 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeechJudge: Towards Human-Level Judgment for Speech Naturalness
Nov 11, 2025

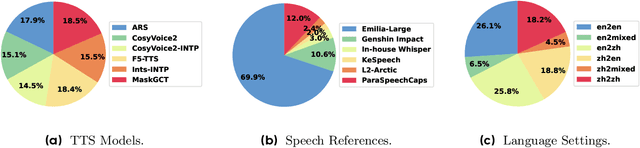
Aligning large generative models with human feedback is a critical challenge. In speech synthesis, this is particularly pronounced due to the lack of a large-scale human preference dataset, which hinders the development of models that truly align with human perception. To address this, we introduce SpeechJudge, a comprehensive suite comprising a dataset, a benchmark, and a reward model centered on naturalness--one of the most fundamental subjective metrics for speech synthesis. First, we present SpeechJudge-Data, a large-scale human feedback corpus of 99K speech pairs. The dataset is constructed using a diverse set of advanced zero-shot text-to-speech (TTS) models across diverse speech styles and multiple languages, with human annotations for both intelligibility and naturalness preference. From this, we establish SpeechJudge-Eval, a challenging benchmark for speech naturalness judgment. Our evaluation reveals that existing metrics and AudioLLMs struggle with this task; the leading model, Gemini-2.5-Flash, achieves less than 70% agreement with human judgment, highlighting a significant gap for improvement. To bridge this gap, we develop SpeechJudge-GRM, a generative reward model (GRM) based on Qwen2.5-Omni-7B. It is trained on SpeechJudge-Data via a two-stage post-training process: Supervised Fine-Tuning (SFT) with Chain-of-Thought rationales followed by Reinforcement Learning (RL) with GRPO on challenging cases. On the SpeechJudge-Eval benchmark, the proposed SpeechJudge-GRM demonstrates superior performance, achieving 77.2% accuracy (and 79.4% after inference-time scaling @10) compared to a classic Bradley-Terry reward model (72.7%). Furthermore, SpeechJudge-GRM can be also employed as a reward function during the post-training of speech generation models to facilitate their alignment with human preferences.
Sounding that Object: Interactive Object-Aware Image to Audio Generation
Jun 04, 2025
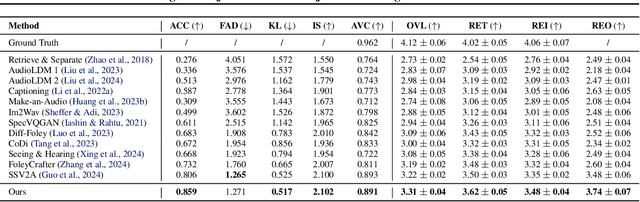


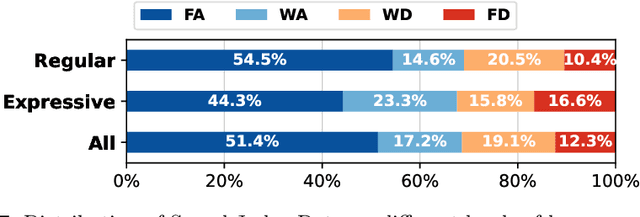
Generating accurate sounds for complex audio-visual scenes is challenging, especially in the presence of multiple objects and sound sources. In this paper, we propose an {\em interactive object-aware audio generation} model that grounds sound generation in user-selected visual objects within images. Our method integrates object-centric learning into a conditional latent diffusion model, which learns to associate image regions with their corresponding sounds through multi-modal attention. At test time, our model employs image segmentation to allow users to interactively generate sounds at the {\em object} level. We theoretically validate that our attention mechanism functionally approximates test-time segmentation masks, ensuring the generated audio aligns with selected objects. Quantitative and qualitative evaluations show that our model outperforms baselines, achieving better alignment between objects and their associated sounds. Project page: https://tinglok.netlify.app/files/avobject/
AudioMorphix: Training-free audio editing with diffusion probabilistic models
May 21, 2025



Editing sound with precision is a crucial yet underexplored challenge in audio content creation. While existing works can manipulate sounds by text instructions or audio exemplar pairs, they often struggled to modify audio content precisely while preserving fidelity to the original recording. In this work, we introduce a novel editing approach that enables localized modifications to specific time-frequency regions while keeping the remaining of the audio intact by operating on spectrograms directly. To achieve this, we propose AudioMorphix, a training-free audio editor that manipulates a target region on the spectrogram by referring to another recording. Inspired by morphing theory, we conceptualize audio mixing as a process where different sounds blend seamlessly through morphing and can be decomposed back into individual components via demorphing. Our AudioMorphix optimizes the noised latent conditioned on raw input and reference audio while rectifying the guided diffusion process through a series of energy functions. Additionally, we enhance self-attention layers with a cache mechanism to preserve detailed characteristics from the original recordings. To advance audio editing research, we devise a new evaluation benchmark, which includes a curated dataset with a variety of editing instructions. Extensive experiments demonstrate that AudioMorphix yields promising performance on various audio editing tasks, including addition, removal, time shifting and stretching, and pitch shifting, achieving high fidelity and precision. Demo and code are available at this url.
DiTAR: Diffusion Transformer Autoregressive Modeling for Speech Generation
Feb 06, 2025



Several recent studies have attempted to autoregressively generate continuous speech representations without discrete speech tokens by combining diffusion and autoregressive models, yet they often face challenges with excessive computational loads or suboptimal outcomes. In this work, we propose Diffusion Transformer Autoregressive Modeling (DiTAR), a patch-based autoregressive framework combining a language model with a diffusion transformer. This approach significantly enhances the efficacy of autoregressive models for continuous tokens and reduces computational demands. DiTAR utilizes a divide-and-conquer strategy for patch generation, where the language model processes aggregated patch embeddings and the diffusion transformer subsequently generates the next patch based on the output of the language model. For inference, we propose defining temperature as the time point of introducing noise during the reverse diffusion ODE to balance diversity and determinism. We also show in the extensive scaling analysis that DiTAR has superb scalability. In zero-shot speech generation, DiTAR achieves state-of-the-art performance in robustness, speaker similarity, and naturalness.
Seed-Music: A Unified Framework for High Quality and Controlled Music Generation
Sep 13, 2024



We introduce Seed-Music, a suite of music generation systems capable of producing high-quality music with fine-grained style control. Our unified framework leverages both auto-regressive language modeling and diffusion approaches to support two key music creation workflows: \textit{controlled music generation} and \textit{post-production editing}. For controlled music generation, our system enables vocal music generation with performance controls from multi-modal inputs, including style descriptions, audio references, musical scores, and voice prompts. For post-production editing, it offers interactive tools for editing lyrics and vocal melodies directly in the generated audio. We encourage readers to listen to demo audio examples at https://team.doubao.com/seed-music .
Improving Audio Generation with Visual Enhanced Caption
Jul 05, 2024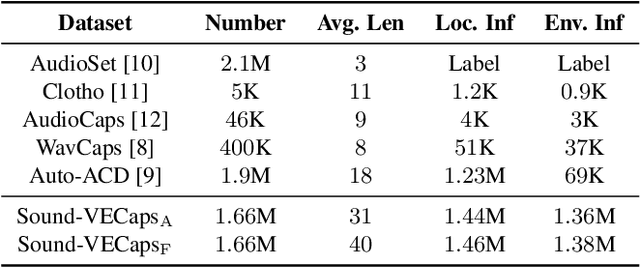

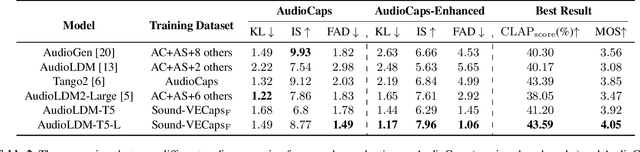

Generative models have shown significant achievements in audio generation tasks. However, existing models struggle with complex and detailed prompts, leading to potential performance degradation. We hypothesize that this problem stems from the low quality and relatively small quantity of training data. In this work, we aim to create a large-scale audio dataset with rich captions for improving audio generation models. We develop an automated pipeline to generate detailed captions for audio-visual datasets by transforming predicted visual captions, audio captions, and tagging labels into comprehensive descriptions using a Large Language Model (LLM). We introduce Sound-VECaps, a dataset comprising 1.66M high-quality audio-caption pairs with enriched details including audio event orders, occurred places and environment information. We demonstrate that training with Sound-VECaps significantly enhances the capability of text-to-audio generation models to comprehend and generate audio from complex input prompts, improving overall system performance. Furthermore, we conduct ablation studies of Sound-VECaps across several audio-language tasks, suggesting its potential in advancing audio-text representation learning. Our dataset and models are available online.
Seed-TTS: A Family of High-Quality Versatile Speech Generation Models
Jun 04, 2024



We introduce Seed-TTS, a family of large-scale autoregressive text-to-speech (TTS) models capable of generating speech that is virtually indistinguishable from human speech. Seed-TTS serves as a foundation model for speech generation and excels in speech in-context learning, achieving performance in speaker similarity and naturalness that matches ground truth human speech in both objective and subjective evaluations. With fine-tuning, we achieve even higher subjective scores across these metrics. Seed-TTS offers superior controllability over various speech attributes such as emotion and is capable of generating highly expressive and diverse speech for speakers in the wild. Furthermore, we propose a self-distillation method for speech factorization, as well as a reinforcement learning approach to enhance model robustness, speaker similarity, and controllability. We additionally present a non-autoregressive (NAR) variant of the Seed-TTS model, named $\text{Seed-TTS}_\text{DiT}$, which utilizes a fully diffusion-based architecture. Unlike previous NAR-based TTS systems, $\text{Seed-TTS}_\text{DiT}$ does not depend on pre-estimated phoneme durations and performs speech generation through end-to-end processing. We demonstrate that this variant achieves comparable performance to the language model-based variant and showcase its effectiveness in speech editing. We encourage readers to listen to demos at \url{https://bytedancespeech.github.io/seedtts_tech_report}.
T-CLAP: Temporal-Enhanced Contrastive Language-Audio Pretraining
Apr 27, 2024



Contrastive language-audio pretraining~(CLAP) has been developed to align the representations of audio and language, achieving remarkable performance in retrieval and classification tasks. However, current CLAP struggles to capture temporal information within audio and text features, presenting substantial limitations for tasks such as audio retrieval and generation. To address this gap, we introduce T-CLAP, a temporal-enhanced CLAP model. We use Large Language Models~(LLMs) and mixed-up strategies to generate temporal-contrastive captions for audio clips from extensive audio-text datasets. Subsequently, a new temporal-focused contrastive loss is designed to fine-tune the CLAP model by incorporating these synthetic data. We conduct comprehensive experiments and analysis in multiple downstream tasks. T-CLAP shows improved capability in capturing the temporal relationship of sound events and outperforms state-of-the-art models by a significant margin.
VoiceShop: A Unified Speech-to-Speech Framework for Identity-Preserving Zero-Shot Voice Editing
Apr 11, 2024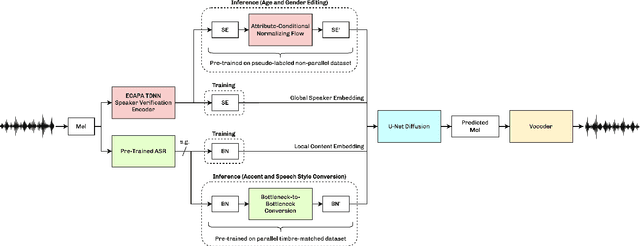
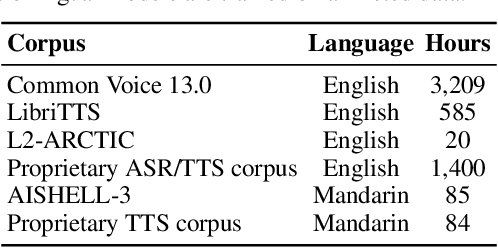

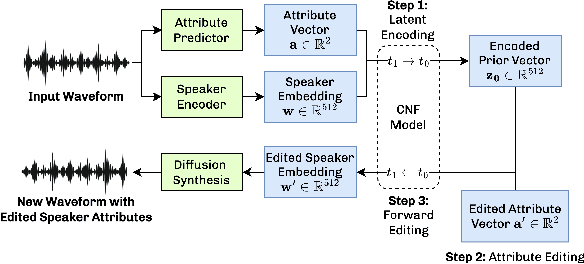
We present VoiceShop, a novel speech-to-speech framework that can modify multiple attributes of speech, such as age, gender, accent, and speech style, in a single forward pass while preserving the input speaker's timbre. Previous works have been constrained to specialized models that can only edit these attributes individually and suffer from the following pitfalls: the magnitude of the conversion effect is weak, there is no zero-shot capability for out-of-distribution speakers, or the synthesized outputs exhibit undesirable timbre leakage. Our work proposes solutions for each of these issues in a simple modular framework based on a conditional diffusion backbone model with optional normalizing flow-based and sequence-to-sequence speaker attribute-editing modules, whose components can be combined or removed during inference to meet a wide array of tasks without additional model finetuning. Audio samples are available at \url{https://voiceshopai.github.io}.
Non-parallel Accent Conversion using Pseudo Siamese Disentanglement Network
Dec 12, 2022



The main goal of accent conversion (AC) is to convert the accent of speech into the target accent while preserving the content and timbre. Previous reference-based methods rely on reference utterances in the inference phase, which limits their practical application. What's more, previous reference-free methods mostly require parallel data in the training phase. In this paper, we propose a reference-free method based on non-parallel data from the perspective of feature disentanglement. Pseudo Siamese Disentanglement Network (PSDN) is proposed to disentangle the accent information from the content representation and model the target accent. Besides, a timbre augmentation method is proposed to enhance the ability of timbre retaining for speakers without target-accent data. Experimental results show that the proposed system can convert the accent of native American English speech into Indian accent with higher accentedness (3.47) than the baseline (2.75) and input (1.19). The naturalness of converted speech is also comparable to that of the input.