 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a high-performance AI compiler with upstream MLIR
Apr 15, 2024



This work proposes a compilation flow using open-source compiler passes to build a framework to achieve ninja performance from a generic linear algebra high-level abstraction. We demonstrate this flow with a proof-of-concept MLIR project that uses input IR in Linalg-on-Tensor from TensorFlow and PyTorch, performs cache-level optimizations and lowering to micro-kernels for efficient vectorization, achieving over 90% of the performance of ninja-written equivalent programs. The contributions of this work include: (1) Packing primitives on the tensor dialect and passes for cache-aware distribution of tensors (single and multi-core) and type-aware instructions (VNNI, BFDOT, BFMMLA), including propagation of shapes across the entire function; (2) A linear algebra pipeline, including tile, fuse and bufferization strategies to get model-level IR into hardware friendly tile calls; (3) A mechanism for micro-kernel lowering to an open source library that supports various CPUs.
Harnessing Deep Learning and HPC Kernels via High-Level Loop and Tensor Abstractions on CPU Architectures
Apr 25, 2023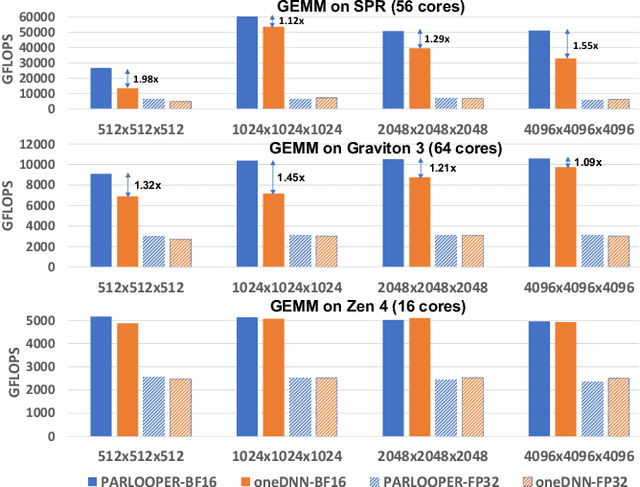
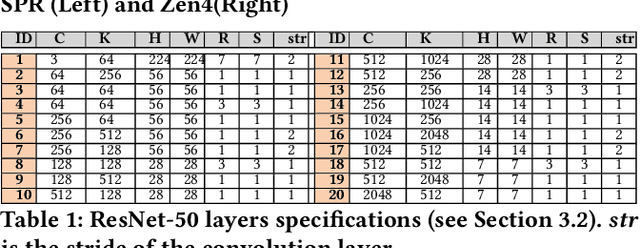
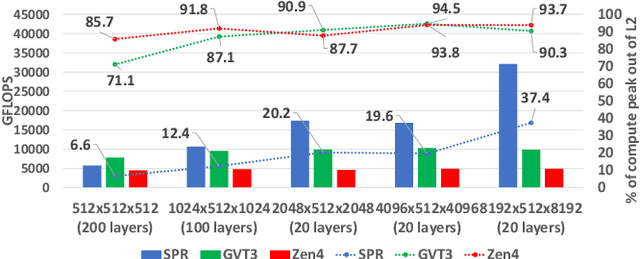
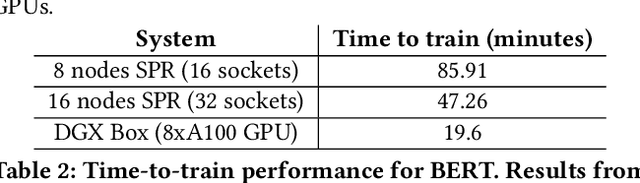
During the past decade, Deep Learning (DL) algorithms, programming systems and hardware have converged with the High Performance Computing (HPC) counterparts. Nevertheless, the programming methodology of DL and HPC systems is stagnant, relying on highly-optimized, yet platform-specific and inflexible vendor-optimized libraries. Such libraries provide close-to-peak performance on specific platforms, kernels and shapes thereof that vendors have dedicated optimizations efforts, while they underperform in the remaining use-cases, yielding non-portable codes with performance glass-jaws. This work introduces a framework to develop efficient, portable DL and HPC kernels for modern CPU architectures. We decompose the kernel development in two steps: 1) Expressing the computational core using Tensor Processing Primitives (TPPs): a compact, versatile set of 2D-tensor operators, 2) Expressing the logical loops around TPPs in a high-level, declarative fashion whereas the exact instantiation (ordering, tiling, parallelization) is determined via simple knobs. We demonstrate the efficacy of our approach using standalone kernels and end-to-end workloads that outperform state-of-the-art implementations on diverse CPU platforms.
Tensor Processing Primitives: A Programming Abstraction for Efficiency and Portability in Deep Learning Workloads
Apr 14, 2021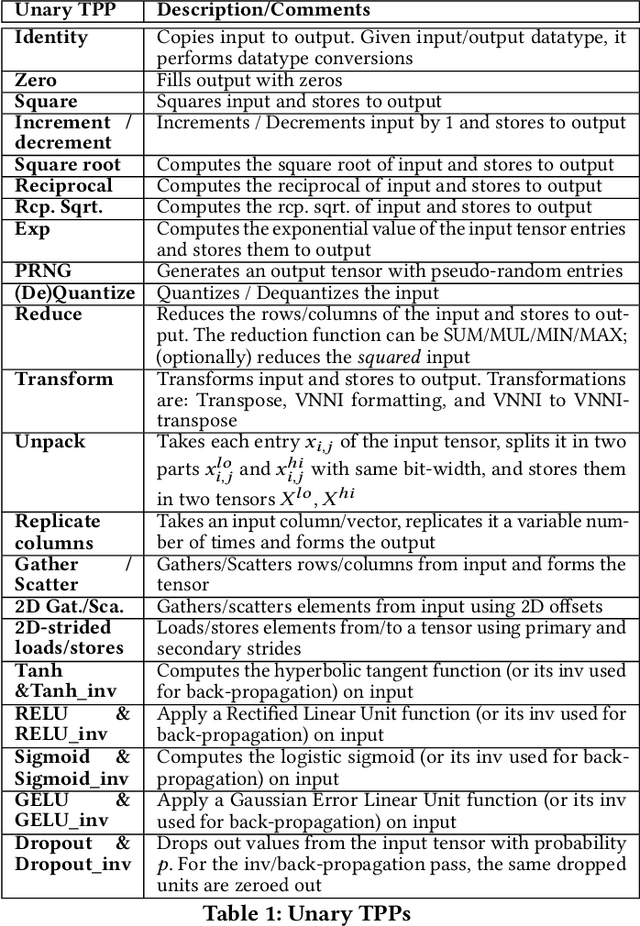
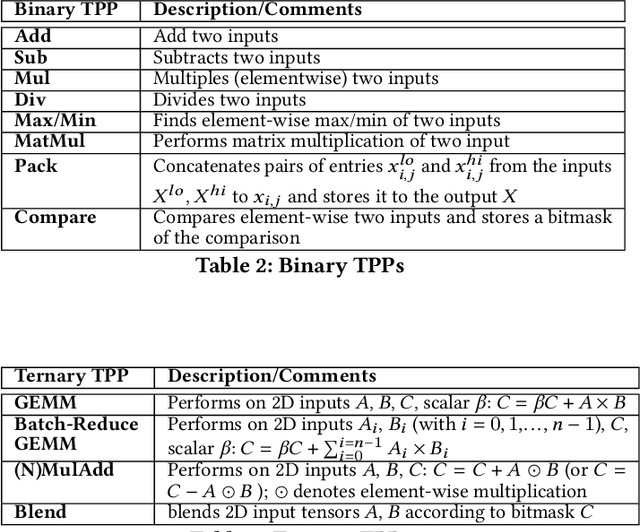
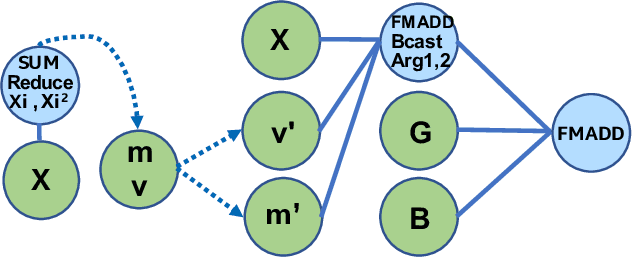
During the past decade, novel Deep Learning (DL) algorithms/workloads and hardware have been developed to tackle a wide range of problems. Despite the advances in workload/hardware ecosystems, the programming methodology of DL-systems is stagnant. DL-workloads leverage either highly-optimized, yet platform-specific and inflexible kernels from DL-libraries, or in the case of novel operators, reference implementations are built via DL-framework primitives with underwhelming performance. This work introduces the Tensor Processing Primitives (TPP), a programming abstraction striving for efficient, portable implementation of DL-workloads with high-productivity. TPPs define a compact, yet versatile set of 2D-tensor operators (or a virtual Tensor ISA), which subsequently can be utilized as building-blocks to construct complex operators on high-dimensional tensors. The TPP specification is platform-agnostic, thus code expressed via TPPs is portable, whereas the TPP implementation is highly-optimized and platform-specific. We demonstrate the efficacy of our approach using standalone kernels and end-to-end DL-workloads expressed entirely via TPPs that outperform state-of-the-art implementations on multiple platforms.
Reduced Precision Strategies for Deep Learning: A High Energy Physics Generative Adversarial Network Use Case
Mar 18, 2021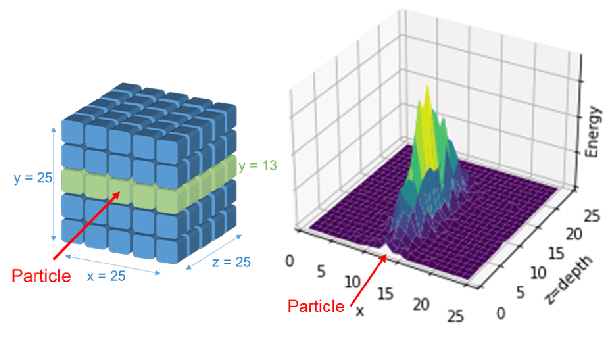
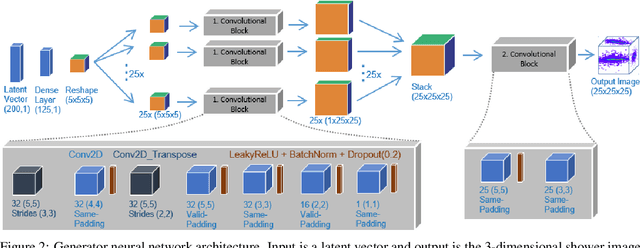

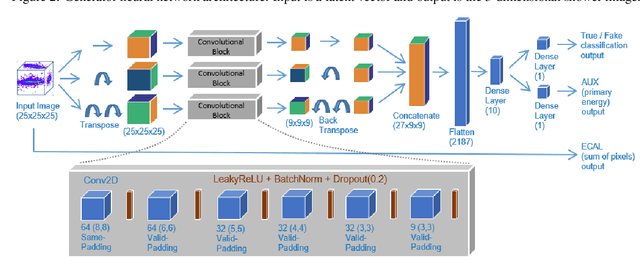
Deep learning is finding its way into high energy physics by replacing traditional Monte Carlo simulations. However, deep learning still requires an excessive amount of computational resources. A promising approach to make deep learning more efficient is to quantize the parameters of the neural networks to reduced precision. Reduced precision computing is extensively used in modern deep learning and results to lower execution inference time, smaller memory footprint and less memory bandwidth. In this paper we analyse the effects of low precision inference on a complex deep generative adversarial network model. The use case which we are addressing is calorimeter detector simulations of subatomic particle interactions in accelerator based high energy physics. We employ the novel Intel low precision optimization tool (iLoT) for quantization and compare the results to the quantized model from TensorFlow Lite. In the performance benchmark we gain a speed-up of 1.73x on Intel hardware for the quantized iLoT model compared to the initial, not quantized, model. With different physics-inspired self-developed metrics, we validate that the quantized iLoT model shows a lower loss of physical accuracy in comparison to the TensorFlow Lite model.
* Submitted at ICPRAM 2021; from CERN openlab - Intel collaboration
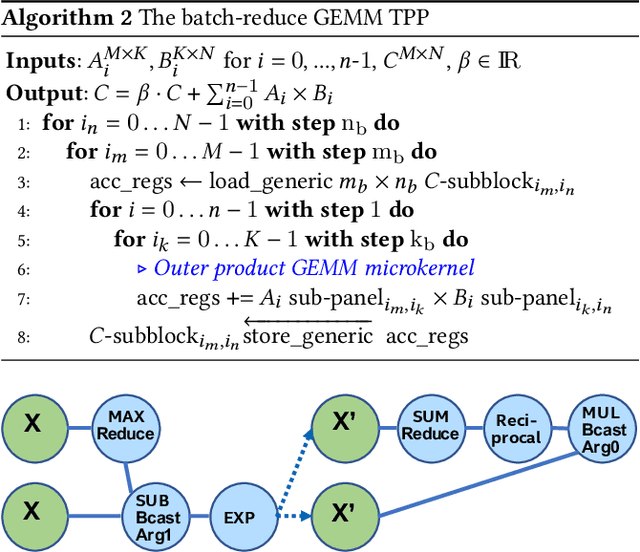
High-Performance Deep Learning via a Single Building Block
Jun 18, 2019


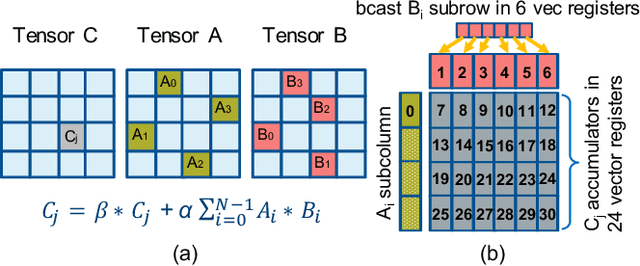
Deep learning (DL) is one of the most prominent branches of machine learning. Due to the immense computational cost of DL workloads, industry and academia have developed DL libraries with highly-specialized kernels for each workload/architecture, leading to numerous, complex code-bases that strive for performance, yet they are hard to maintain and do not generalize. In this work, we introduce the batch-reduce GEMM kernel and show how the most popular DL algorithms can be formulated with this kernel as the basic building-block. Consequently, the DL library-development degenerates to mere (potentially automatic) tuning of loops around this sole optimized kernel. By exploiting our new kernel we implement Recurrent Neural Networks, Convolution Neural Networks and Multilayer Perceptron training and inference primitives in just 3K lines of high-level code. Our primitives outperform vendor-optimized libraries on multi-node CPU clusters, and we also provide proof-of-concept CNN kernels targeting GPUs. Finally, we demonstrate that the batch-reduce GEMM kernel within a tensor compiler yields high-performance CNN primitives, further amplifying the viability of our approach.
Machine Learning in High Energy Physics Community White Paper
Jul 08, 2018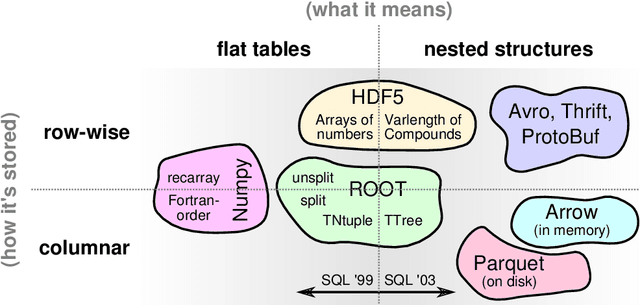
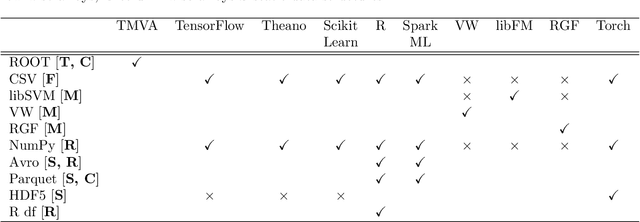

Machine learning is an important research area in particle physics, beginning with applications to high-level physics analysis in the 1990s and 2000s, followed by an explosion of applications in particle and event identification and reconstruction in the 2010s. In this document we discuss promising future research and development areas in machine learning in particle physics with a roadmap for their implementation, software and hardware resource requirements, collaborative initiatives with the data science community, academia and industry, and training the particle physics community in data science. The main objective of the document is to connect and motivate these areas of research and development with the physics drivers of the High-Luminosity Large Hadron Collider and future neutrino experiments and identify the resource needs for their implementation. Additionally we identify areas where collaboration with external communities will be of great benefit.