 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFoleyDesigner: Immersive Stereo Foley Generation with Precise Spatio-Temporal Alignment for Film Clips
Apr 07, 2026Foley art plays a pivotal role in enhancing immersive auditory experiences in film, yet manual creation of spatio-temporally aligned audio remains labor-intensive. We propose FoleyDesigner, a novel framework inspired by professional Foley workflows, integrating film clip analysis, spatio-temporally controllable Foley generation, and professional audio mixing capabilities. FoleyDesigner employs a multi-agent architecture for precise spatio-temporal analysis. It achieves spatio-temporal alignment through latent diffusion models trained on spatio-temporal cues extracted from video frames, combined with large language model (LLM)-driven hybrid mechanisms that emulate post-production practices in film industry. To address the lack of high-quality stereo audio datasets in film, we introduce FilmStereo, the first professional stereo audio dataset containing spatial metadata, precise timestamps, and semantic annotations for eight common Foley categories. For applications, the framework supports interactive user control while maintaining seamless integration with professional pipelines, including 5.1-channel Dolby Atmos systems compliant with ITU-R BS.775 standards, thereby offering extensive creative flexibility. Extensive experiments demonstrate that our method achieves superior spatio-temporal alignment compared to existing baselines, with seamless compatibility with professional film production standards. The project page is available at https://gekiii996.github.io/FoleyDesigner/ .
The Interspeech 2026 Audio Encoder Capability Challenge for Large Audio Language Models
Mar 24, 2026This paper presents the Interspeech 2026 Audio Encoder Capability Challenge, a benchmark specifically designed to evaluate and advance the performance of pre-trained audio encoders as front-end modules for Large Audio Language Models (LALMs). While LALMs have shown remarkable understanding of complex acoustic scenes, their performance depends on the semantic richness of the underlying audio encoder representations. This challenge addresses the integration gap by providing a unified generative evaluation framework, XARES-LLM, which assesses submitted encoders across a diverse suite of downstream classification and generation tasks. By decoupling encoder development from LLM fine-tuning, the challenge establishes a standardized protocol for general-purpose audio representations that can effectively be used for the next generation of multimodal language models.
BioDCASE 2026 Challenge Baseline for Cross-Domain Mosquito Species Classification
Mar 20, 2026Mosquito-borne diseases affect more than one billion people each year and cause close to one million deaths. Traditional surveillance methods rely on traps and manual identification that are slow, labor-intensive, and difficult to scale. Audio-based mosquito monitoring offers a non-destructive, lower-cost, and more scalable complement to trap-based surveillance, but reliable species classification remains difficult under real-world recording conditions. Mosquito flight tones are narrow-band, often low in signal-to-noise ratio, and easily masked by background noise, and recordings for several epidemiologically relevant species remain limited, creating pronounced class imbalance. Variation across devices, environments, and collection protocols further increases the difficulty of robust classification. Such variation can cause models to rely on domain-specific recording artefacts rather than species-relevant acoustic cues, which makes transfer to new acquisition settings difficult. The BioDCASE 2026 Cross-Domain Mosquito Species Classification (CD-MSC) challenge is designed around this deployment problem by evaluating performance on both seen and unseen domains. This paper presents the official baseline system and evaluation pipeline as a simple, fully reproducible reference for the CD-MSC challenge task. The baseline uses log-mel features and a multitemporal resolution convolutional neural network (MTRCNN) with species and auxiliary domain outputs, together with complete training and test scripts. The baseline system performs strongly on seen domains but degrades markedly on unseen domains, showing that cross-domain generalisation, rather than within-domain recognition, is the central challenge for practical mosquito species classification from multi-source bioacoustic recordings.
RFM-Editing: Rectified Flow Matching for Text-guided Audio Editing
Sep 17, 2025Diffusion models have shown remarkable progress in text-to-audio generation. However, text-guided audio editing remains in its early stages. This task focuses on modifying the target content within an audio signal while preserving the rest, thus demanding precise localization and faithful editing according to the text prompt. Existing training-based and zero-shot methods that rely on full-caption or costly optimization often struggle with complex editing or lack practicality. In this work, we propose a novel end-to-end efficient rectified flow matching-based diffusion framework for audio editing, and construct a dataset featuring overlapping multi-event audio to support training and benchmarking in complex scenarios. Experiments show that our model achieves faithful semantic alignment without requiring auxiliary captions or masks, while maintaining competitive editing quality across metrics.
Teacher-Guided Pseudo Supervision and Cross-Modal Alignment for Audio-Visual Video Parsing
Sep 17, 2025Weakly-supervised audio-visual video parsing (AVVP) seeks to detect audible, visible, and audio-visual events without temporal annotations. Previous work has emphasized refining global predictions through contrastive or collaborative learning, but neglected stable segment-level supervision and class-aware cross-modal alignment. To address this, we propose two strategies: (1) an exponential moving average (EMA)-guided pseudo supervision framework that generates reliable segment-level masks via adaptive thresholds or top-k selection, offering stable temporal guidance beyond video-level labels; and (2) a class-aware cross-modal agreement (CMA) loss that aligns audio and visual embeddings at reliable segment-class pairs, ensuring consistency across modalities while preserving temporal structure. Evaluations on LLP and UnAV-100 datasets shows that our method achieves state-of-the-art (SOTA) performance across multiple metrics.
Region-Specific Audio Tagging for Spatial Sound
Sep 11, 2025Audio tagging aims to label sound events appearing in an audio recording. In this paper, we propose region-specific audio tagging, a new task which labels sound events in a given region for spatial audio recorded by a microphone array. The region can be specified as an angular space or a distance from the microphone. We first study the performance of different combinations of spectral, spatial, and position features. Then we extend state-of-the-art audio tagging systems such as pre-trained audio neural networks (PANNs) and audio spectrogram transformer (AST) to the proposed region-specific audio tagging task. Experimental results on both the simulated and the real datasets show the feasibility of the proposed task and the effectiveness of the proposed method. Further experiments show that incorporating the directional features is beneficial for omnidirectional tagging.
TEn-CATS: Text-Enriched Audio-Visual Video Parsing with Multi-Scale Category-Aware Temporal Graph
Sep 04, 2025Audio-Visual Video Parsing (AVVP) task aims to identify event categories and their occurrence times in a given video with weakly supervised labels. Existing methods typically fall into two categories: (i) designing enhanced architectures based on attention mechanism for better temporal modeling, and (ii) generating richer pseudo-labels to compensate for the absence of frame-level annotations. However, the first type methods treat noisy segment-level pseudo labels as reliable supervision and the second type methods let indiscriminate attention spread them across all frames, the initial errors are repeatedly amplified during training. To address this issue, we propose a method that combines the Bi-Directional Text Fusion (BiT) module and Category-Aware Temporal Graph (CATS) module. Specifically, we integrate the strengths and complementarity of the two previous research directions. We first perform semantic injection and dynamic calibration on audio and visual modality features through the BiT module, to locate and purify cleaner and richer semantic cues. Then, we leverage the CATS module for semantic propagation and connection to enable precise semantic information dissemination across time. Experimental results demonstrate that our proposed method achieves state-of-the-art (SOTA) performance in multiple key indicators on two benchmark datasets, LLP and UnAV-100.
AudioTurbo: Fast Text-to-Audio Generation with Rectified Diffusion
May 28, 2025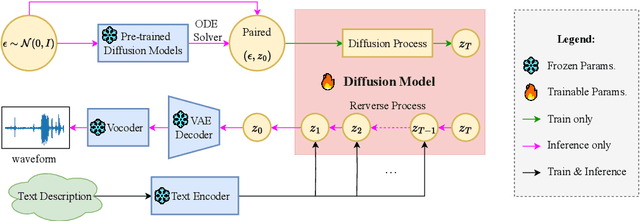
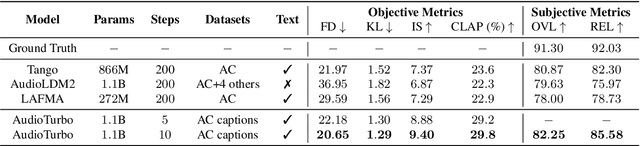
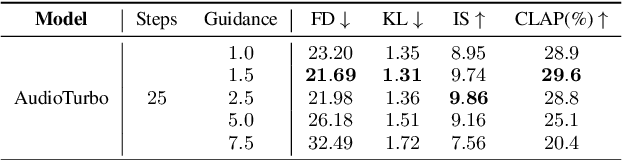
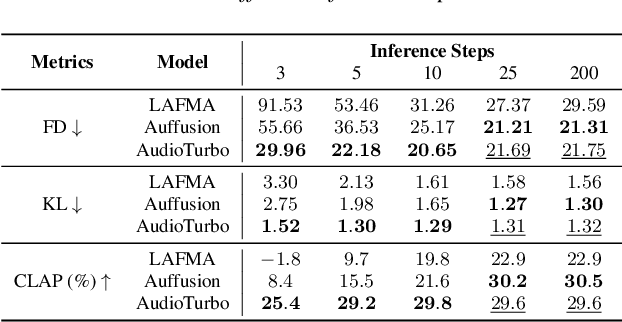
Diffusion models have significantly improved the quality and diversity of audio generation but are hindered by slow inference speed. Rectified flow enhances inference speed by learning straight-line ordinary differential equation (ODE) paths. However, this approach requires training a flow-matching model from scratch and tends to perform suboptimally, or even poorly, at low step counts. To address the limitations of rectified flow while leveraging the advantages of advanced pre-trained diffusion models, this study integrates pre-trained models with the rectified diffusion method to improve the efficiency of text-to-audio (TTA) generation. Specifically, we propose AudioTurbo, which learns first-order ODE paths from deterministic noise sample pairs generated by a pre-trained TTA model. Experiments on the AudioCaps dataset demonstrate that our model, with only 10 sampling steps, outperforms prior models and reduces inference to 3 steps compared to a flow-matching-based acceleration model.
EnvSDD: Benchmarking Environmental Sound Deepfake Detection
May 25, 2025Audio generation systems now create very realistic soundscapes that can enhance media production, but also pose potential risks. Several studies have examined deepfakes in speech or singing voice. However, environmental sounds have different characteristics, which may make methods for detecting speech and singing deepfakes less effective for real-world sounds. In addition, existing datasets for environmental sound deepfake detection are limited in scale and audio types. To address this gap, we introduce EnvSDD, the first large-scale curated dataset designed for this task, consisting of 45.25 hours of real and 316.74 hours of fake audio. The test set includes diverse conditions to evaluate the generalizability, such as unseen generation models and unseen datasets. We also propose an audio deepfake detection system, based on a pre-trained audio foundation model. Results on EnvSDD show that our proposed system outperforms the state-of-the-art systems from speech and singing domains.
From Aesthetics to Human Preferences: Comparative Perspectives of Evaluating Text-to-Music Systems
Apr 30, 2025Evaluating generative models remains a fundamental challenge, particularly when the goal is to reflect human preferences. In this paper, we use music generation as a case study to investigate the gap between automatic evaluation metrics and human preferences. We conduct comparative experiments across five state-of-the-art music generation approaches, assessing both perceptual quality and distributional similarity to human-composed music. Specifically, we evaluate synthesis music from various perceptual dimensions and examine reference-based metrics such as Mauve Audio Divergence (MAD) and Kernel Audio Distance (KAD). Our findings reveal significant inconsistencies across the different metrics, highlighting the limitation of the current evaluation practice. To support further research, we release a benchmark dataset comprising samples from multiple models. This study provides a broader perspective on the alignment of human preference in generative modeling, advocating for more human-centered evaluation strategies across domains.