 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAmazon SageMaker Model Parallelism: A General and Flexible Framework for Large Model Training
Nov 10, 2021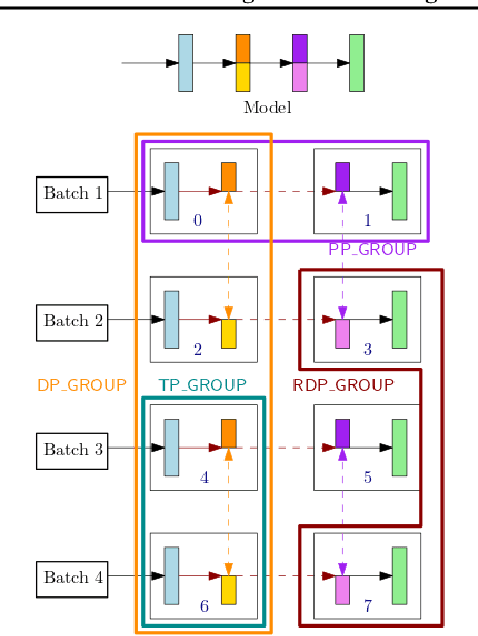
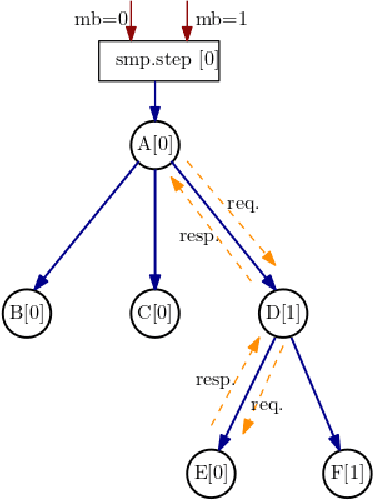

With deep learning models rapidly growing in size, systems-level solutions for large-model training are required. We present Amazon SageMaker model parallelism, a software library that integrates with PyTorch, and enables easy training of large models using model parallelism and other memory-saving features. In contrast to existing solutions, the implementation of the SageMaker library is much more generic and flexible, in that it can automatically partition and run pipeline parallelism over arbitrary model architectures with minimal code change, and also offers a general and extensible framework for tensor parallelism, which supports a wider range of use cases, and is modular enough to be easily applied to new training scripts. The library also preserves the native PyTorch user experience to a much larger degree, supporting module re-use and dynamic graphs, while giving the user full control over the details of the training step. We evaluate performance over GPT-3, RoBERTa, BERT, and neural collaborative filtering, and demonstrate competitive performance over existing solutions.
Densifying Assumed-sparse Tensors: Improving Memory Efficiency and MPI Collective Performance during Tensor Accumulation for Parallelized Training of Neural Machine Translation Models
May 10, 2019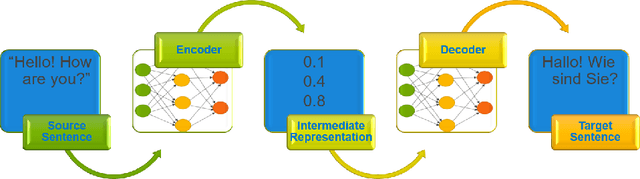


Neural machine translation - using neural networks to translate human language - is an area of active research exploring new neuron types and network topologies with the goal of dramatically improving machine translation performance. Current state-of-the-art approaches, such as the multi-head attention-based transformer, require very large translation corpuses and many epochs to produce models of reasonable quality. Recent attempts to parallelize the official TensorFlow "Transformer" model across multiple nodes have hit roadblocks due to excessive memory use and resulting out of memory errors when performing MPI collectives. This paper describes modifications made to the Horovod MPI-based distributed training framework to reduce memory usage for transformer models by converting assumed-sparse tensors to dense tensors, and subsequently replacing sparse gradient gather with dense gradient reduction. The result is a dramatic increase in scale-out capability, with CPU-only scaling tests achieving 91% weak scaling efficiency up to 1200 MPI processes (300 nodes), and up to 65% strong scaling efficiency up to 400 MPI processes (200 nodes) using the Stampede2 supercomputer.