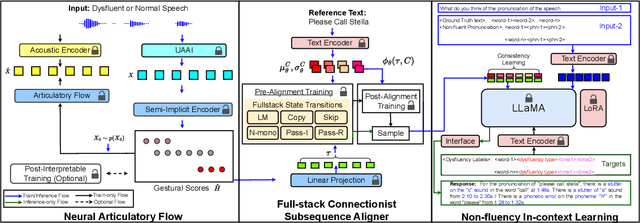

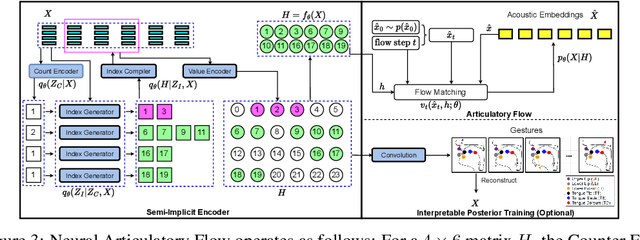
Speech is a hierarchical collection of text, prosody, emotions, dysfluencies, etc. Automatic transcription of speech that goes beyond text (words) is an underexplored problem. We focus on transcribing speech along with non-fluencies (dysfluencies). The current state-of-the-art pipeline SSDM suffers from complex architecture design, training complexity, and significant shortcomings in the local sequence aligner, and it does not explore in-context learning capacity. In this work, we propose SSDM 2.0, which tackles those shortcomings via four main contributions: (1) We propose a novel \textit{neural articulatory flow} to derive highly scalable speech representations. (2) We developed a \textit{full-stack connectionist subsequence aligner} that captures all types of dysfluencies. (3) We introduced a mispronunciation prompt pipeline and consistency learning module into LLM to leverage dysfluency \textit{in-context pronunciation learning} abilities. (4) We curated Libri-Dys and open-sourced the current largest-scale co-dysfluency corpus, \textit{Libri-Co-Dys}, for future research endeavors. In clinical experiments on pathological speech transcription, we tested SSDM 2.0 using nfvPPA corpus primarily characterized by \textit{articulatory dysfluencies}. Overall, SSDM 2.0 outperforms SSDM and all other dysfluency transcription models by a large margin. See our project demo page at \url{https://berkeley-speech-group.github.io/SSDM2.0/}.
Stutter-Solver: End-to-end Multi-lingual Dysfluency Detection
Sep 15, 2024Current de-facto dysfluency modeling methods utilize template matching algorithms which are not generalizable to out-of-domain real-world dysfluencies across languages, and are not scalable with increasing amounts of training data. To handle these problems, we propose Stutter-Solver: an end-to-end framework that detects dysfluency with accurate type and time transcription, inspired by the YOLO object detection algorithm. Stutter-Solver can handle co-dysfluencies and is a natural multi-lingual dysfluency detector. To leverage scalability and boost performance, we also introduce three novel dysfluency corpora: VCTK-Pro, VCTK-Art, and AISHELL3-Pro, simulating natural spoken dysfluencies including repetition, block, missing, replacement, and prolongation through articulatory-encodec and TTS-based methods. Our approach achieves state-of-the-art performance on all available dysfluency corpora. Code and datasets are open-sourced at https://github.com/eureka235/Stutter-Solver
YOLO-Stutter: End-to-end Region-Wise Speech Dysfluency Detection
Sep 09, 2024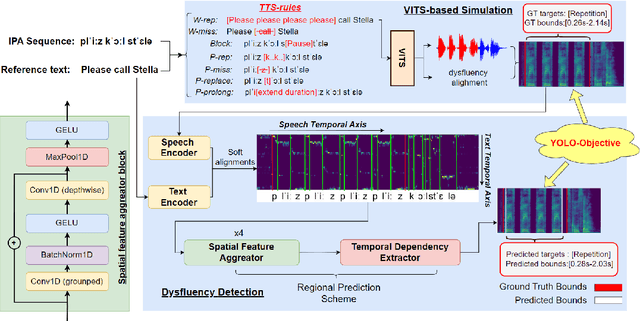
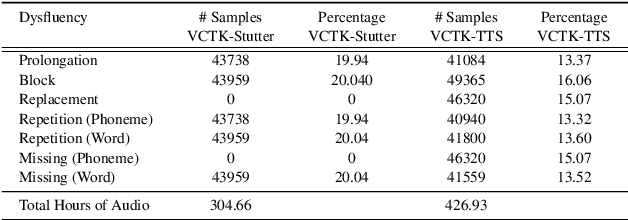
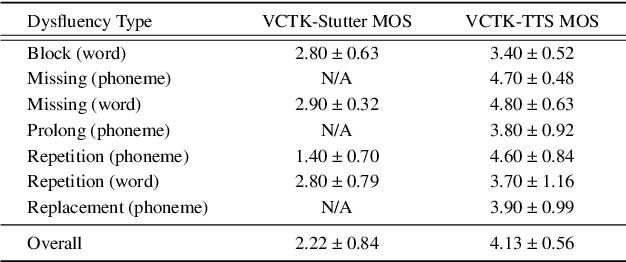

Dysfluent speech detection is the bottleneck for disordered speech analysis and spoken language learning. Current state-of-the-art models are governed by rule-based systems which lack efficiency and robustness, and are sensitive to template design. In this paper, we propose YOLO-Stutter: a first end-to-end method that detects dysfluencies in a time-accurate manner. YOLO-Stutter takes imperfect speech-text alignment as input, followed by a spatial feature aggregator, and a temporal dependency extractor to perform region-wise boundary and class predictions. We also introduce two dysfluency corpus, VCTK-Stutter and VCTK-TTS, that simulate natural spoken dysfluencies including repetition, block, missing, replacement, and prolongation. Our end-to-end method achieves state-of-the-art performance with a minimum number of trainable parameters for on both simulated data and real aphasia speech. Code and datasets are open-sourced at https://github.com/rorizzz/YOLO-Stutter
SSDM: Scalable Speech Dysfluency Modeling
Aug 29, 2024



Speech dysfluency modeling is the core module for spoken language learning, and speech therapy. However, there are three challenges. First, current state-of-the-art solutions suffer from poor scalability. Second, there is a lack of a large-scale dysfluency corpus. Third, there is not an effective learning framework. In this paper, we propose \textit{SSDM: Scalable Speech Dysfluency Modeling}, which (1) adopts articulatory gestures as scalable forced alignment; (2) introduces connectionist subsequence aligner (CSA) to achieve dysfluency alignment; (3) introduces a large-scale simulated dysfluency corpus called Libri-Dys; and (4) develops an end-to-end system by leveraging the power of large language models (LLMs). We expect SSDM to serve as a standard in the area of dysfluency modeling. Demo is available at \url{https://eureka235.github.io}.