 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDQRM: Deep Quantized Recommendation Models
Oct 26, 2024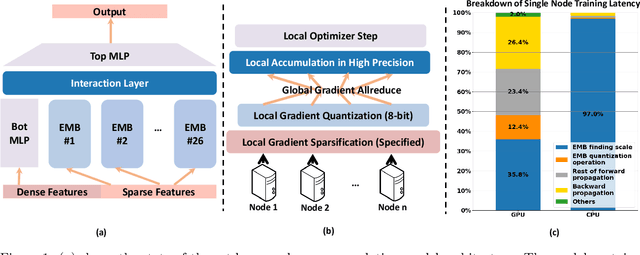
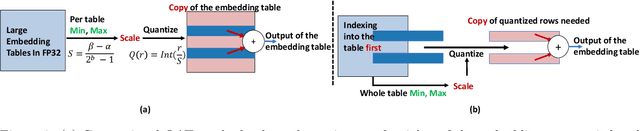

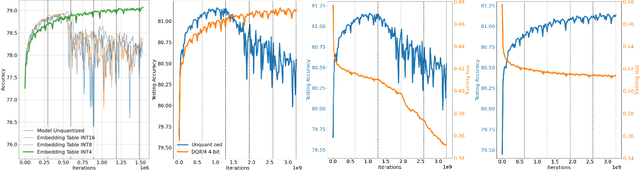
Large-scale recommendation models are currently the dominant workload for many large Internet companies. These recommenders are characterized by massive embedding tables that are sparsely accessed by the index for user and item features. The size of these 1TB+ tables imposes a severe memory bottleneck for the training and inference of recommendation models. In this work, we propose a novel recommendation framework that is small, powerful, and efficient to run and train, based on the state-of-the-art Deep Learning Recommendation Model (DLRM). The proposed framework makes inference more efficient on the cloud servers, explores the possibility of deploying powerful recommenders on smaller edge devices, and optimizes the workload of the communication overhead in distributed training under the data parallelism settings. Specifically, we show that quantization-aware training (QAT) can impose a strong regularization effect to mitigate the severe overfitting issues suffered by DLRMs. Consequently, we achieved INT4 quantization of DLRM models without any accuracy drop. We further propose two techniques that improve and accelerate the conventional QAT workload specifically for the embedding tables in the recommendation models. Furthermore, to achieve efficient training, we quantize the gradients of the embedding tables into INT8 on top of the well-supported specified sparsification. We show that combining gradient sparsification and quantization together significantly reduces the amount of communication. Briefly, DQRM models with INT4 can achieve 79.07% accuracy on Kaggle with 0.27 GB model size, and 81.21% accuracy on the Terabyte dataset with 1.57 GB, which even outperform FP32 DLRMs that have much larger model sizes (2.16 GB on Kaggle and 12.58 on Terabyte).
Does Form Follow Function? An Empirical Exploration of the Impact of Deep Neural Network Architecture Design on Hardware-Specific Acceleration
Jul 08, 2021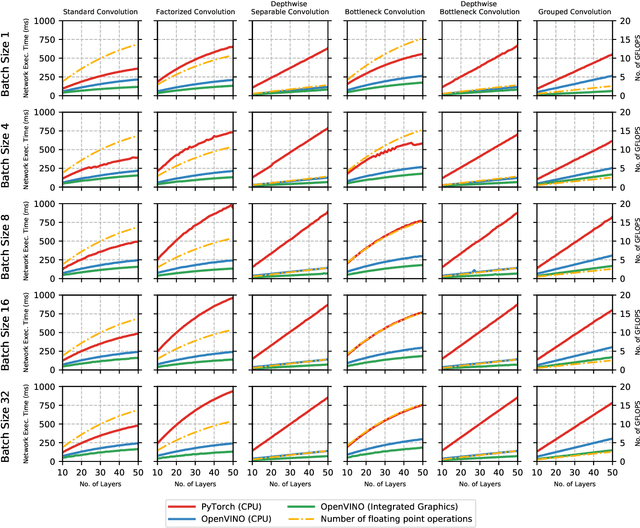
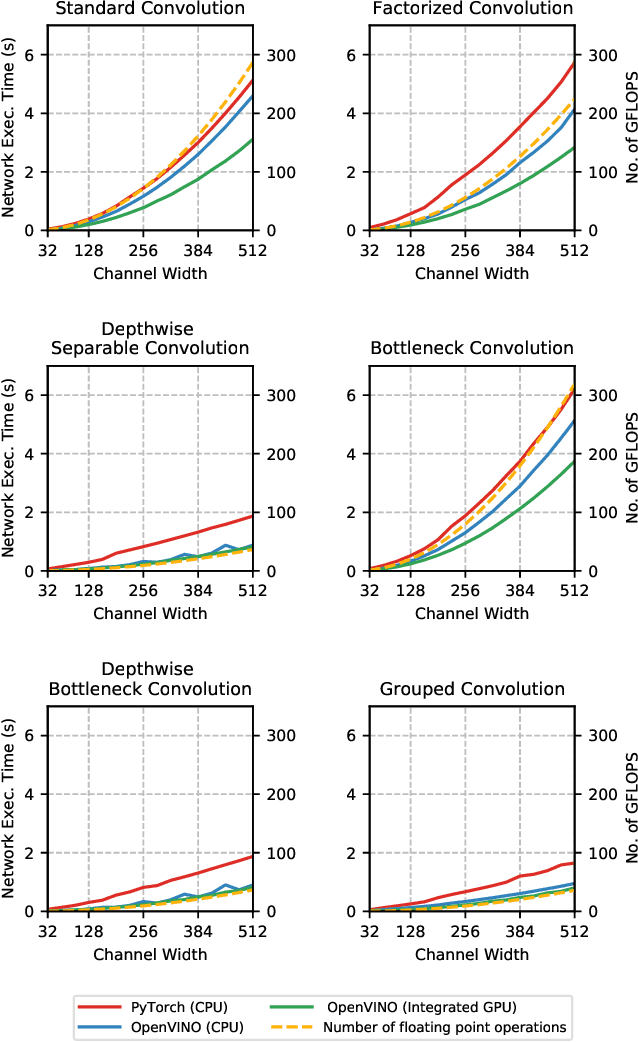
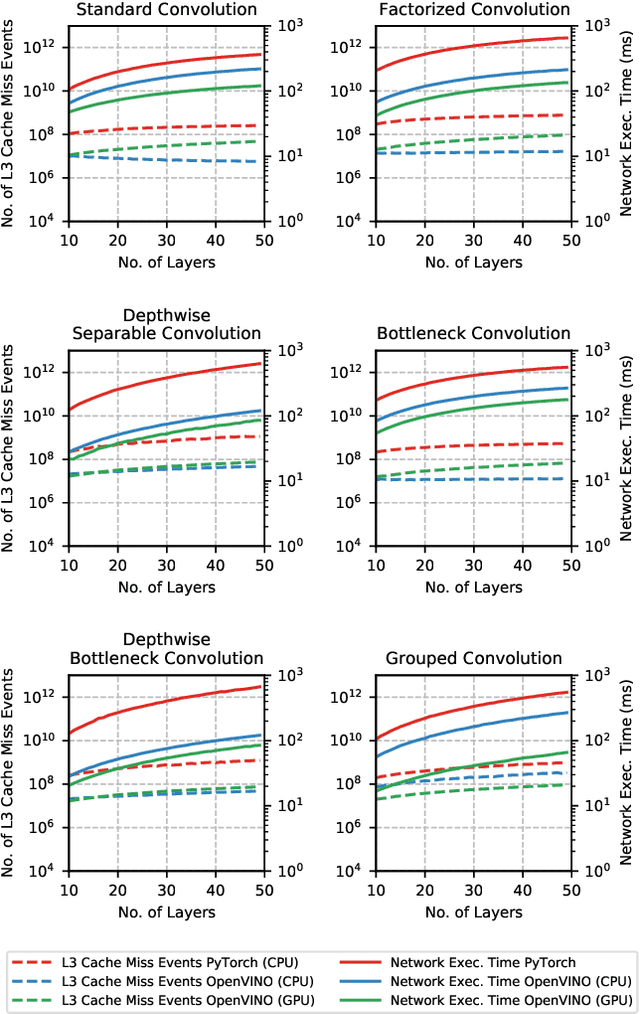
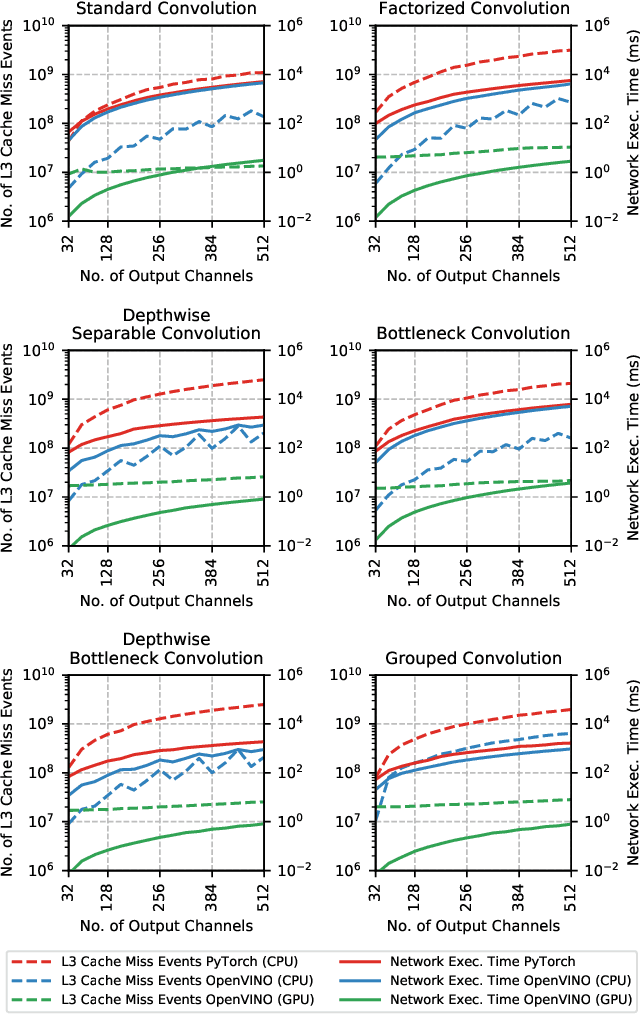
The fine-grained relationship between form and function with respect to deep neural network architecture design and hardware-specific acceleration is one area that is not well studied in the research literature, with form often dictated by accuracy as opposed to hardware function. In this study, a comprehensive empirical exploration is conducted to investigate the impact of deep neural network architecture design on the degree of inference speedup that can be achieved via hardware-specific acceleration. More specifically, we empirically study the impact of a variety of commonly used macro-architecture design patterns across different architectural depths through the lens of OpenVINO microprocessor-specific and GPU-specific acceleration. Experimental results showed that while leveraging hardware-specific acceleration achieved an average inference speed-up of 380%, the degree of inference speed-up varied drastically depending on the macro-architecture design pattern, with the greatest speedup achieved on the depthwise bottleneck convolution design pattern at 550%. Furthermore, we conduct an in-depth exploration of the correlation between FLOPs requirement, level 3 cache efficacy, and network latency with increasing architectural depth and width. Finally, we analyze the inference time reductions using hardware-specific acceleration when compared to native deep learning frameworks across a wide variety of hand-crafted deep convolutional neural network architecture designs as well as ones found via neural architecture search strategies. We found that the DARTS-derived architecture to benefit from the greatest improvement from hardware-specific software acceleration (1200%) while the depthwise bottleneck convolution-based MobileNet-V2 to have the lowest overall inference time of around 2.4 ms.
Machine: The New Art Connoisseur
Dec 03, 2019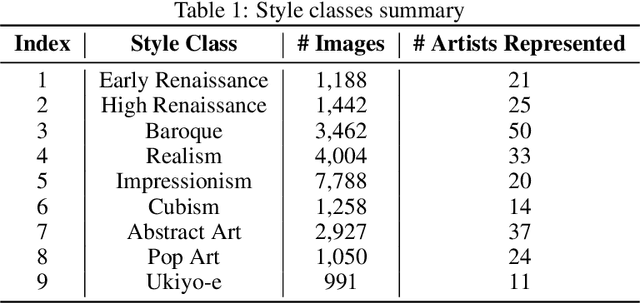
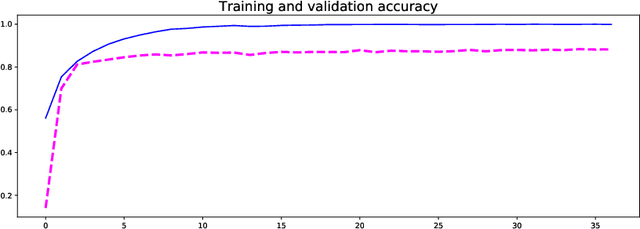

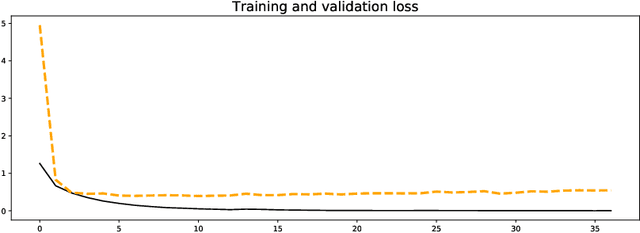
The process of identifying and understanding art styles to discover artistic influences is essential to the study of art history. Traditionally, trained experts review fine details of the works and compare them to other known works. To automate and scale this task, we use several state-of-the-art CNN architectures to explore how a machine may help perceive and quantify art styles. This study explores: (1) How accurately can a machine classify art styles? (2) What may be the underlying relationships among different styles and artists? To help answer the first question, our best-performing model using Inception V3 achieves a 9-class classification accuracy of 88.35%, which outperforms the model in Elgammal et al.'s study by more than 20 percent. Visualizations using Grad-CAM heat maps confirm that the model correctly focuses on the characteristic parts of paintings. To help address the second question, we conduct network analysis on the influences among styles and artists by extracting 512 features from the best-performing classification model. Through 2D and 3D T-SNE visualizations, we observe clear chronological patterns of development and separation among the art styles. The network analysis also appears to show anticipated artist level connections from an art historical perspective. This technique appears to help identify some previously unknown linkages that may shed light upon new directions for further exploration by art historians. We hope that humans and machines working in concert may bring new opportunities to the field.