 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTurboViT: Generating Fast Vision Transformers via Generative Architecture Search
Aug 22, 2023


Vision transformers have shown unprecedented levels of performance in tackling various visual perception tasks in recent years. However, the architectural and computational complexity of such network architectures have made them challenging to deploy in real-world applications with high-throughput, low-memory requirements. As such, there has been significant research recently on the design of efficient vision transformer architectures. In this study, we explore the generation of fast vision transformer architecture designs via generative architecture search (GAS) to achieve a strong balance between accuracy and architectural and computational efficiency. Through this generative architecture search process, we create TurboViT, a highly efficient hierarchical vision transformer architecture design that is generated around mask unit attention and Q-pooling design patterns. The resulting TurboViT architecture design achieves significantly lower architectural computational complexity (>2.47$\times$ smaller than FasterViT-0 while achieving same accuracy) and computational complexity (>3.4$\times$ fewer FLOPs and 0.9% higher accuracy than MobileViT2-2.0) when compared to 10 other state-of-the-art efficient vision transformer network architecture designs within a similar range of accuracy on the ImageNet-1K dataset. Furthermore, TurboViT demonstrated strong inference latency and throughput in both low-latency and batch processing scenarios (>3.21$\times$ lower latency and >3.18$\times$ higher throughput compared to FasterViT-0 for low-latency scenario). These promising results demonstrate the efficacy of leveraging generative architecture search for generating efficient transformer architecture designs for high-throughput scenarios.
Fast GraspNeXt: A Fast Self-Attention Neural Network Architecture for Multi-task Learning in Computer Vision Tasks for Robotic Grasping on the Edge
Apr 21, 2023Multi-task learning has shown considerable promise for improving the performance of deep learning-driven vision systems for the purpose of robotic grasping. However, high architectural and computational complexity can result in poor suitability for deployment on embedded devices that are typically leveraged in robotic arms for real-world manufacturing and warehouse environments. As such, the design of highly efficient multi-task deep neural network architectures tailored for computer vision tasks for robotic grasping on the edge is highly desired for widespread adoption in manufacturing environments. Motivated by this, we propose Fast GraspNeXt, a fast self-attention neural network architecture tailored for embedded multi-task learning in computer vision tasks for robotic grasping. To build Fast GraspNeXt, we leverage a generative network architecture search strategy with a set of architectural constraints customized to achieve a strong balance between multi-task learning performance and embedded inference efficiency. Experimental results on the MetaGraspNet benchmark dataset show that the Fast GraspNeXt network design achieves the highest performance (average precision (AP), accuracy, and mean squared error (MSE)) across multiple computer vision tasks when compared to other efficient multi-task network architecture designs, while having only 17.8M parameters (about >5x smaller), 259 GFLOPs (as much as >5x lower) and as much as >3.15x faster on a NVIDIA Jetson TX2 embedded processor.
PCBDet: An Efficient Deep Neural Network Object Detection Architecture for Automatic PCB Component Detection on the Edge
Jan 23, 2023There can be numerous electronic components on a given PCB, making the task of visual inspection to detect defects very time-consuming and prone to error, especially at scale. There has thus been significant interest in automatic PCB component detection, particularly leveraging deep learning. However, deep neural networks typically require high computational resources, possibly limiting their feasibility in real-world use cases in manufacturing, which often involve high-volume and high-throughput detection with constrained edge computing resource availability. As a result of an exploration of efficient deep neural network architectures for this use case, we introduce PCBDet, an attention condenser network design that provides state-of-the-art inference throughput while achieving superior PCB component detection performance compared to other state-of-the-art efficient architecture designs. Experimental results show that PCBDet can achieve up to 2$\times$ inference speed-up on an ARM Cortex A72 processor when compared to an EfficientNet-based design while achieving $\sim$2-4\% higher mAP on the FICS-PCB benchmark dataset.
COVID-Net Assistant: A Deep Learning-Driven Virtual Assistant for COVID-19 Symptom Prediction and Recommendation
Nov 22, 2022



As the COVID-19 pandemic continues to put a significant burden on healthcare systems worldwide, there has been growing interest in finding inexpensive symptom pre-screening and recommendation methods to assist in efficiently using available medical resources such as PCR tests. In this study, we introduce the design of COVID-Net Assistant, an efficient virtual assistant designed to provide symptom prediction and recommendations for COVID-19 by analyzing users' cough recordings through deep convolutional neural networks. We explore a variety of highly customized, lightweight convolutional neural network architectures generated via machine-driven design exploration (which we refer to as COVID-Net Assistant neural networks) on the Covid19-Cough benchmark dataset. The Covid19-Cough dataset comprises 682 cough recordings from a COVID-19 positive cohort and 642 from a COVID-19 negative cohort. Among the 682 cough recordings labeled positive, 382 recordings were verified by PCR test. Our experimental results show promising, with the COVID-Net Assistant neural networks demonstrating robust predictive performance, achieving AUC scores of over 0.93, with the best score over 0.95 while being fast and efficient in inference. The COVID-Net Assistant models are made available in an open source manner through the COVID-Net open initiative and, while not a production-ready solution, we hope their availability acts as a good resource for clinical scientists, machine learning researchers, as well as citizen scientists to develop innovative solutions.
Faster Attention Is What You Need: A Fast Self-Attention Neural Network Backbone Architecture for the Edge via Double-Condensing Attention Condensers
Aug 22, 2022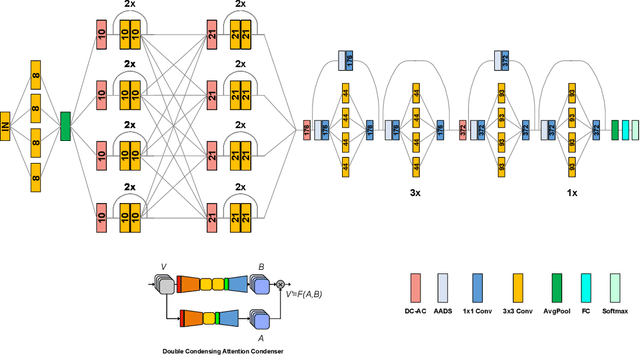
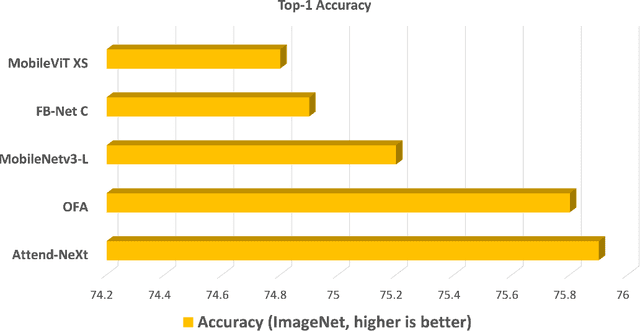
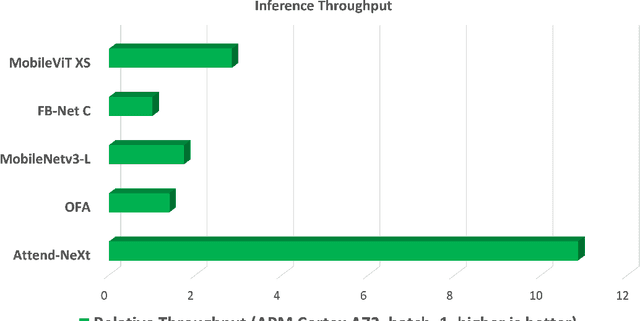
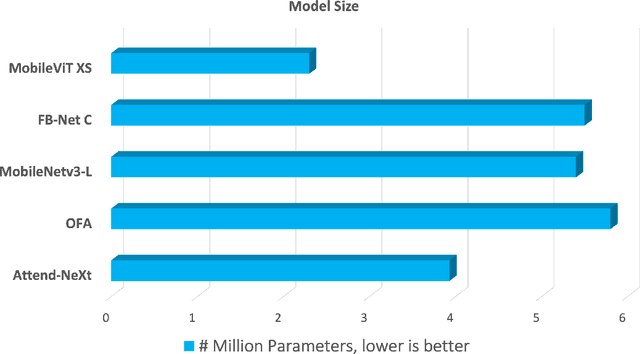
With the growing adoption of deep learning for on-device TinyML applications, there has been an ever-increasing demand for more efficient neural network backbones optimized for the edge. Recently, the introduction of attention condenser networks have resulted in low-footprint, highly-efficient, self-attention neural networks that strike a strong balance between accuracy and speed. In this study, we introduce a new faster attention condenser design called double-condensing attention condensers that enable more condensed feature embedding. We further employ a machine-driven design exploration strategy that imposes best practices design constraints for greater efficiency and robustness to produce the macro-micro architecture constructs of the backbone. The resulting backbone (which we name AttendNeXt) achieves significantly higher inference throughput on an embedded ARM processor when compared to several other state-of-the-art efficient backbones (>10X faster than FB-Net C at higher accuracy and speed and >10X faster than MobileOne-S1 at smaller size) while having a small model size (>1.37X smaller than MobileNetv3-L at higher accuracy and speed) and strong accuracy (1.1% higher top-1 accuracy than MobileViT XS on ImageNet at higher speed). These promising results demonstrate that exploring different efficient architecture designs and self-attention mechanisms can lead to interesting new building blocks for TinyML applications.
MAPLE-X: Latency Prediction with Explicit Microprocessor Prior Knowledge
May 25, 2022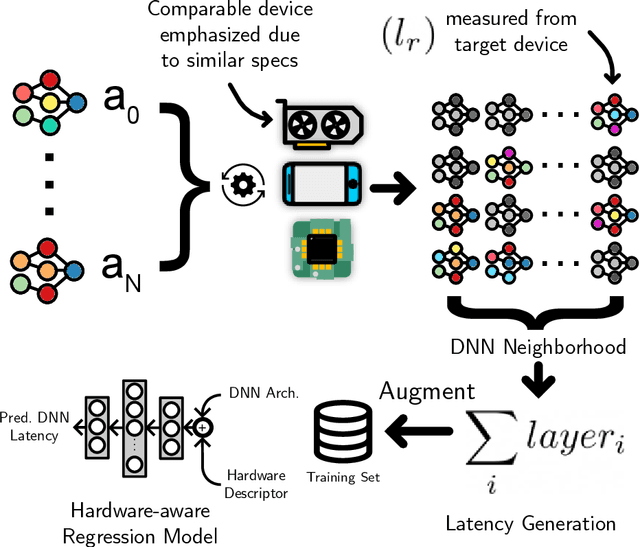
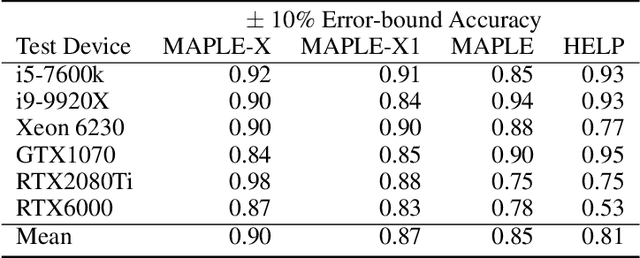
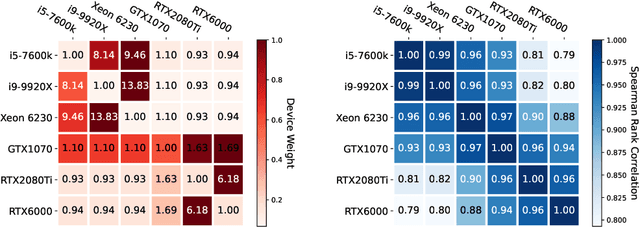
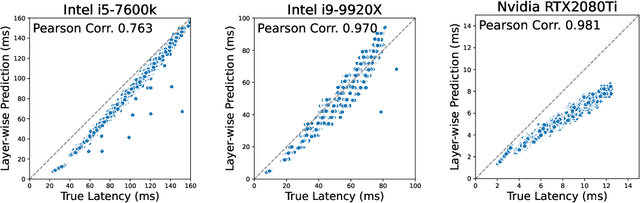
Deep neural network (DNN) latency characterization is a time-consuming process and adds significant cost to Neural Architecture Search (NAS) processes when searching for efficient convolutional neural networks for embedded vision applications. DNN Latency is a hardware dependent metric and requires direct measurement or inference on target hardware. A recently introduced latency estimation technique known as MAPLE predicts DNN execution time on previously unseen hardware devices by using hardware performance counters. Leveraging these hardware counters in the form of an implicit prior, MAPLE achieves state-of-the-art performance in latency prediction. Here, we propose MAPLE-X which extends MAPLE by incorporating explicit prior knowledge of hardware devices and DNN architecture latency to better account for model stability and robustness. First, by identifying DNN architectures that exhibit a similar latency to each other, we can generate multiple virtual examples to significantly improve the accuracy over MAPLE. Secondly, the hardware specifications are used to determine the similarity between training and test hardware to emphasize training samples captured from comparable devices (domains) and encourages improved domain alignment. Experimental results using a convolution neural network NAS benchmark across different types of devices, including an Intel processor that is now used for embedded vision applications, demonstrate a 5% improvement over MAPLE and 9% over HELP. Furthermore, we include ablation studies to independently assess the benefits of virtual examples and hardware-based sample importance.
MAPLE-Edge: A Runtime Latency Predictor for Edge Devices
Apr 27, 2022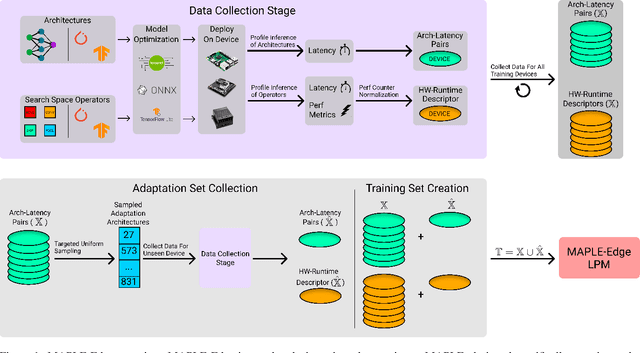
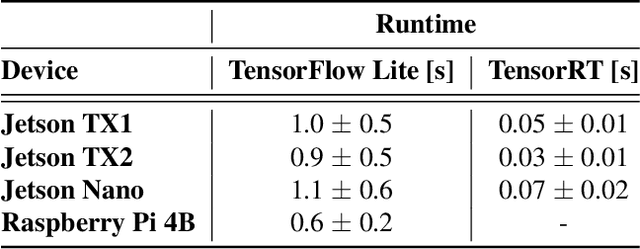
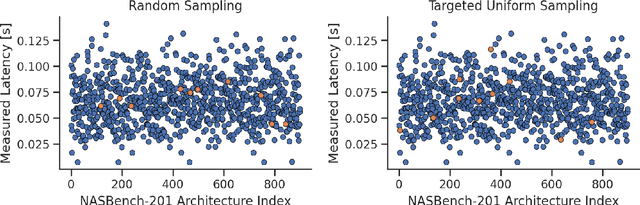
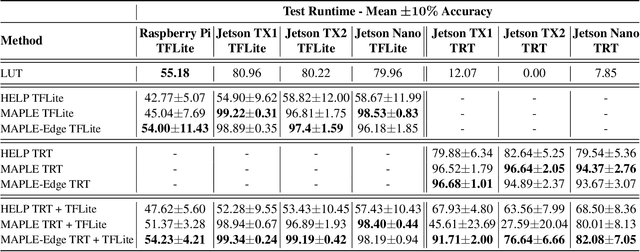
Neural Architecture Search (NAS) has enabled automatic discovery of more efficient neural network architectures, especially for mobile and embedded vision applications. Although recent research has proposed ways of quickly estimating latency on unseen hardware devices with just a few samples, little focus has been given to the challenges of estimating latency on runtimes using optimized graphs, such as TensorRT and specifically for edge devices. In this work, we propose MAPLE-Edge, an edge device-oriented extension of MAPLE, the state-of-the-art latency predictor for general purpose hardware, where we train a regression network on architecture-latency pairs in conjunction with a hardware-runtime descriptor to effectively estimate latency on a diverse pool of edge devices. Compared to MAPLE, MAPLE-Edge can describe the runtime and target device platform using a much smaller set of CPU performance counters that are widely available on all Linux kernels, while still achieving up to +49.6% accuracy gains against previous state-of-the-art baseline methods on optimized edge device runtimes, using just 10 measurements from an unseen target device. We also demonstrate that unlike MAPLE which performs best when trained on a pool of devices sharing a common runtime, MAPLE-Edge can effectively generalize across runtimes by applying a trick of normalizing performance counters by the operator latency, in the measured hardware-runtime descriptor. Lastly, we show that for runtimes exhibiting lower than desired accuracy, performance can be boosted by collecting additional samples from the target device, with an extra 90 samples translating to gains of nearly +40%.
MAPLE: Microprocessor A Priori for Latency Estimation
Nov 30, 2021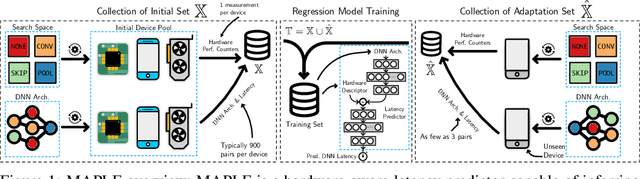

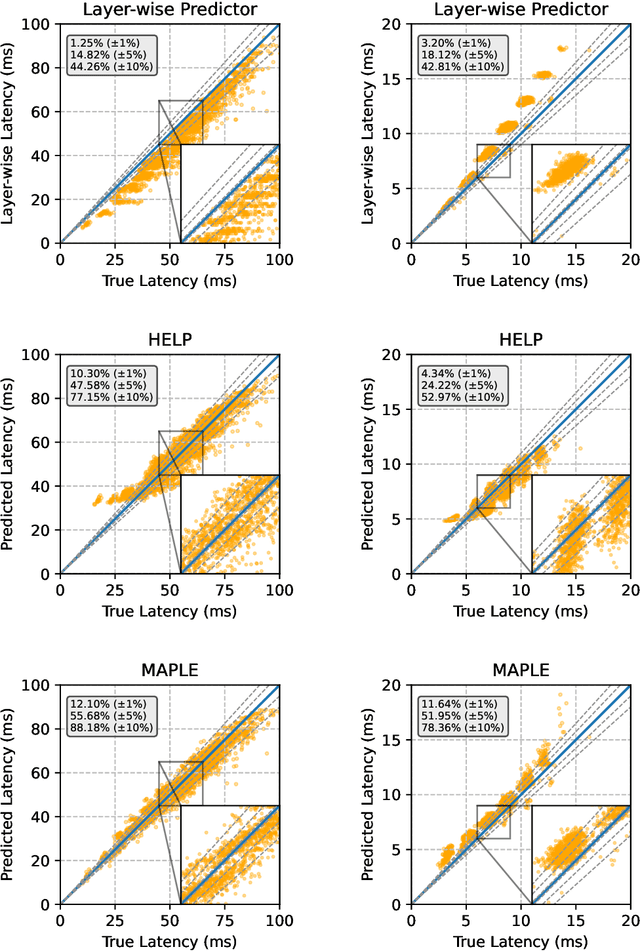
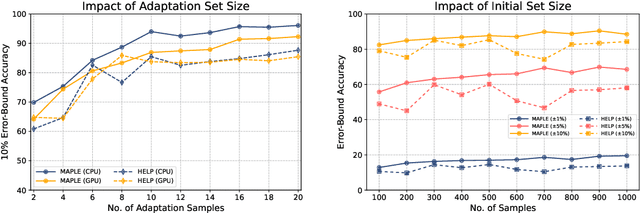
Modern deep neural networks must demonstrate state-of-the-art accuracy while exhibiting low latency and energy consumption. As such, neural architecture search (NAS) algorithms take these two constraints into account when generating a new architecture. However, efficiency metrics such as latency are typically hardware dependent requiring the NAS algorithm to either measure or predict the architecture latency. Measuring the latency of every evaluated architecture adds a significant amount of time to the NAS process. Here we propose Microprocessor A Priori for Latency Estimation MAPLE that does not rely on transfer learning or domain adaptation but instead generalizes to new hardware by incorporating a prior hardware characteristics during training. MAPLE takes advantage of a novel quantitative strategy to characterize the underlying microprocessor by measuring relevant hardware performance metrics, yielding a fine-grained and expressive hardware descriptor. Moreover, the proposed MAPLE benefits from the tightly coupled I/O between the CPU and GPU and their dependency to predict DNN latency on GPUs while measuring microprocessor performance hardware counters from the CPU feeding the GPU hardware. Through this quantitative strategy as the hardware descriptor, MAPLE can generalize to new hardware via a few shot adaptation strategy where with as few as 3 samples it exhibits a 3% improvement over state-of-the-art methods requiring as much as 10 samples. Experimental results showed that, increasing the few shot adaptation samples to 10 improves the accuracy significantly over the state-of-the-art methods by 12%. Furthermore, it was demonstrated that MAPLE exhibiting 8-10% better accuracy, on average, compared to relevant baselines at any number of adaptation samples.
COVID-Net MLSys: Designing COVID-Net for the Clinical Workflow
Sep 14, 2021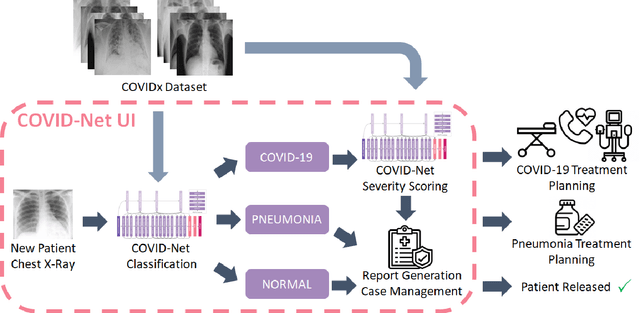
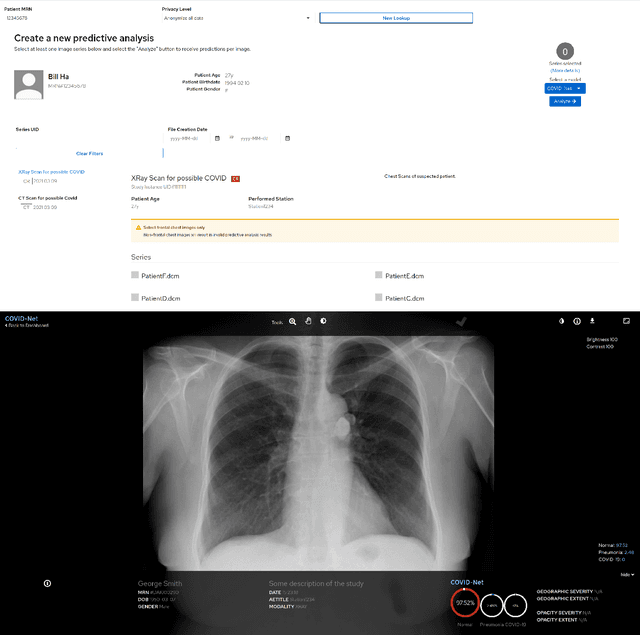
As the COVID-19 pandemic continues to devastate globally, one promising field of research is machine learning-driven computer vision to streamline various parts of the COVID-19 clinical workflow. These machine learning methods are typically stand-alone models designed without consideration for the integration necessary for real-world application workflows. In this study, we take a machine learning and systems (MLSys) perspective to design a system for COVID-19 patient screening with the clinical workflow in mind. The COVID-Net system is comprised of the continuously evolving COVIDx dataset, COVID-Net deep neural network for COVID-19 patient detection, and COVID-Net S deep neural networks for disease severity scoring for COVID-19 positive patient cases. The deep neural networks within the COVID-Net system possess state-of-the-art performance, and are designed to be integrated within a user interface (UI) for clinical decision support with automatic report generation to assist clinicians in their treatment decisions.
COVID-Net US: A Tailored, Highly Efficient, Self-Attention Deep Convolutional Neural Network Design for Detection of COVID-19 Patient Cases from Point-of-care Ultrasound Imaging
Aug 05, 2021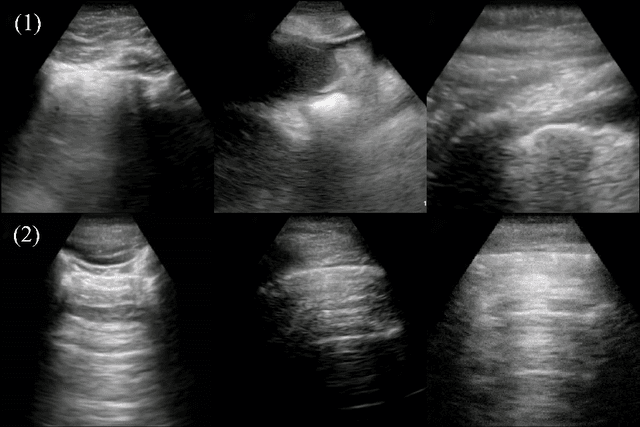


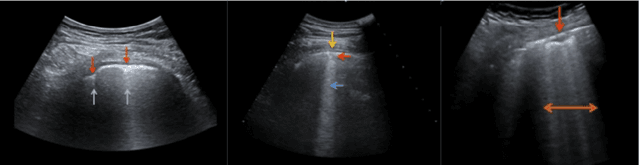
The Coronavirus Disease 2019 (COVID-19) pandemic has impacted many aspects of life globally, and a critical factor in mitigating its effects is screening individuals for infections, thereby allowing for both proper treatment for those individuals as well as action to be taken to prevent further spread of the virus. Point-of-care ultrasound (POCUS) imaging has been proposed as a screening tool as it is a much cheaper and easier to apply imaging modality than others that are traditionally used for pulmonary examinations, namely chest x-ray and computed tomography. Given the scarcity of expert radiologists for interpreting POCUS examinations in many highly affected regions around the world, low-cost deep learning-driven clinical decision support solutions can have a large impact during the on-going pandemic. Motivated by this, we introduce COVID-Net US, a highly efficient, self-attention deep convolutional neural network design tailored for COVID-19 screening from lung POCUS images. Experimental results show that the proposed COVID-Net US can achieve an AUC of over 0.98 while achieving 353X lower architectural complexity, 62X lower computational complexity, and 14.3X faster inference times on a Raspberry Pi. Clinical validation was also conducted, where select cases were reviewed and reported on by a practicing clinician (20 years of clinical practice) specializing in intensive care (ICU) and 15 years of expertise in POCUS interpretation. To advocate affordable healthcare and artificial intelligence for resource-constrained environments, we have made COVID-Net US open source and publicly available as part of the COVID-Net open source initiative.