 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHarnessing Deep Learning and HPC Kernels via High-Level Loop and Tensor Abstractions on CPU Architectures
Apr 25, 2023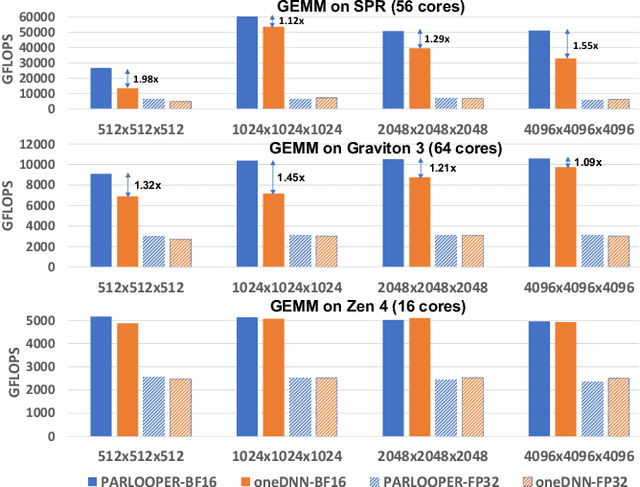
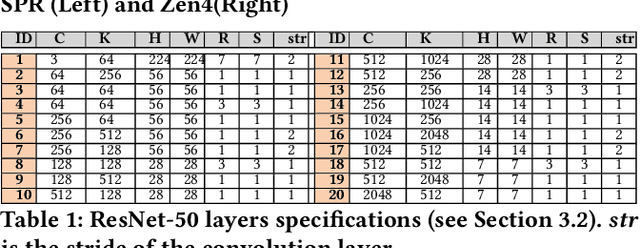
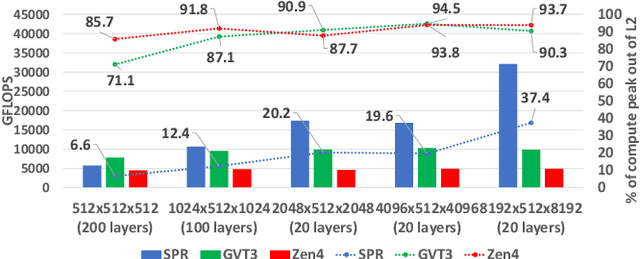
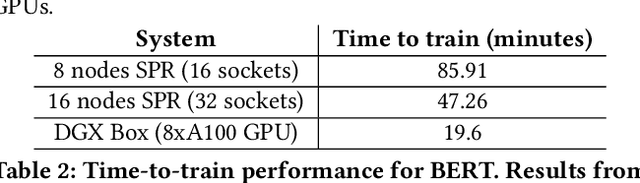
During the past decade, Deep Learning (DL) algorithms, programming systems and hardware have converged with the High Performance Computing (HPC) counterparts. Nevertheless, the programming methodology of DL and HPC systems is stagnant, relying on highly-optimized, yet platform-specific and inflexible vendor-optimized libraries. Such libraries provide close-to-peak performance on specific platforms, kernels and shapes thereof that vendors have dedicated optimizations efforts, while they underperform in the remaining use-cases, yielding non-portable codes with performance glass-jaws. This work introduces a framework to develop efficient, portable DL and HPC kernels for modern CPU architectures. We decompose the kernel development in two steps: 1) Expressing the computational core using Tensor Processing Primitives (TPPs): a compact, versatile set of 2D-tensor operators, 2) Expressing the logical loops around TPPs in a high-level, declarative fashion whereas the exact instantiation (ordering, tiling, parallelization) is determined via simple knobs. We demonstrate the efficacy of our approach using standalone kernels and end-to-end workloads that outperform state-of-the-art implementations on diverse CPU platforms.
Tensor Processing Primitives: A Programming Abstraction for Efficiency and Portability in Deep Learning Workloads
Apr 14, 2021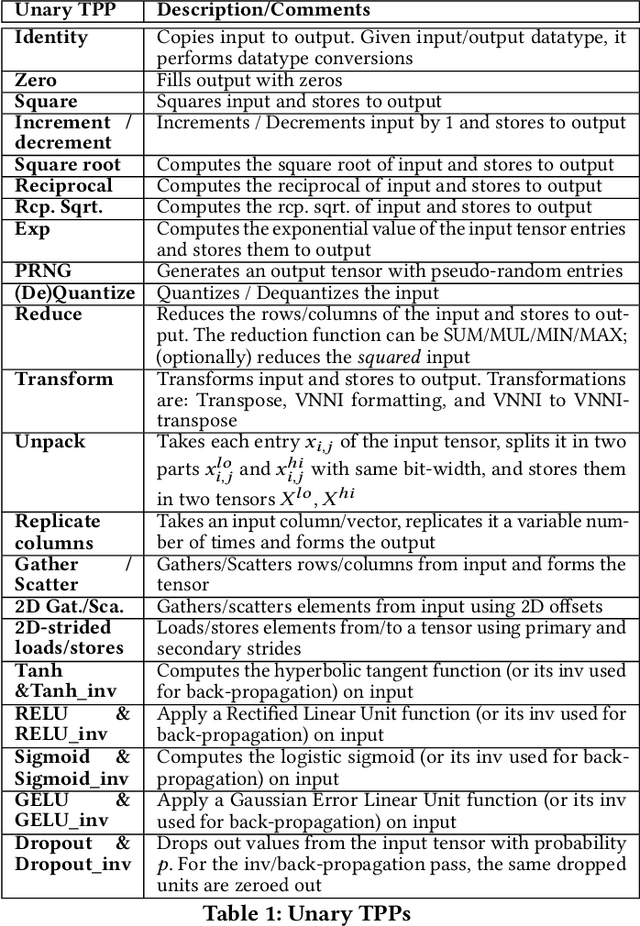
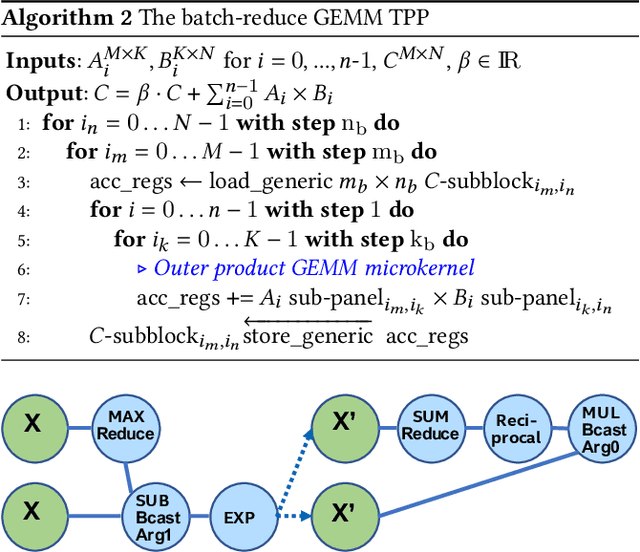
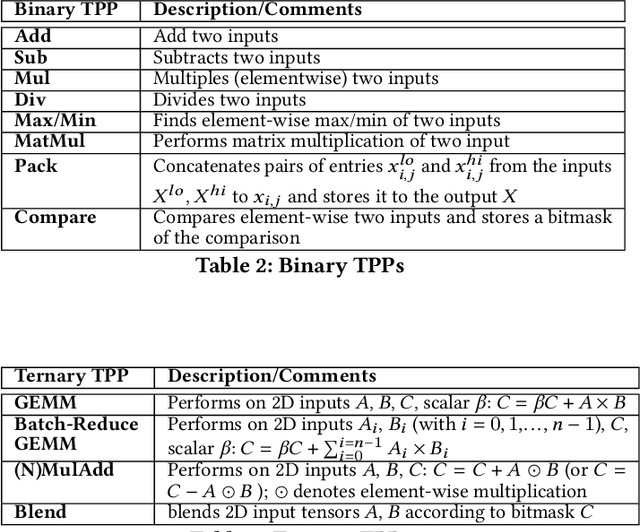
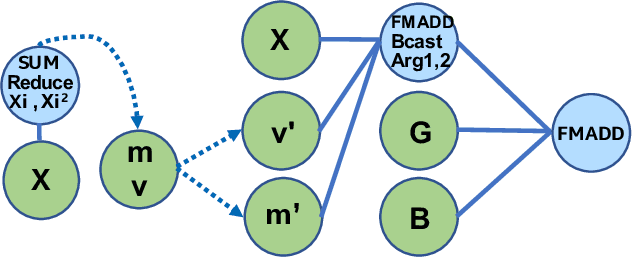
During the past decade, novel Deep Learning (DL) algorithms/workloads and hardware have been developed to tackle a wide range of problems. Despite the advances in workload/hardware ecosystems, the programming methodology of DL-systems is stagnant. DL-workloads leverage either highly-optimized, yet platform-specific and inflexible kernels from DL-libraries, or in the case of novel operators, reference implementations are built via DL-framework primitives with underwhelming performance. This work introduces the Tensor Processing Primitives (TPP), a programming abstraction striving for efficient, portable implementation of DL-workloads with high-productivity. TPPs define a compact, yet versatile set of 2D-tensor operators (or a virtual Tensor ISA), which subsequently can be utilized as building-blocks to construct complex operators on high-dimensional tensors. The TPP specification is platform-agnostic, thus code expressed via TPPs is portable, whereas the TPP implementation is highly-optimized and platform-specific. We demonstrate the efficacy of our approach using standalone kernels and end-to-end DL-workloads expressed entirely via TPPs that outperform state-of-the-art implementations on multiple platforms.