 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysics Validation of Novel Convolutional 2D Architectures for Speeding Up High Energy Physics Simulations
May 19, 2021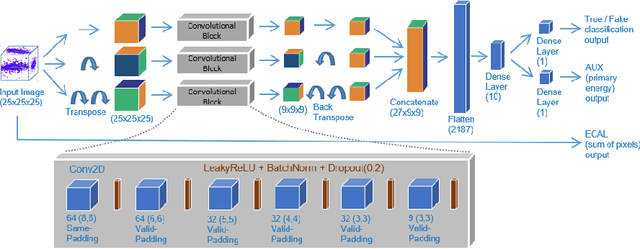


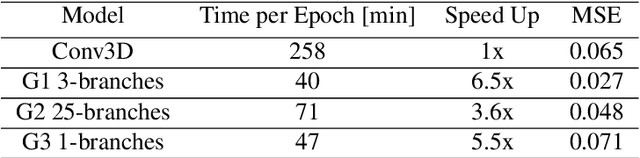
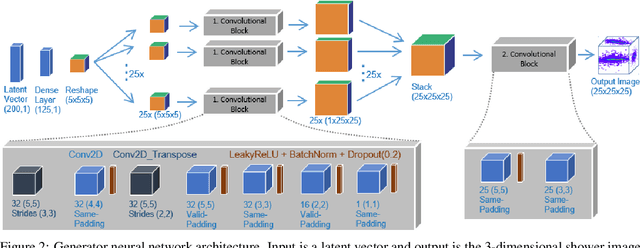
The precise simulation of particle transport through detectors remains a key element for the successful interpretation of high energy physics results. However, Monte Carlo based simulation is extremely demanding in terms of computing resources. This challenge motivates investigations of faster, alternative approaches for replacing the standard Monte Carlo approach. We apply Generative Adversarial Networks (GANs), a deep learning technique, to replace the calorimeter detector simulations and speeding up the simulation time by orders of magnitude. We follow a previous approach which used three-dimensional convolutional neural networks and develop new two-dimensional convolutional networks to solve the same 3D image generation problem faster. Additionally, we increased the number of parameters and the neural networks representational power, obtaining a higher accuracy. We compare our best convolutional 2D neural network architecture and evaluate it versus the previous 3D architecture and Geant4 data. Our results demonstrate a high physics accuracy and further consolidate the use of GANs for fast detector simulations.
Reduced Precision Strategies for Deep Learning: A High Energy Physics Generative Adversarial Network Use Case
Mar 18, 2021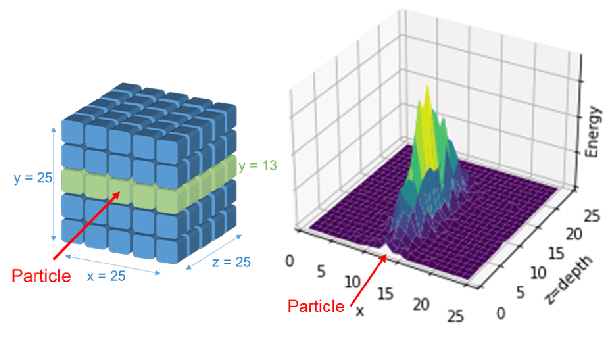

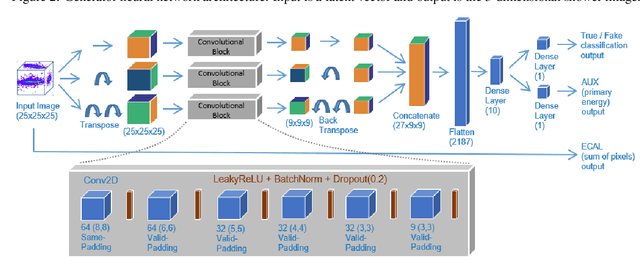
Deep learning is finding its way into high energy physics by replacing traditional Monte Carlo simulations. However, deep learning still requires an excessive amount of computational resources. A promising approach to make deep learning more efficient is to quantize the parameters of the neural networks to reduced precision. Reduced precision computing is extensively used in modern deep learning and results to lower execution inference time, smaller memory footprint and less memory bandwidth. In this paper we analyse the effects of low precision inference on a complex deep generative adversarial network model. The use case which we are addressing is calorimeter detector simulations of subatomic particle interactions in accelerator based high energy physics. We employ the novel Intel low precision optimization tool (iLoT) for quantization and compare the results to the quantized model from TensorFlow Lite. In the performance benchmark we gain a speed-up of 1.73x on Intel hardware for the quantized iLoT model compared to the initial, not quantized, model. With different physics-inspired self-developed metrics, we validate that the quantized iLoT model shows a lower loss of physical accuracy in comparison to the TensorFlow Lite model.
* Submitted at ICPRAM 2021; from CERN openlab - Intel collaboration