 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeML-SpecQD: Multi-Level Speculative Decoding with Quantized Drafts
Mar 17, 2025Speculative decoding (SD) has emerged as a method to accelerate LLM inference without sacrificing any accuracy over the 16-bit model inference. In a typical SD setup, the idea is to use a full-precision, small, fast model as "draft" to generate the next few tokens and use the "target" large model to verify the draft-generated tokens. The efficacy of this method heavily relies on the acceptance ratio of the draft-generated tokens and the relative token throughput of the draft versus the target model. Nevertheless, an efficient SD pipeline requires pre-training and aligning the draft model to the target model, making it impractical for LLM inference in a plug-and-play fashion. In this work, we propose using MXFP4 models as drafts in a plug-and-play fashion since the MXFP4 Weight-Only-Quantization (WOQ) merely direct-casts the BF16 target model weights to MXFP4. In practice, our plug-and-play solution gives speedups up to 2x over the BF16 baseline. Then we pursue an opportunity for further acceleration: the MXFP4 draft token generation itself can be accelerated via speculative decoding by using yet another smaller draft. We call our method ML-SpecQD: Multi-Level Speculative Decoding with Quantized Drafts since it recursively applies speculation for accelerating the draft-token generation. Combining Multi-Level Speculative Decoding with MXFP4 Quantized Drafts we outperform state-of-the-art speculative decoding, yielding speedups up to 2.72x over the BF16 baseline.
DQRM: Deep Quantized Recommendation Models
Oct 26, 2024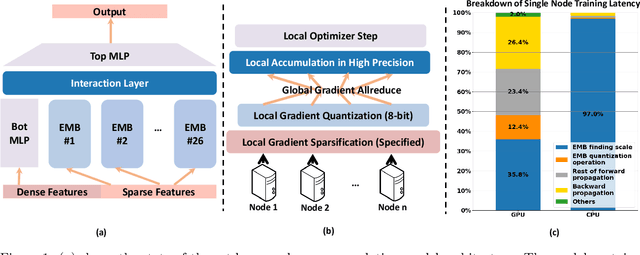
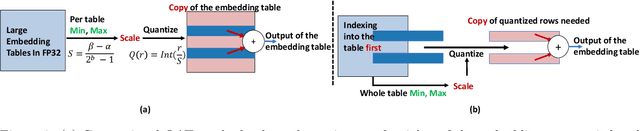

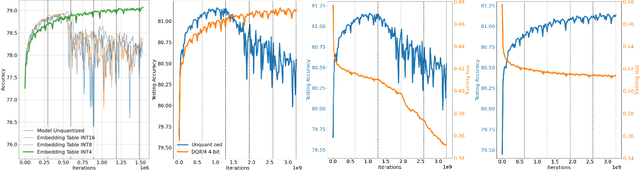
Large-scale recommendation models are currently the dominant workload for many large Internet companies. These recommenders are characterized by massive embedding tables that are sparsely accessed by the index for user and item features. The size of these 1TB+ tables imposes a severe memory bottleneck for the training and inference of recommendation models. In this work, we propose a novel recommendation framework that is small, powerful, and efficient to run and train, based on the state-of-the-art Deep Learning Recommendation Model (DLRM). The proposed framework makes inference more efficient on the cloud servers, explores the possibility of deploying powerful recommenders on smaller edge devices, and optimizes the workload of the communication overhead in distributed training under the data parallelism settings. Specifically, we show that quantization-aware training (QAT) can impose a strong regularization effect to mitigate the severe overfitting issues suffered by DLRMs. Consequently, we achieved INT4 quantization of DLRM models without any accuracy drop. We further propose two techniques that improve and accelerate the conventional QAT workload specifically for the embedding tables in the recommendation models. Furthermore, to achieve efficient training, we quantize the gradients of the embedding tables into INT8 on top of the well-supported specified sparsification. We show that combining gradient sparsification and quantization together significantly reduces the amount of communication. Briefly, DQRM models with INT4 can achieve 79.07% accuracy on Kaggle with 0.27 GB model size, and 81.21% accuracy on the Terabyte dataset with 1.57 GB, which even outperform FP32 DLRMs that have much larger model sizes (2.16 GB on Kaggle and 12.58 on Terabyte).
Harnessing Deep Learning and HPC Kernels via High-Level Loop and Tensor Abstractions on CPU Architectures
Apr 25, 2023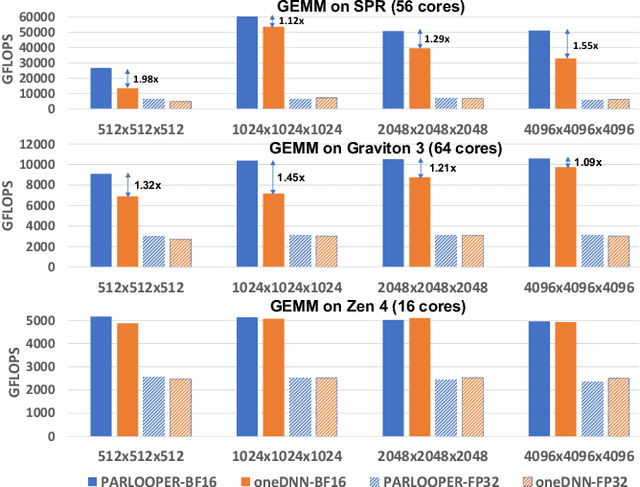
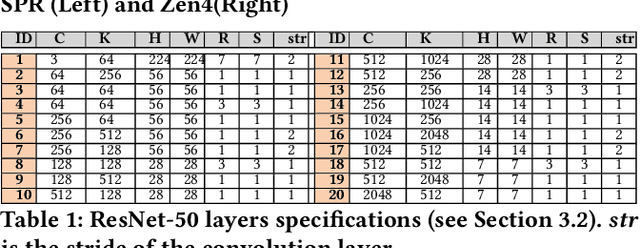
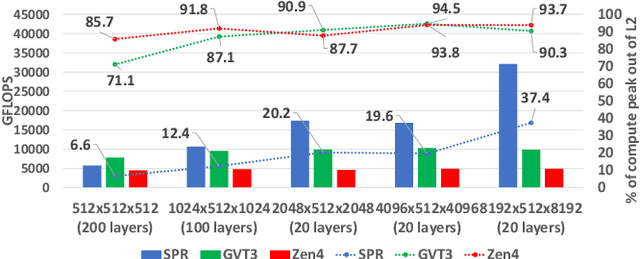
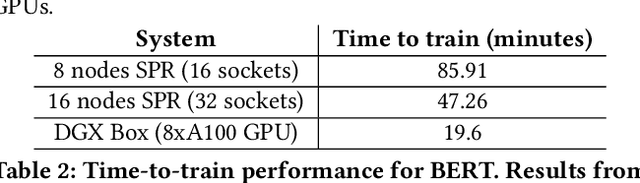
During the past decade, Deep Learning (DL) algorithms, programming systems and hardware have converged with the High Performance Computing (HPC) counterparts. Nevertheless, the programming methodology of DL and HPC systems is stagnant, relying on highly-optimized, yet platform-specific and inflexible vendor-optimized libraries. Such libraries provide close-to-peak performance on specific platforms, kernels and shapes thereof that vendors have dedicated optimizations efforts, while they underperform in the remaining use-cases, yielding non-portable codes with performance glass-jaws. This work introduces a framework to develop efficient, portable DL and HPC kernels for modern CPU architectures. We decompose the kernel development in two steps: 1) Expressing the computational core using Tensor Processing Primitives (TPPs): a compact, versatile set of 2D-tensor operators, 2) Expressing the logical loops around TPPs in a high-level, declarative fashion whereas the exact instantiation (ordering, tiling, parallelization) is determined via simple knobs. We demonstrate the efficacy of our approach using standalone kernels and end-to-end workloads that outperform state-of-the-art implementations on diverse CPU platforms.
DistGNN: Scalable Distributed Training for Large-Scale Graph Neural Networks
Apr 16, 2021
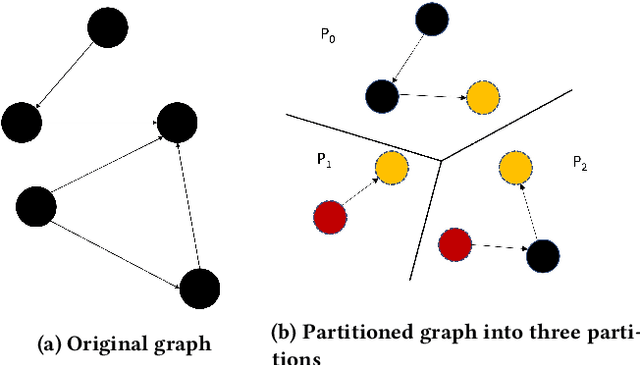
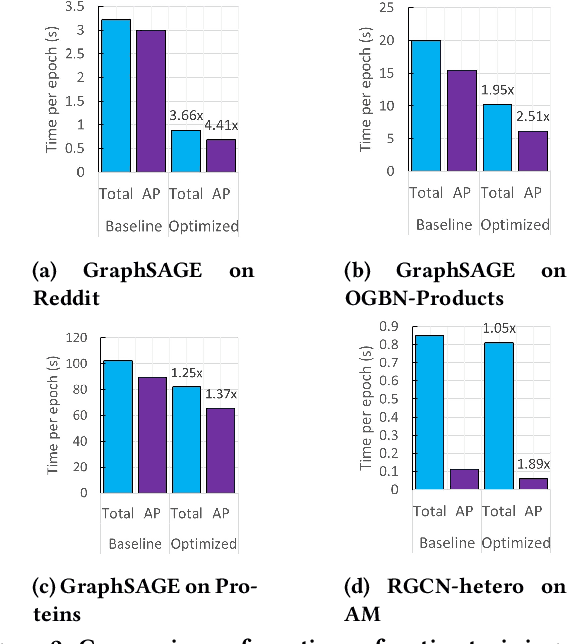
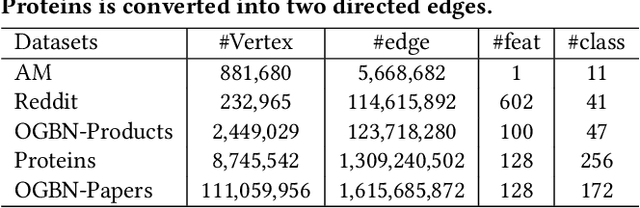
Full-batch training on Graph Neural Networks (GNN) to learn the structure of large graphs is a critical problem that needs to scale to hundreds of compute nodes to be feasible. It is challenging due to large memory capacity and bandwidth requirements on a single compute node and high communication volumes across multiple nodes. In this paper, we present DistGNN that optimizes the well-known Deep Graph Library (DGL) for full-batch training on CPU clusters via an efficient shared memory implementation, communication reduction using a minimum vertex-cut graph partitioning algorithm and communication avoidance using a family of delayed-update algorithms. Our results on four common GNN benchmark datasets: Reddit, OGB-Products, OGB-Papers and Proteins, show up to 3.7x speed-up using a single CPU socket and up to 97x speed-up using 128 CPU sockets, respectively, over baseline DGL implementations running on a single CPU socket
Efficient and Generic 1D Dilated Convolution Layer for Deep Learning
Apr 16, 2021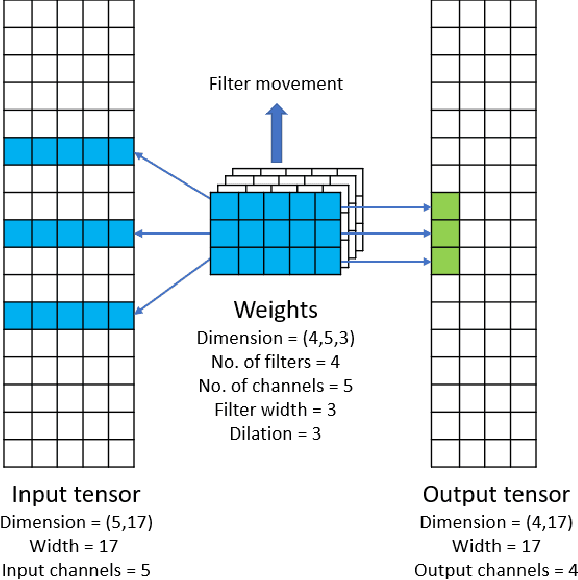
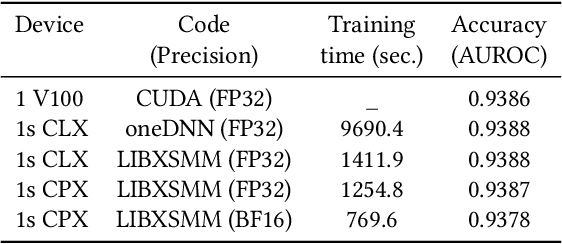
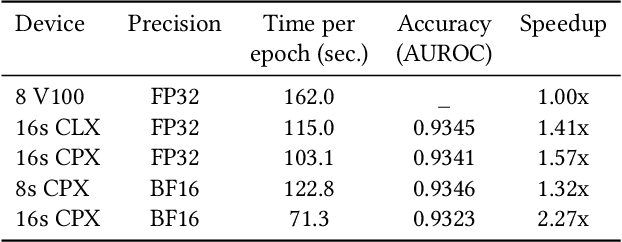
Convolutional neural networks (CNNs) have found many applications in tasks involving two-dimensional (2D) data, such as image classification and image processing. Therefore, 2D convolution layers have been heavily optimized on CPUs and GPUs. However, in many applications - for example genomics and speech recognition, the data can be one-dimensional (1D). Such applications can benefit from optimized 1D convolution layers. In this work, we introduce our efficient implementation of a generic 1D convolution layer covering a wide range of parameters. It is optimized for x86 CPU architectures, in particular, for architectures containing Intel AVX-512 and AVX-512 BFloat16 instructions. We use the LIBXSMM library's batch-reduce General Matrix Multiplication (BRGEMM) kernel for FP32 and BFloat16 precision. We demonstrate that our implementation can achieve up to 80% efficiency on Intel Xeon Cascade Lake and Cooper Lake CPUs. Additionally, we show the generalization capability of our BRGEMM based approach by achieving high efficiency across a range of parameters. We consistently achieve higher efficiency than the 1D convolution layer with Intel oneDNN library backend for varying input tensor widths, filter widths, number of channels, filters, and dilation parameters. Finally, we demonstrate the performance of our optimized 1D convolution layer by utilizing it in the end-to-end neural network training with real genomics datasets and achieve up to 6.86x speedup over the oneDNN library-based implementation on Cascade Lake CPUs. We also demonstrate the scaling with 16 sockets of Cascade/Cooper Lake CPUs and achieve significant speedup over eight V100 GPUs using a similar power envelop. In the end-to-end training, we get a speedup of 1.41x on Cascade Lake with FP32, 1.57x on Cooper Lake with FP32, and 2.27x on Cooper Lake with BFloat16 over eight V100 GPUs with FP32.
Tensor Processing Primitives: A Programming Abstraction for Efficiency and Portability in Deep Learning Workloads
Apr 14, 2021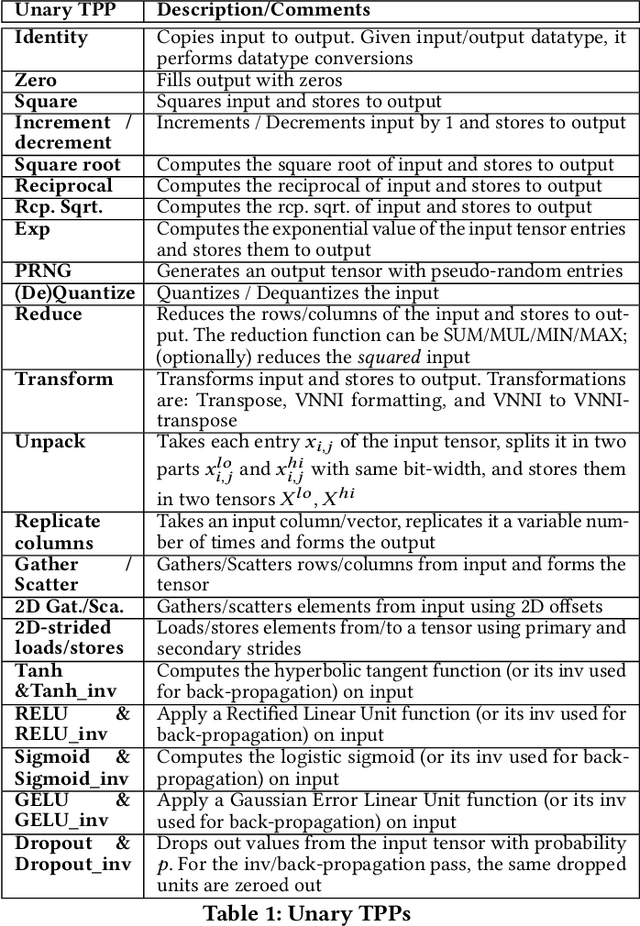
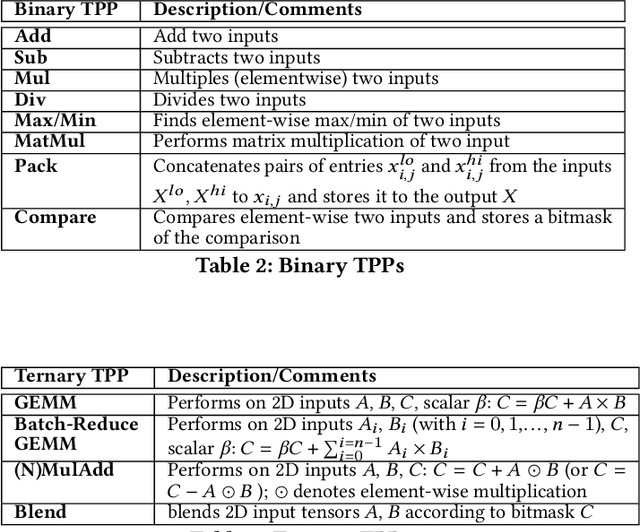
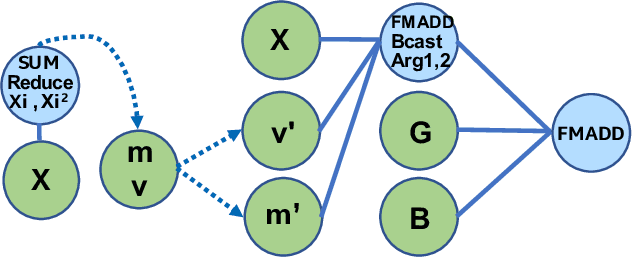
During the past decade, novel Deep Learning (DL) algorithms/workloads and hardware have been developed to tackle a wide range of problems. Despite the advances in workload/hardware ecosystems, the programming methodology of DL-systems is stagnant. DL-workloads leverage either highly-optimized, yet platform-specific and inflexible kernels from DL-libraries, or in the case of novel operators, reference implementations are built via DL-framework primitives with underwhelming performance. This work introduces the Tensor Processing Primitives (TPP), a programming abstraction striving for efficient, portable implementation of DL-workloads with high-productivity. TPPs define a compact, yet versatile set of 2D-tensor operators (or a virtual Tensor ISA), which subsequently can be utilized as building-blocks to construct complex operators on high-dimensional tensors. The TPP specification is platform-agnostic, thus code expressed via TPPs is portable, whereas the TPP implementation is highly-optimized and platform-specific. We demonstrate the efficacy of our approach using standalone kernels and end-to-end DL-workloads expressed entirely via TPPs that outperform state-of-the-art implementations on multiple platforms.
Optimizing Deep Learning Recommender Systems' Training On CPU Cluster Architectures
May 10, 2020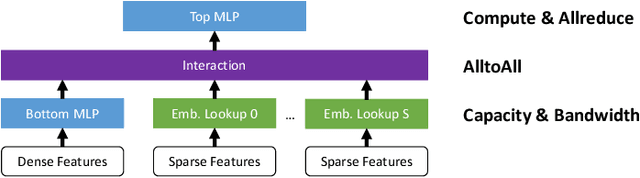
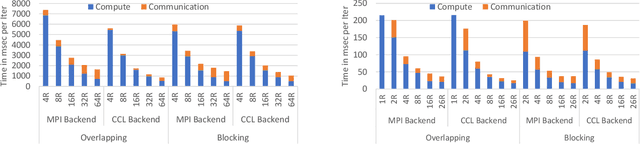
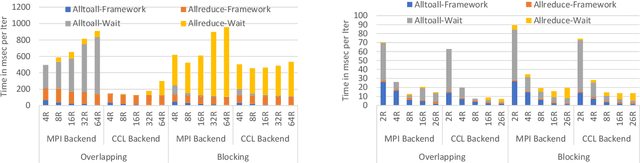

During the last two years, the goal of many researchers has been to squeeze the last bit of performance out of HPC system for AI tasks. Often this discussion is held in the context of how fast ResNet50 can be trained. Unfortunately, ResNet50 is no longer a representative workload in 2020. Thus, we focus on Recommender Systems which account for most of the AI cycles in cloud computing centers. More specifically, we focus on Facebook's DLRM benchmark. By enabling it to run on latest CPU hardware and software tailored for HPC, we are able to achieve more than two-orders of magnitude improvement in performance (110x) on a single socket compared to the reference CPU implementation, and high scaling efficiency up to 64 sockets, while fitting ultra-large datasets. This paper discusses the optimization techniques for the various operators in DLRM and which component of the systems are stressed by these different operators. The presented techniques are applicable to a broader set of DL workloads that pose the same scaling challenges/characteristics as DLRM.
K-TanH: Hardware Efficient Activations For Deep Learning
Oct 21, 2019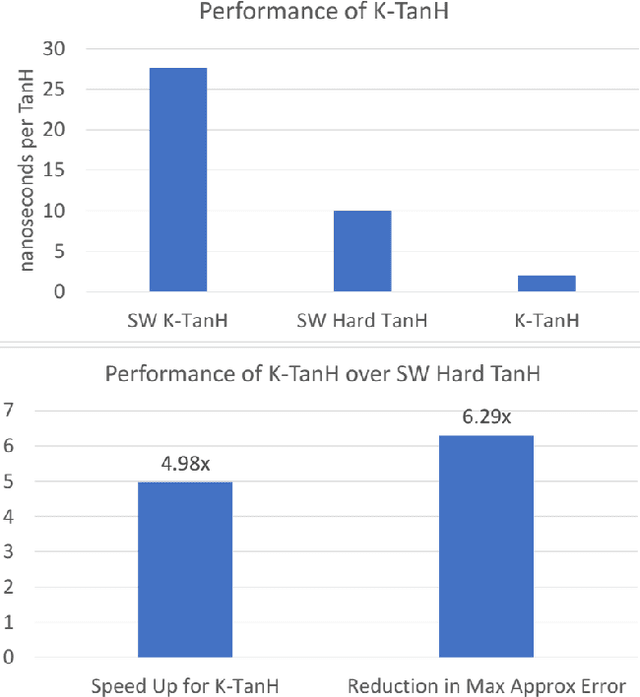
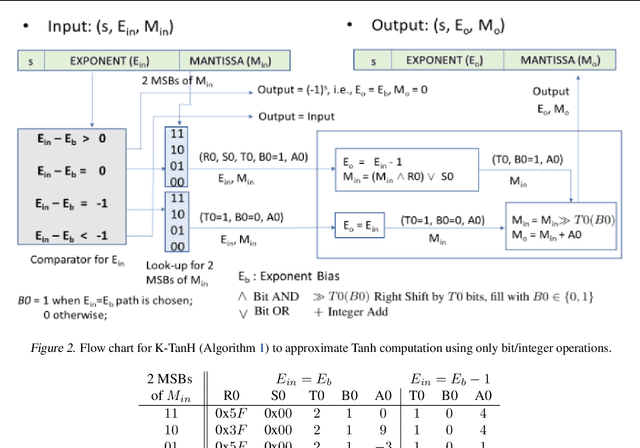

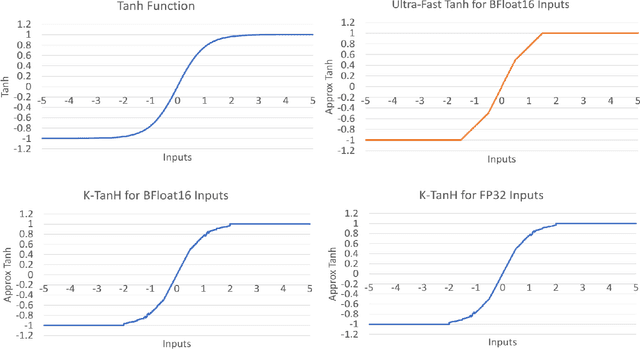
We propose K-TanH, a novel, highly accurate, hardware efficient approximation of popular activation function Tanh for Deep Learning. K-TanH consists of a sequence of parameterized bit/integer operations, such as, masking, shift and add/subtract (no floating point operation needed) where parameters are stored in a very small look-up table (bit-masking step can be eliminated). The design of K-TanH is flexible enough to deal with multiple numerical formats, such as, FP32 and BFloat16. High quality approximations to other activation functions, e.g., Swish and GELU, can be derived from K-TanH. We provide RTL design for K-TanH to demonstrate its area/power/performance efficacy. It is more accurate than existing piecewise approximations for Tanh. For example, K-TanH achieves $\sim 5\times$ speed up and $> 6\times$ reduction in maximum approximation error over software implementation of Hard TanH. Experimental results for low-precision BFloat16 training of language translation model GNMT on WMT16 data sets with approximate Tanh and Sigmoid obtained via K-TanH achieve similar accuracy and convergence as training with exact Tanh and Sigmoid.
High-Performance Deep Learning via a Single Building Block
Jun 18, 2019


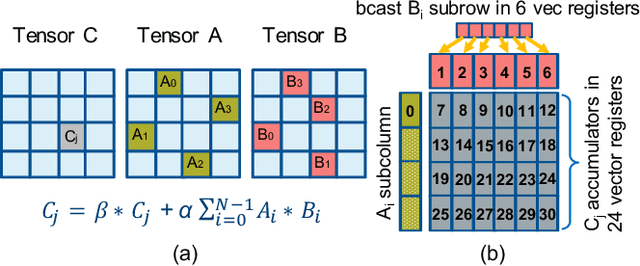
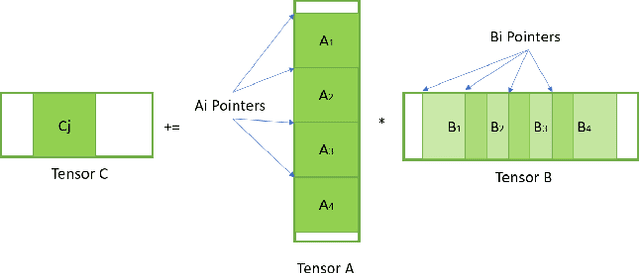
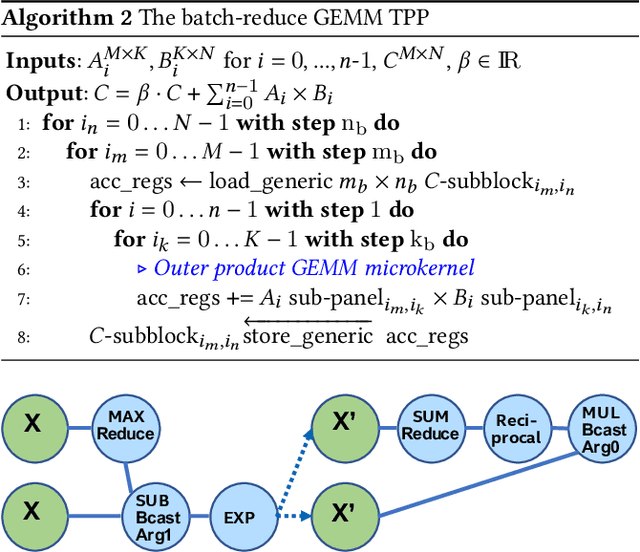
Deep learning (DL) is one of the most prominent branches of machine learning. Due to the immense computational cost of DL workloads, industry and academia have developed DL libraries with highly-specialized kernels for each workload/architecture, leading to numerous, complex code-bases that strive for performance, yet they are hard to maintain and do not generalize. In this work, we introduce the batch-reduce GEMM kernel and show how the most popular DL algorithms can be formulated with this kernel as the basic building-block. Consequently, the DL library-development degenerates to mere (potentially automatic) tuning of loops around this sole optimized kernel. By exploiting our new kernel we implement Recurrent Neural Networks, Convolution Neural Networks and Multilayer Perceptron training and inference primitives in just 3K lines of high-level code. Our primitives outperform vendor-optimized libraries on multi-node CPU clusters, and we also provide proof-of-concept CNN kernels targeting GPUs. Finally, we demonstrate that the batch-reduce GEMM kernel within a tensor compiler yields high-performance CNN primitives, further amplifying the viability of our approach.
A Study of BFLOAT16 for Deep Learning Training
Jun 13, 2019

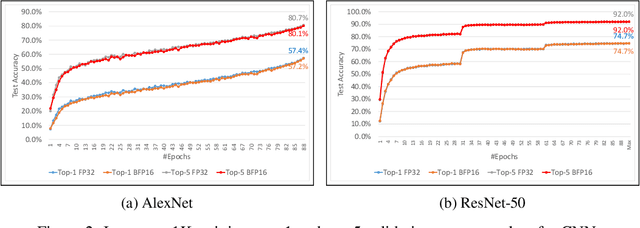

This paper presents the first comprehensive empirical study demonstrating the efficacy of the Brain Floating Point (BFLOAT16) half-precision format for Deep Learning training across image classification, speech recognition, language modeling, generative networks and industrial recommendation systems. BFLOAT16 is attractive for Deep Learning training for two reasons: the range of values it can represent is the same as that of IEEE 754 floating-point format (FP32) and conversion to/from FP32 is simple. Maintaining the same range as FP32 is important to ensure that no hyper-parameter tuning is required for convergence; e.g., IEEE 754 compliant half-precision floating point (FP16) requires hyper-parameter tuning. In this paper, we discuss the flow of tensors and various key operations in mixed precision training, and delve into details of operations, such as the rounding modes for converting FP32 tensors to BFLOAT16. We have implemented a method to emulate BFLOAT16 operations in Tensorflow, Caffe2, IntelCaffe, and Neon for our experiments. Our results show that deep learning training using BFLOAT16 tensors achieves the same state-of-the-art (SOTA) results across domains as FP32 tensors in the same number of iterations and with no changes to hyper-parameters.