 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Single-Factor Physical Video-to-Audio Generation
May 28, 2026Generative video-to-audio (V2A) models produce highly plausible soundtracks, but it remains unclear whether they capture the underlying physical processes. Existing evaluations emphasize perceptual realism and overlook physical correctness under controlled interventions. In this paper, we introduce FlatSounds, a benchmark that audits the physical reasoning of V2A models through: 1) controlled counterfactual pairs in which a single physical factor is varied, and 2) single-video pattern tests that probe internal consistency and directional trends. These settings test whether the generated audio correctly reflects specific physical properties and timings. Our evaluation of state-of-the-art models reveals a consistent trade-off: models rely more on text captions than the visual stream to infer physics and semantics. Captions generally improve physical and semantic accuracy, but paradoxically degrade temporal alignment. Our results highlight the need to move beyond audio quality toward learning physical processes directly from pixels. Finally, we find that our physics-based metrics correlate strongly with human preference tests on our own data. Project webpage: https://research.nvidia.com/labs/cosmos-lab/flatsounds/
HASS: Hierarchical Simulation of Logopenic Aphasic Speech for Scalable PPA Detection
Mar 25, 2026Building a diagnosis model for primary progressive aphasia (PPA) has been challenging due to the data scarcity. Collecting clinical data at scale is limited by the high vulnerability of clinical population and the high cost of expert labeling. To circumvent this, previous studies simulate dysfluent speech to generate training data. However, those approaches are not comprehensive enough to simulate PPA as holistic, multi-level phenotypes, instead relying on isolated dysfluencies. To address this, we propose a novel, clinically grounded simulation framework, Hierarchical Aphasic Speech Simulation (HASS). HASS aims to simulate behaviors of logopenic variant of PPA (lvPPA) with varying degrees of severity. To this end, semantic, phonological, and temporal deficits of lvPPA are systematically identified by clinical experts, and simulated. We demonstrate that our framework enables more accurate and generalizable detection models.
StyleStream: Real-Time Zero-Shot Voice Style Conversion
Feb 23, 2026Voice style conversion aims to transform an input utterance to match a target speaker's timbre, accent, and emotion, with a central challenge being the disentanglement of linguistic content from style. While prior work has explored this problem, conversion quality remains limited, and real-time voice style conversion has not been addressed. We propose StyleStream, the first streamable zero-shot voice style conversion system that achieves state-of-the-art performance. StyleStream consists of two components: a Destylizer, which removes style attributes while preserving linguistic content, and a Stylizer, a diffusion transformer (DiT) that reintroduces target style conditioned on reference speech. Robust content-style disentanglement is enforced through text supervision and a highly constrained information bottleneck. This design enables a fully non-autoregressive architecture, achieving real-time voice style conversion with an end-to-end latency of 1 second. Samples and real-time demo: https://berkeley-speech-group.github.io/StyleStream/.
Conversational Behavior Modeling Foundation Model With Multi-Level Perception
Feb 11, 2026Human conversation is organized by an implicit chain of thoughts that manifests as timed speech acts. Capturing this perceptual pathway is key to building natural full-duplex interactive systems. We introduce a framework that models this process as multi-level perception, and then reasons over conversational behaviors via a Graph-of-Thoughts (GoT). Our approach formalizes the intent-to-action pathway with a hierarchical labeling scheme, predicting high-level communicative intents and low-level speech acts to learn their causal and temporal dependencies. To train this system, we develop a high quality corpus that pairs controllable, event-rich dialogue data with human-annotated labels. The GoT framework structures streaming predictions as an evolving graph, enabling a transformer to forecast the next speech act, generate concise justifications for its decisions, and dynamically refine its reasoning. Experiments on both synthetic and real duplex dialogues show that the framework delivers robust behavior detection, produces interpretable reasoning chains, and establishes a foundation for benchmarking conversational reasoning in full duplex spoken dialogue systems.
Asymmetric Hierarchical Anchoring for Audio-Visual Joint Representation: Resolving Information Allocation Ambiguity for Robust Cross-Modal Generalization
Feb 03, 2026Audio-visual joint representation learning under Cross-Modal Generalization (CMG) aims to transfer knowledge from a labeled source modality to an unlabeled target modality through a unified discrete representation space. Existing symmetric frameworks often suffer from information allocation ambiguity, where the absence of structural inductive bias leads to semantic-specific leakage across modalities. We propose Asymmetric Hierarchical Anchoring (AHA), which enforces directional information allocation by designating a structured semantic anchor within a shared hierarchy. In our instantiation, we exploit the hierarchical discrete representations induced by audio Residual Vector Quantization (RVQ) to guide video feature distillation into a shared semantic space. To ensure representational purity, we replace fragile mutual information estimators with a GRL-based adversarial decoupler that explicitly suppresses semantic leakage in modality-specific branches, and introduce Local Sliding Alignment (LSA) to encourage fine-grained temporal alignment across modalities. Extensive experiments on AVE and AVVP benchmarks demonstrate that AHA consistently outperforms symmetric baselines in cross-modal transfer. Additional analyses on talking-face disentanglement experiment further validate that the learned representations exhibit improved semantic consistency and disentanglement, indicating the broader applicability of the proposed framework.
HuPER: A Human-Inspired Framework for Phonetic Perception
Feb 02, 2026We propose HuPER, a human-inspired framework that models phonetic perception as adaptive inference over acoustic-phonetics evidence and linguistic knowledge. With only 100 hours of training data, HuPER achieves state-of-the-art phonetic error rates on five English benchmarks and strong zero-shot transfer to 95 unseen languages. HuPER is also the first framework to enable adaptive, multi-path phonetic perception under diverse acoustic conditions. All training data, models, and code are open-sourced. Code and demo avaliable at https://github.com/HuPER29/HuPER.
Evolutionary Strategies lead to Catastrophic Forgetting in LLMs
Jan 28, 2026One of the biggest missing capabilities in current AI systems is the ability to learn continuously after deployment. Implementing such continually learning systems have several challenges, one of which is the large memory requirement of gradient-based algorithms that are used to train state-of-the-art LLMs. Evolutionary Strategies (ES) have recently re-emerged as a gradient-free alternative to traditional learning algorithms and have shown encouraging performance on specific tasks in LLMs. In this paper, we perform a comprehensive analysis of ES and specifically evaluate its forgetting curves when training for an increasing number of update steps. We first find that ES is able to reach performance numbers close to GRPO for math and reasoning tasks with a comparable compute budget. However, and most importantly for continual learning, the performance gains in ES is accompanied by significant forgetting of prior abilities, limiting its applicability for training models online. We also explore the reason behind this behavior and show that the updates made using ES are much less sparse and have orders of magnitude larger $\ell_2$ norm compared to corresponding GRPO updates, explaining the contrasting forgetting curves between the two algorithms. With this study, we aim to highlight the issue of forgetting in gradient-free algorithms like ES and hope to inspire future work to mitigate these issues.
Enabling Conversational Behavior Reasoning Capabilities in Full-Duplex Speech
Dec 25, 2025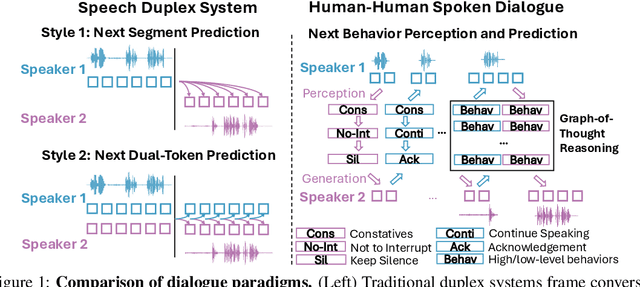

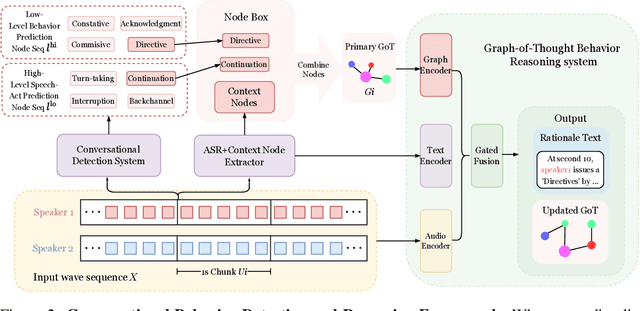

Human conversation is organized by an implicit chain of thoughts that manifests as timed speech acts. Capturing this causal pathway is key to building natural full-duplex interactive systems. We introduce a framework that enables reasoning over conversational behaviors by modeling this process as causal inference within a Graph-of-Thoughts (GoT). Our approach formalizes the intent-to-action pathway with a hierarchical labeling scheme, predicting high-level communicative intents and low-level speech acts to learn their causal and temporal dependencies. To train this system, we develop a hybrid corpus that pairs controllable, event-rich simulations with human-annotated rationales and real conversational speech. The GoT framework structures streaming predictions as an evolving graph, enabling a multimodal transformer to forecast the next speech act, generate concise justifications for its decisions, and dynamically refine its reasoning. Experiments on both synthetic and real duplex dialogues show that the framework delivers robust behavior detection, produces interpretable reasoning chains, and establishes a foundation for benchmarking conversational reasoning in full duplex spoken dialogue systems.
Schrodinger Audio-Visual Editor: Object-Level Audiovisual Removal
Dec 14, 2025Joint editing of audio and visual content is crucial for precise and controllable content creation. This new task poses challenges due to the limitations of paired audio-visual data before and after targeted edits, and the heterogeneity across modalities. To address the data and modeling challenges in joint audio-visual editing, we introduce SAVEBench, a paired audiovisual dataset with text and mask conditions to enable object-grounded source-to-target learning. With SAVEBench, we train the Schrodinger Audio-Visual Editor (SAVE), an end-to-end flow-matching model that edits audio and video in parallel while keeping them aligned throughout processing. SAVE incorporates a Schrodinger Bridge that learns a direct transport from source to target audiovisual mixtures. Our evaluation demonstrates that the proposed SAVE model is able to remove the target objects in audio and visual content while preserving the remaining content, with stronger temporal synchronization and audiovisual semantic correspondence compared with pairwise combinations of an audio editor and a video editor.
How Do LLMs Use Their Depth?
Oct 21, 2025



Growing evidence suggests that large language models do not use their depth uniformly, yet we still lack a fine-grained understanding of their layer-wise prediction dynamics. In this paper, we trace the intermediate representations of several open-weight models during inference and reveal a structured and nuanced use of depth. Specifically, we propose a "Guess-then-Refine" framework that explains how LLMs internally structure their computations to make predictions. We first show that the top-ranked predictions in early LLM layers are composed primarily of high-frequency tokens, which act as statistical guesses proposed by the model early on due to the lack of appropriate contextual information. As contextual information develops deeper into the model, these initial guesses get refined into contextually appropriate tokens. Even high-frequency token predictions from early layers get refined >70% of the time, indicating that correct token prediction is not "one-and-done". We then go beyond frequency-based prediction to examine the dynamic usage of layer depth across three case studies. (i) Part-of-speech analysis shows that function words are, on average, the earliest to be predicted correctly. (ii) Fact recall task analysis shows that, in a multi-token answer, the first token requires more computational depth than the rest. (iii) Multiple-choice task analysis shows that the model identifies the format of the response within the first half of the layers, but finalizes its response only toward the end. Together, our results provide a detailed view of depth usage in LLMs, shedding light on the layer-by-layer computations that underlie successful predictions and providing insights for future works to improve computational efficiency in transformer-based models.