 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetaSlot: Break Through the Fixed Number of Slots in Object-Centric Learning
May 27, 2025Learning object-level, structured representations is widely regarded as a key to better generalization in vision and underpins the design of next-generation Pre-trained Vision Models (PVMs). Mainstream Object-Centric Learning (OCL) methods adopt Slot Attention or its variants to iteratively aggregate objects' super-pixels into a fixed set of query feature vectors, termed slots. However, their reliance on a static slot count leads to an object being represented as multiple parts when the number of objects varies. We introduce MetaSlot, a plug-and-play Slot Attention variant that adapts to variable object counts. MetaSlot (i) maintains a codebook that holds prototypes of objects in a dataset by vector-quantizing the resulting slot representations; (ii) removes duplicate slots from the traditionally aggregated slots by quantizing them with the codebook; and (iii) injects progressively weaker noise into the Slot Attention iterations to accelerate and stabilize the aggregation. MetaSlot is a general Slot Attention variant that can be seamlessly integrated into existing OCL architectures. Across multiple public datasets and tasks--including object discovery and recognition--models equipped with MetaSlot achieve significant performance gains and markedly interpretable slot representations, compared with existing Slot Attention variants.
DMAGaze: Gaze Estimation Based on Feature Disentanglement and Multi-Scale Attention
Apr 15, 2025Gaze estimation, which predicts gaze direction, commonly faces the challenge of interference from complex gaze-irrelevant information in face images. In this work, we propose DMAGaze, a novel gaze estimation framework that exploits information from facial images in three aspects: gaze-relevant global features (disentangled from facial image), local eye features (extracted from cropped eye patch), and head pose estimation features, to improve overall performance. Firstly, we design a new continuous mask-based Disentangler to accurately disentangle gaze-relevant and gaze-irrelevant information in facial images by achieving the dual-branch disentanglement goal through separately reconstructing the eye and non-eye regions. Furthermore, we introduce a new cascaded attention module named Multi-Scale Global Local Attention Module (MS-GLAM). Through a customized cascaded attention structure, it effectively focuses on global and local information at multiple scales, further enhancing the information from the Disentangler. Finally, the global gaze-relevant features disentangled by the upper face branch, combined with head pose and local eye features, are passed through the detection head for high-precision gaze estimation. Our proposed DMAGaze has been extensively validated on two mainstream public datasets, achieving state-of-the-art performance.
Amazon SageMaker Model Parallelism: A General and Flexible Framework for Large Model Training
Nov 10, 2021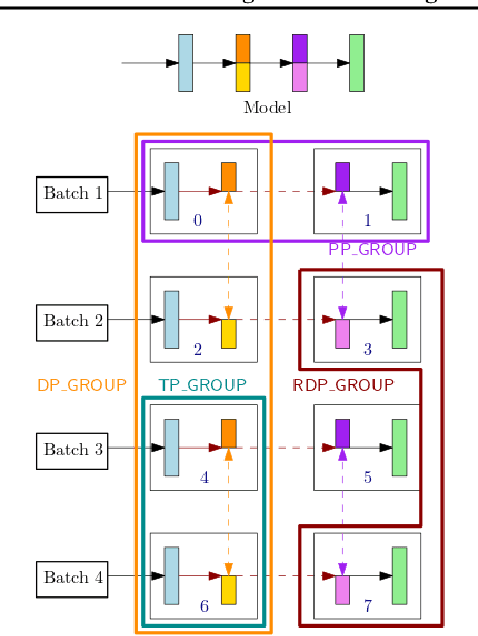
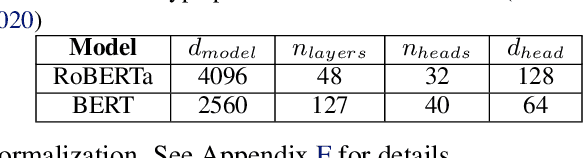
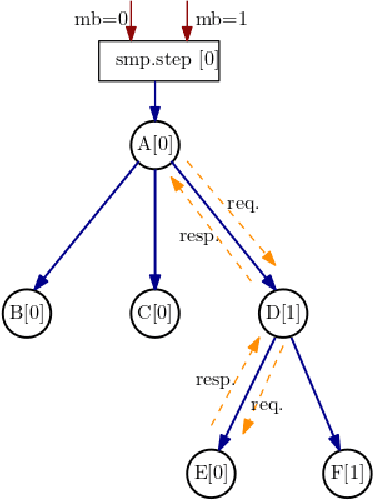

With deep learning models rapidly growing in size, systems-level solutions for large-model training are required. We present Amazon SageMaker model parallelism, a software library that integrates with PyTorch, and enables easy training of large models using model parallelism and other memory-saving features. In contrast to existing solutions, the implementation of the SageMaker library is much more generic and flexible, in that it can automatically partition and run pipeline parallelism over arbitrary model architectures with minimal code change, and also offers a general and extensible framework for tensor parallelism, which supports a wider range of use cases, and is modular enough to be easily applied to new training scripts. The library also preserves the native PyTorch user experience to a much larger degree, supporting module re-use and dynamic graphs, while giving the user full control over the details of the training step. We evaluate performance over GPT-3, RoBERTa, BERT, and neural collaborative filtering, and demonstrate competitive performance over existing solutions.