 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReduced Precision Strategies for Deep Learning: A High Energy Physics Generative Adversarial Network Use Case
Mar 18, 2021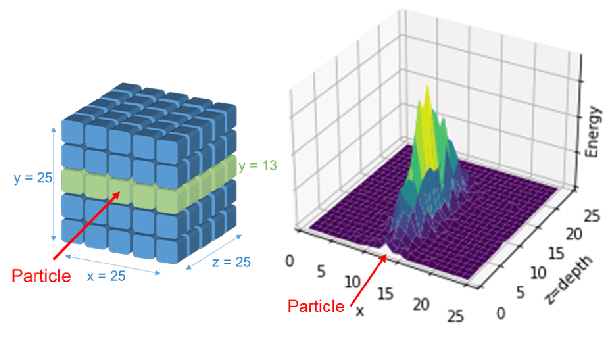
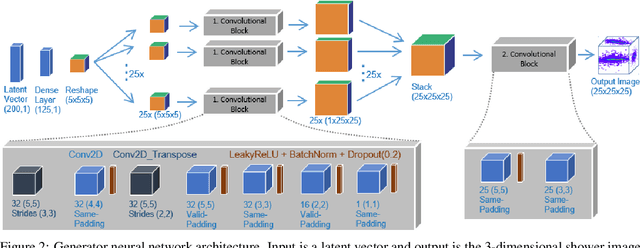

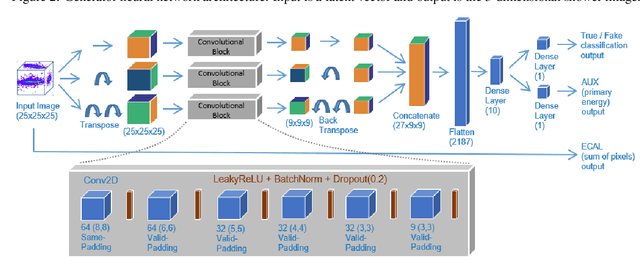
Deep learning is finding its way into high energy physics by replacing traditional Monte Carlo simulations. However, deep learning still requires an excessive amount of computational resources. A promising approach to make deep learning more efficient is to quantize the parameters of the neural networks to reduced precision. Reduced precision computing is extensively used in modern deep learning and results to lower execution inference time, smaller memory footprint and less memory bandwidth. In this paper we analyse the effects of low precision inference on a complex deep generative adversarial network model. The use case which we are addressing is calorimeter detector simulations of subatomic particle interactions in accelerator based high energy physics. We employ the novel Intel low precision optimization tool (iLoT) for quantization and compare the results to the quantized model from TensorFlow Lite. In the performance benchmark we gain a speed-up of 1.73x on Intel hardware for the quantized iLoT model compared to the initial, not quantized, model. With different physics-inspired self-developed metrics, we validate that the quantized iLoT model shows a lower loss of physical accuracy in comparison to the TensorFlow Lite model.
* Submitted at ICPRAM 2021; from CERN openlab - Intel collaboration
Training Multiscale-CNN for Large Microscopy Image Classification in One Hour
Oct 03, 2019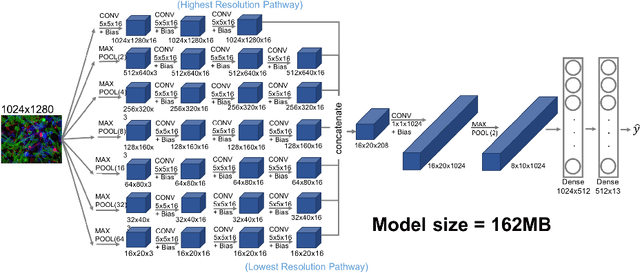

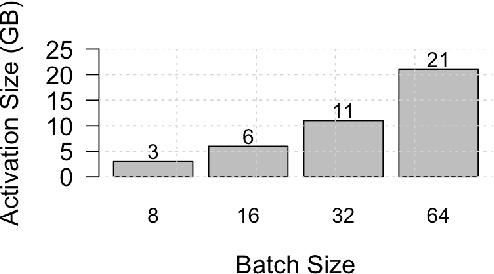
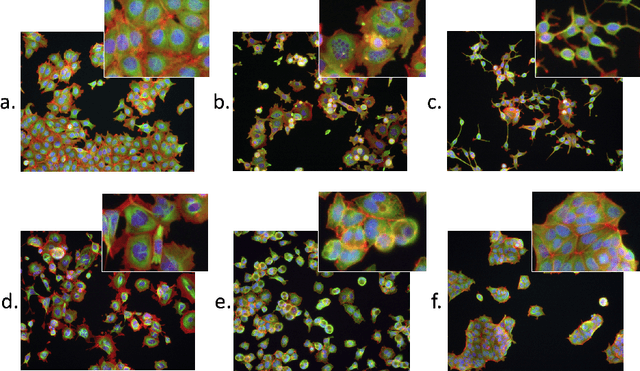
Existing approaches to train neural networks that use large images require to either crop or down-sample data during pre-processing, use small batch sizes, or split the model across devices mainly due to the prohibitively limited memory capacity available on GPUs and emerging accelerators. These techniques often lead to longer time to convergence or time to train (TTT), and in some cases, lower model accuracy. CPUs, on the other hand, can leverage significant amounts of memory. While much work has been done on parallelizing neural network training on multiple CPUs, little attention has been given to tune neural network training with large images on CPUs. In this work, we train a multi-scale convolutional neural network (M-CNN) to classify large biomedical images for high content screening in one hour. The ability to leverage large memory capacity on CPUs enables us to scale to larger batch sizes without having to crop or down-sample the input images. In conjunction with large batch sizes, we find a generalized methodology of linearly scaling of learning rate and train M-CNN to state-of-the-art (SOTA) accuracy of 99% within one hour. We achieve fast time to convergence using 128 two socket Intel Xeon 6148 processor nodes with 192GB DDR4 memory connected with 100Gbps Intel Omnipath architecture.
* 15 pages, 10 figures
Efficient 8-Bit Quantization of Transformer Neural Machine Language Translation Model
Jun 07, 2019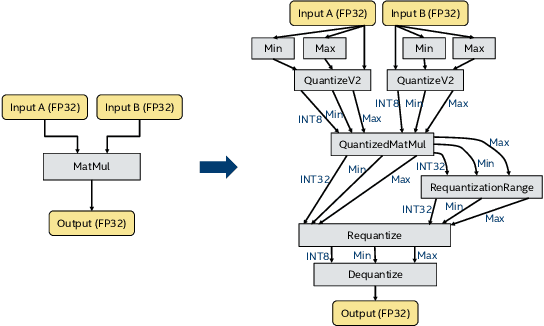
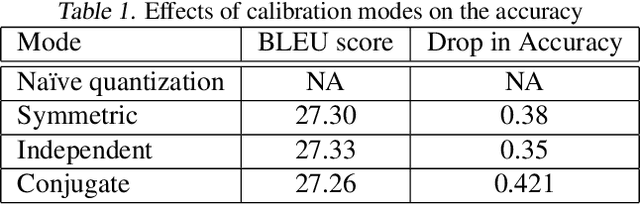
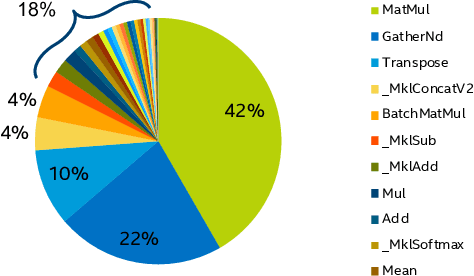
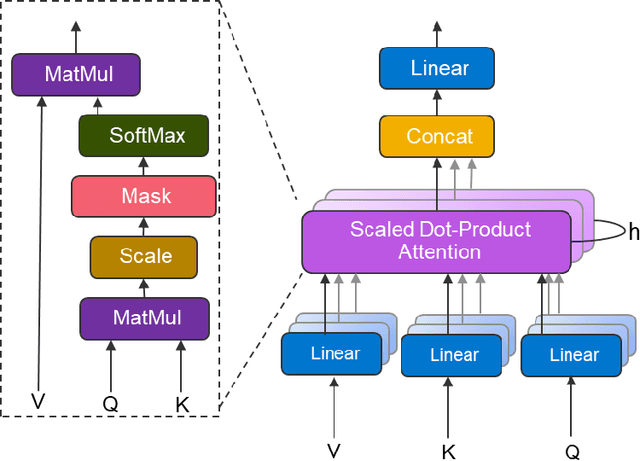
In this work, we quantize a trained Transformer machine language translation model leveraging INT8/VNNI instructions in the latest Intel$^\circledR$ Xeon$^\circledR$ Cascade Lake processors to improve inference performance while maintaining less than 0.5$\%$ drop in accuracy. To the best of our knowledge, this is the first attempt in the industry to quantize the Transformer model. This has high impact as it clearly demonstrates the various complexities of quantizing the language translation model. We present novel quantization techniques directly in TensorFlow to opportunistically replace 32-bit floating point (FP32) computations with 8-bit integers (INT8) and transform the FP32 computational graph. We also present a bin-packing parallel batching technique to maximize CPU utilization. Overall, our optimizations with INT8/VNNI deliver 1.5X improvement over the best FP32 performance. Furthermore, it reveals the opportunities and challenges to boost performance of quantized deep learning inference and establishes best practices to run inference with high efficiency on Intel CPUs.
Densifying Assumed-sparse Tensors: Improving Memory Efficiency and MPI Collective Performance during Tensor Accumulation for Parallelized Training of Neural Machine Translation Models
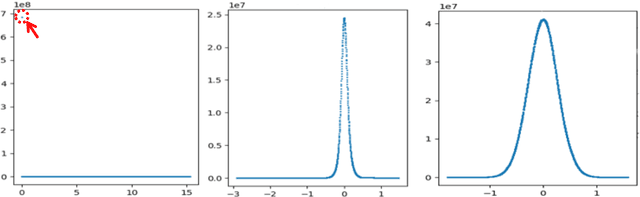
May 10, 2019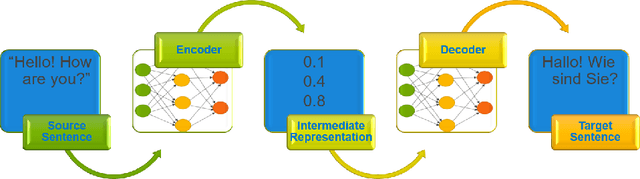


Neural machine translation - using neural networks to translate human language - is an area of active research exploring new neuron types and network topologies with the goal of dramatically improving machine translation performance. Current state-of-the-art approaches, such as the multi-head attention-based transformer, require very large translation corpuses and many epochs to produce models of reasonable quality. Recent attempts to parallelize the official TensorFlow "Transformer" model across multiple nodes have hit roadblocks due to excessive memory use and resulting out of memory errors when performing MPI collectives. This paper describes modifications made to the Horovod MPI-based distributed training framework to reduce memory usage for transformer models by converting assumed-sparse tensors to dense tensors, and subsequently replacing sparse gradient gather with dense gradient reduction. The result is a dramatic increase in scale-out capability, with CPU-only scaling tests achieving 91% weak scaling efficiency up to 1200 MPI processes (300 nodes), and up to 65% strong scaling efficiency up to 400 MPI processes (200 nodes) using the Stampede2 supercomputer.
Scale out for large minibatch SGD: Residual network training on ImageNet-1K with improved accuracy and reduced time to train
Nov 15, 2017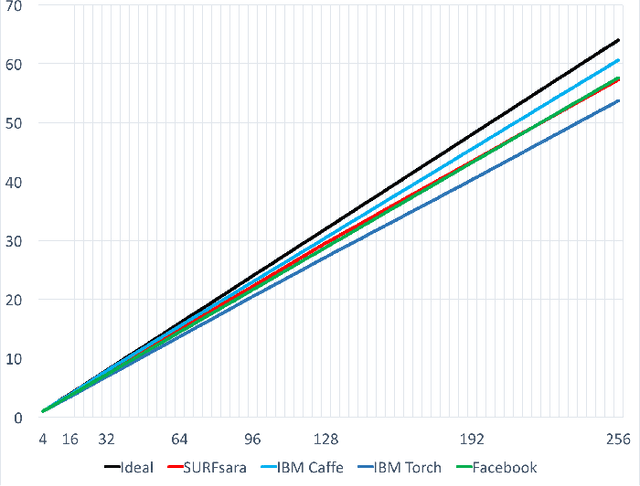
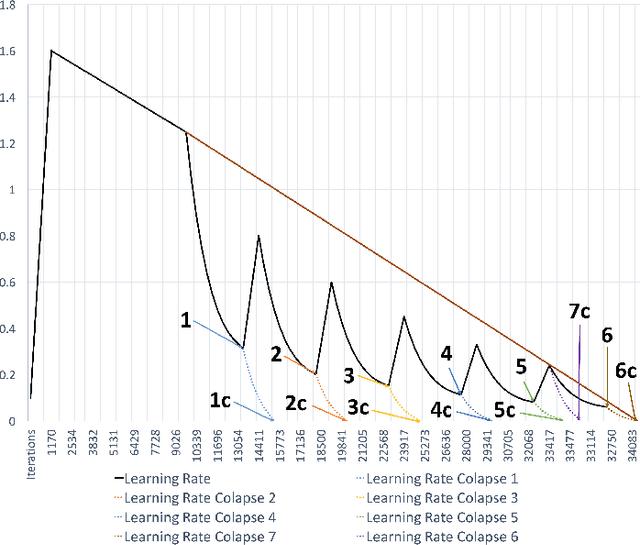
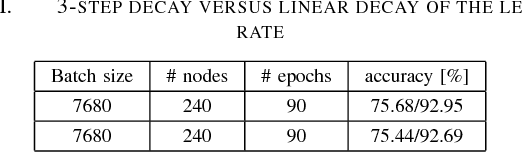
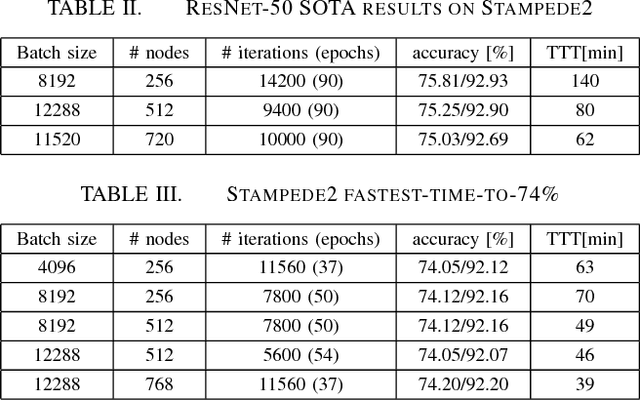
For the past 5 years, the ILSVRC competition and the ImageNet dataset have attracted a lot of interest from the Computer Vision community, allowing for state-of-the-art accuracy to grow tremendously. This should be credited to the use of deep artificial neural network designs. As these became more complex, the storage, bandwidth, and compute requirements increased. This means that with a non-distributed approach, even when using the most high-density server available, the training process may take weeks, making it prohibitive. Furthermore, as datasets grow, the representation learning potential of deep networks grows as well by using more complex models. This synchronicity triggers a sharp increase in the computational requirements and motivates us to explore the scaling behaviour on petaflop scale supercomputers. In this paper we will describe the challenges and novel solutions needed in order to train ResNet-50 in this large scale environment. We demonstrate above 90\% scaling efficiency and a training time of 28 minutes using up to 104K x86 cores. This is supported by software tools from Intel's ecosystem. Moreover, we show that with regular 90 - 120 epoch train runs we can achieve a top-1 accuracy as high as 77\% for the unmodified ResNet-50 topology. We also introduce the novel Collapsed Ensemble (CE) technique that allows us to obtain a 77.5\% top-1 accuracy, similar to that of a ResNet-152, while training a unmodified ResNet-50 topology for the same fixed training budget. All ResNet-50 models as well as the scripts needed to replicate them will be posted shortly.