 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDARLEI: Deep Accelerated Reinforcement Learning with Evolutionary Intelligence
Dec 08, 2023We present DARLEI, a framework that combines evolutionary algorithms with parallelized reinforcement learning for efficiently training and evolving populations of UNIMAL agents. Our approach utilizes Proximal Policy Optimization (PPO) for individual agent learning and pairs it with a tournament selection-based generational learning mechanism to foster morphological evolution. By building on Nvidia's Isaac Gym, DARLEI leverages GPU accelerated simulation to achieve over 20x speedup using just a single workstation, compared to previous work which required large distributed CPU clusters. We systematically characterize DARLEI's performance under various conditions, revealing factors impacting diversity of evolved morphologies. For example, by enabling inter-agent collisions within the simulator, we find that we can simulate some multi-agent interactions between the same morphology, and see how it influences individual agent capabilities and long-term evolutionary adaptation. While current results demonstrate limited diversity across generations, we hope to extend DARLEI in future work to include interactions between diverse morphologies in richer environments, and create a platform that allows for coevolving populations and investigating emergent behaviours in them. Our source code is also made publicly at https://saeejithnair.github.io/darlei.
Memory-Efficient Continual Learning Object Segmentation for Long Video
Sep 26, 2023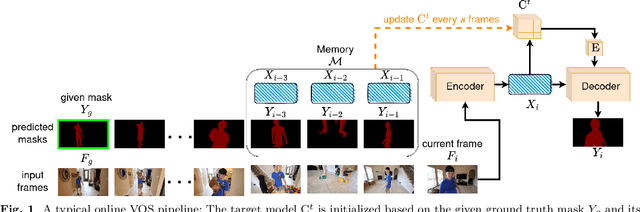



Recent state-of-the-art semi-supervised Video Object Segmentation (VOS) methods have shown significant improvements in target object segmentation accuracy when information from preceding frames is used in undertaking segmentation on the current frame. In particular, such memory-based approaches can help a model to more effectively handle appearance changes (representation drift) or occlusions. Ideally, for maximum performance, online VOS methods would need all or most of the preceding frames (or their extracted information) to be stored in memory and be used for online learning in consecutive frames. Such a solution is not feasible for long videos, as the required memory size would grow without bound. On the other hand, these methods can fail when memory is limited and a target object experiences repeated representation drifts throughout a video. We propose two novel techniques to reduce the memory requirement of online VOS methods while improving modeling accuracy and generalization on long videos. Motivated by the success of continual learning techniques in preserving previously-learned knowledge, here we propose Gated-Regularizer Continual Learning (GRCL), which improves the performance of any online VOS subject to limited memory, and a Reconstruction-based Memory Selection Continual Learning (RMSCL) which empowers online VOS methods to efficiently benefit from stored information in memory. Experimental results show that the proposed methods improve the performance of online VOS models up to 10 %, and boosts their robustness on long-video datasets while maintaining comparable performance on short-video datasets DAVIS16 and DAVIS17.
NAS-NeRF: Generative Neural Architecture Search for Neural Radiance Fields
Sep 25, 2023



Neural radiance fields (NeRFs) enable high-quality novel view synthesis, but their prohibitively high computational complexity limits deployability, especially on resource-constrained platforms. To enable practical usage of NeRFs, quality tuning is essential to reduce computational complexity, akin to adjustable graphics settings in video games. However while existing solutions strive for efficiency, they use one-size-fits-all architectures regardless of scene complexity, although the same architecture may be unnecessarily large for simple scenes but insufficient for complex ones. Thus as NeRFs become more widely used for 3D visualization, there is a need to dynamically optimize the neural network component of NeRFs to achieve a balance between computational complexity and specific targets for synthesis quality. Addressing this gap, we introduce NAS-NeRF: a generative neural architecture search strategy uniquely tailored to generate NeRF architectures on a per-scene basis by optimizing the trade-off between complexity and performance, while adhering to constraints on computational budget and minimum synthesis quality. Our experiments on the Blender synthetic dataset show the proposed NAS-NeRF can generate architectures up to 5.74$\times$ smaller, with 4.19$\times$ fewer FLOPs, and 1.93$\times$ faster on a GPU than baseline NeRFs, without suffering a drop in SSIM. Furthermore, we illustrate that NAS-NeRF can also achieve architectures up to 23$\times$ smaller, 22$\times$ fewer FLOPs, and 4.7$\times$ faster than baseline NeRFs with only a 5.3\% average SSIM drop. The source code for our work is also made publicly available at https://saeejithnair.github.io/NAS-NeRF.
Fast GraspNeXt: A Fast Self-Attention Neural Network Architecture for Multi-task Learning in Computer Vision Tasks for Robotic Grasping on the Edge
Apr 21, 2023Multi-task learning has shown considerable promise for improving the performance of deep learning-driven vision systems for the purpose of robotic grasping. However, high architectural and computational complexity can result in poor suitability for deployment on embedded devices that are typically leveraged in robotic arms for real-world manufacturing and warehouse environments. As such, the design of highly efficient multi-task deep neural network architectures tailored for computer vision tasks for robotic grasping on the edge is highly desired for widespread adoption in manufacturing environments. Motivated by this, we propose Fast GraspNeXt, a fast self-attention neural network architecture tailored for embedded multi-task learning in computer vision tasks for robotic grasping. To build Fast GraspNeXt, we leverage a generative network architecture search strategy with a set of architectural constraints customized to achieve a strong balance between multi-task learning performance and embedded inference efficiency. Experimental results on the MetaGraspNet benchmark dataset show that the Fast GraspNeXt network design achieves the highest performance (average precision (AP), accuracy, and mean squared error (MSE)) across multiple computer vision tasks when compared to other efficient multi-task network architecture designs, while having only 17.8M parameters (about >5x smaller), 259 GFLOPs (as much as >5x lower) and as much as >3.15x faster on a NVIDIA Jetson TX2 embedded processor.
High-Throughput, High-Performance Deep Learning-Driven Light Guide Plate Surface Visual Quality Inspection Tailored for Real-World Manufacturing Environments
Dec 20, 2022



Light guide plates are essential optical components widely used in a diverse range of applications ranging from medical lighting fixtures to back-lit TV displays. In this work, we introduce a fully-integrated, high-throughput, high-performance deep learning-driven workflow for light guide plate surface visual quality inspection (VQI) tailored for real-world manufacturing environments. To enable automated VQI on the edge computing within the fully-integrated VQI system, a highly compact deep anti-aliased attention condenser neural network (which we name LightDefectNet) tailored specifically for light guide plate surface defect detection in resource-constrained scenarios was created via machine-driven design exploration with computational and "best-practices" constraints as well as L_1 paired classification discrepancy loss. Experiments show that LightDetectNet achieves a detection accuracy of ~98.2% on the LGPSDD benchmark while having just 770K parameters (~33X and ~6.9X lower than ResNet-50 and EfficientNet-B0, respectively) and ~93M FLOPs (~88X and ~8.4X lower than ResNet-50 and EfficientNet-B0, respectively) and ~8.8X faster inference speed than EfficientNet-B0 on an embedded ARM processor. As such, the proposed deep learning-driven workflow, integrated with the aforementioned LightDefectNet neural network, is highly suited for high-throughput, high-performance light plate surface VQI within real-world manufacturing environments.
Faster Attention Is What You Need: A Fast Self-Attention Neural Network Backbone Architecture for the Edge via Double-Condensing Attention Condensers
Aug 22, 2022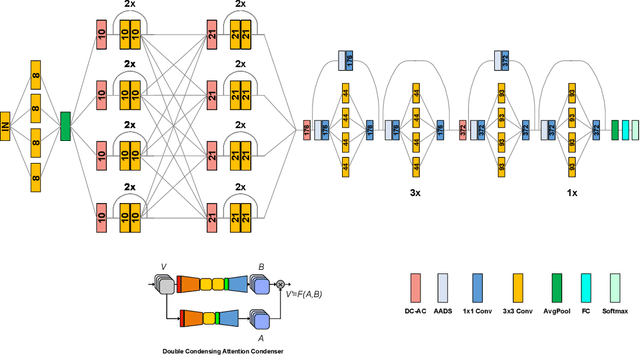
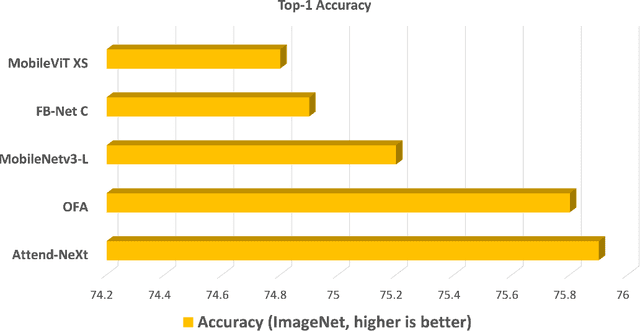
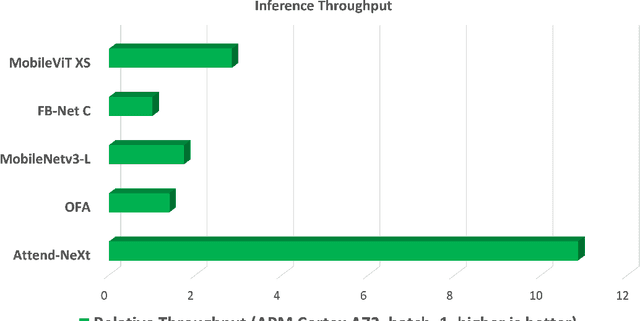
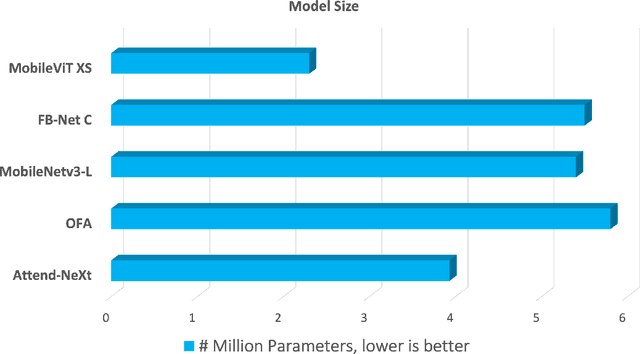
With the growing adoption of deep learning for on-device TinyML applications, there has been an ever-increasing demand for more efficient neural network backbones optimized for the edge. Recently, the introduction of attention condenser networks have resulted in low-footprint, highly-efficient, self-attention neural networks that strike a strong balance between accuracy and speed. In this study, we introduce a new faster attention condenser design called double-condensing attention condensers that enable more condensed feature embedding. We further employ a machine-driven design exploration strategy that imposes best practices design constraints for greater efficiency and robustness to produce the macro-micro architecture constructs of the backbone. The resulting backbone (which we name AttendNeXt) achieves significantly higher inference throughput on an embedded ARM processor when compared to several other state-of-the-art efficient backbones (>10X faster than FB-Net C at higher accuracy and speed and >10X faster than MobileOne-S1 at smaller size) while having a small model size (>1.37X smaller than MobileNetv3-L at higher accuracy and speed) and strong accuracy (1.1% higher top-1 accuracy than MobileViT XS on ImageNet at higher speed). These promising results demonstrate that exploring different efficient architecture designs and self-attention mechanisms can lead to interesting new building blocks for TinyML applications.
MAPLE-X: Latency Prediction with Explicit Microprocessor Prior Knowledge
May 25, 2022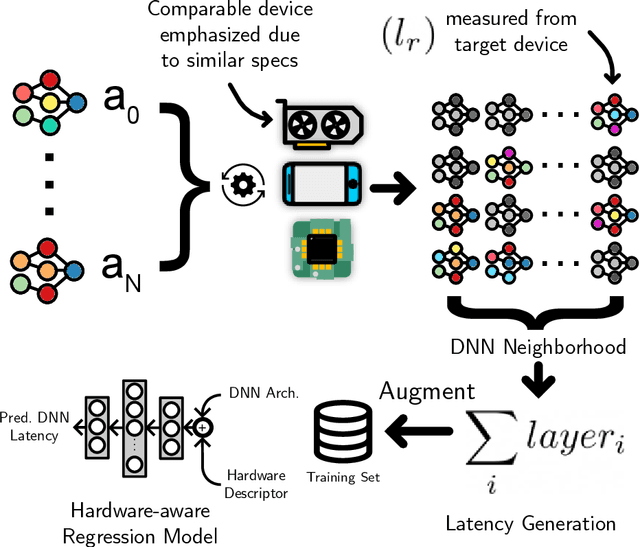
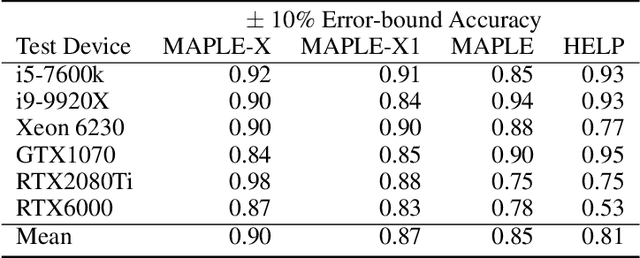
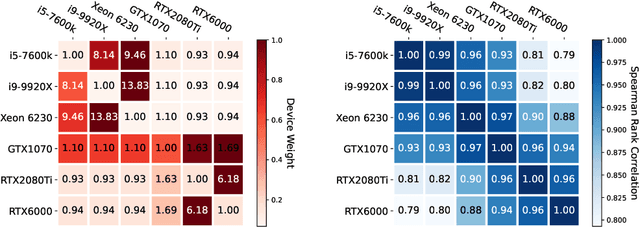
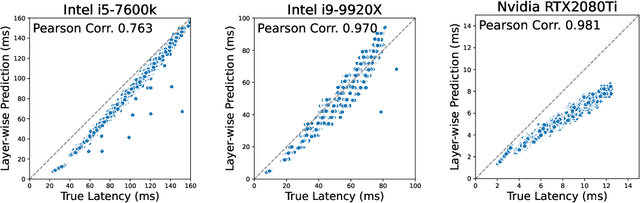
Deep neural network (DNN) latency characterization is a time-consuming process and adds significant cost to Neural Architecture Search (NAS) processes when searching for efficient convolutional neural networks for embedded vision applications. DNN Latency is a hardware dependent metric and requires direct measurement or inference on target hardware. A recently introduced latency estimation technique known as MAPLE predicts DNN execution time on previously unseen hardware devices by using hardware performance counters. Leveraging these hardware counters in the form of an implicit prior, MAPLE achieves state-of-the-art performance in latency prediction. Here, we propose MAPLE-X which extends MAPLE by incorporating explicit prior knowledge of hardware devices and DNN architecture latency to better account for model stability and robustness. First, by identifying DNN architectures that exhibit a similar latency to each other, we can generate multiple virtual examples to significantly improve the accuracy over MAPLE. Secondly, the hardware specifications are used to determine the similarity between training and test hardware to emphasize training samples captured from comparable devices (domains) and encourages improved domain alignment. Experimental results using a convolution neural network NAS benchmark across different types of devices, including an Intel processor that is now used for embedded vision applications, demonstrate a 5% improvement over MAPLE and 9% over HELP. Furthermore, we include ablation studies to independently assess the benefits of virtual examples and hardware-based sample importance.
MAPLE-Edge: A Runtime Latency Predictor for Edge Devices
Apr 27, 2022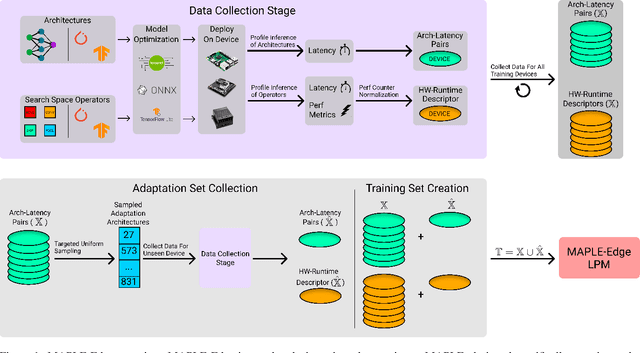
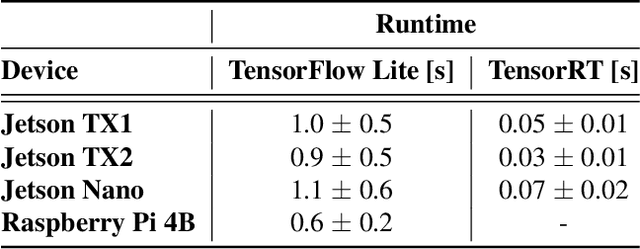
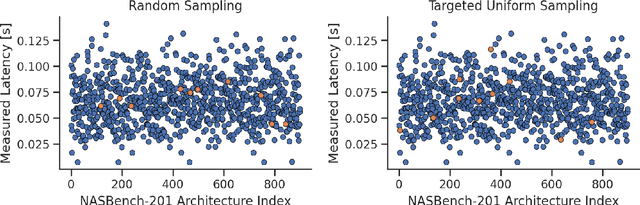
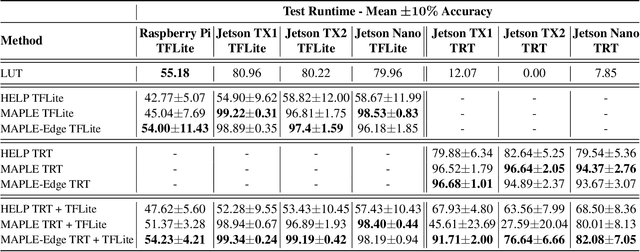
Neural Architecture Search (NAS) has enabled automatic discovery of more efficient neural network architectures, especially for mobile and embedded vision applications. Although recent research has proposed ways of quickly estimating latency on unseen hardware devices with just a few samples, little focus has been given to the challenges of estimating latency on runtimes using optimized graphs, such as TensorRT and specifically for edge devices. In this work, we propose MAPLE-Edge, an edge device-oriented extension of MAPLE, the state-of-the-art latency predictor for general purpose hardware, where we train a regression network on architecture-latency pairs in conjunction with a hardware-runtime descriptor to effectively estimate latency on a diverse pool of edge devices. Compared to MAPLE, MAPLE-Edge can describe the runtime and target device platform using a much smaller set of CPU performance counters that are widely available on all Linux kernels, while still achieving up to +49.6% accuracy gains against previous state-of-the-art baseline methods on optimized edge device runtimes, using just 10 measurements from an unseen target device. We also demonstrate that unlike MAPLE which performs best when trained on a pool of devices sharing a common runtime, MAPLE-Edge can effectively generalize across runtimes by applying a trick of normalizing performance counters by the operator latency, in the measured hardware-runtime descriptor. Lastly, we show that for runtimes exhibiting lower than desired accuracy, performance can be boosted by collecting additional samples from the target device, with an extra 90 samples translating to gains of nearly +40%.
CellDefectNet: A Machine-designed Attention Condenser Network for Electroluminescence-based Photovoltaic Cell Defect Inspection
Apr 25, 2022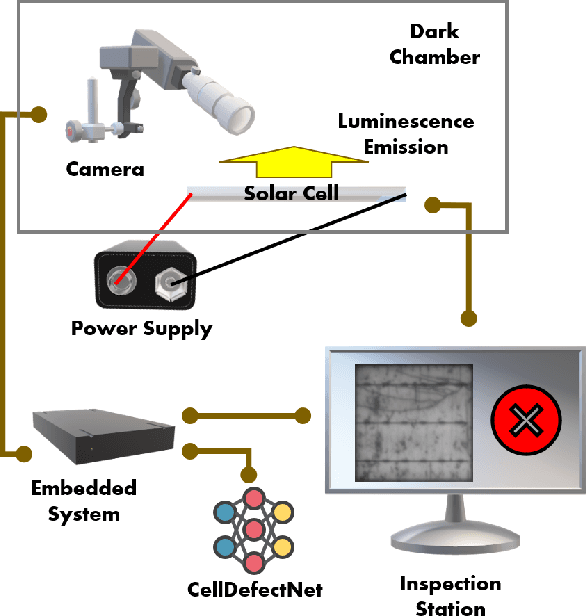
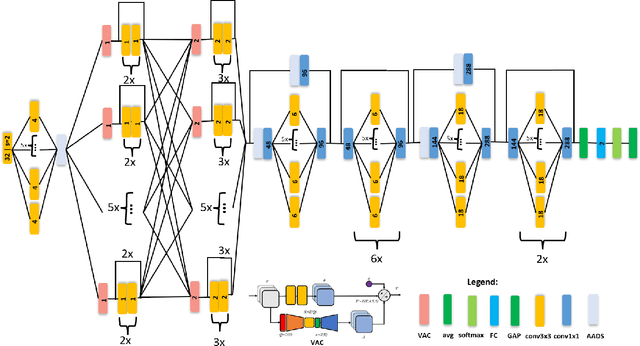
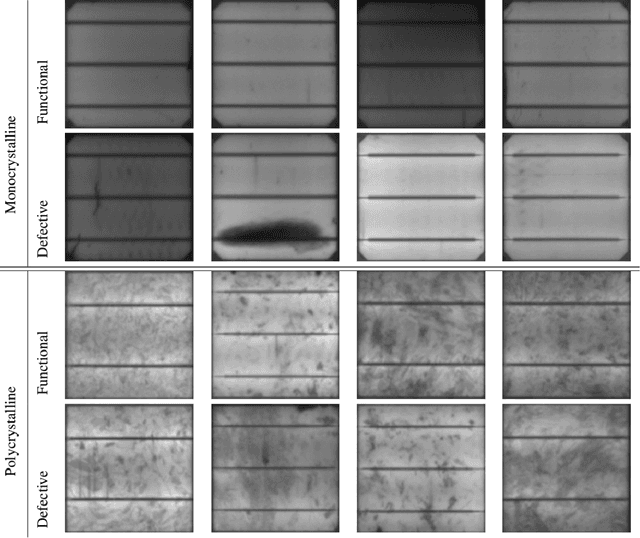
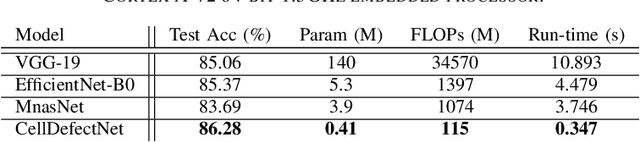
Photovoltaic cells are electronic devices that convert light energy to electricity, forming the backbone of solar energy harvesting systems. An essential step in the manufacturing process for photovoltaic cells is visual quality inspection using electroluminescence imaging to identify defects such as cracks, finger interruptions, and broken cells. A big challenge faced by industry in photovoltaic cell visual inspection is the fact that it is currently done manually by human inspectors, which is extremely time consuming, laborious, and prone to human error. While deep learning approaches holds great potential to automating this inspection, the hardware resource-constrained manufacturing scenario makes it challenging for deploying complex deep neural network architectures. In this work, we introduce CellDefectNet, a highly efficient attention condenser network designed via machine-driven design exploration specifically for electroluminesence-based photovoltaic cell defect detection on the edge. We demonstrate the efficacy of CellDefectNet on a benchmark dataset comprising of a diversity of photovoltaic cells captured using electroluminescence imagery, achieving an accuracy of ~86.3% while possessing just 410K parameters (~13$\times$ lower than EfficientNet-B0, respectively) and ~115M FLOPs (~12$\times$ lower than EfficientNet-B0) and ~13$\times$ faster on an ARM Cortex A-72 embedded processor when compared to EfficientNet-B0.
LightDefectNet: A Highly Compact Deep Anti-Aliased Attention Condenser Neural Network Architecture for Light Guide Plate Surface Defect Detection
Apr 25, 2022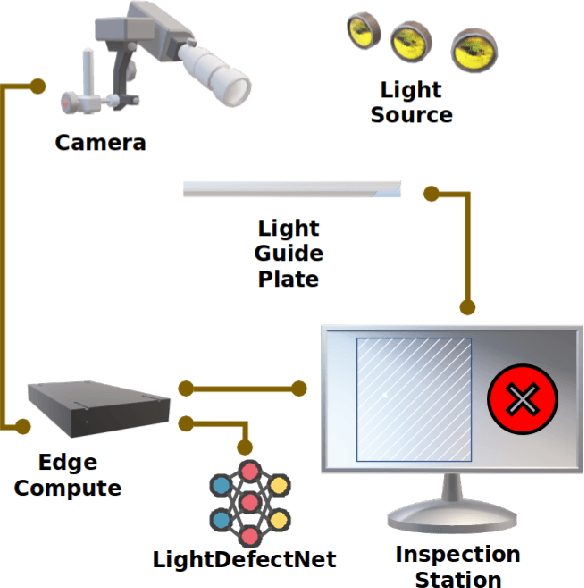

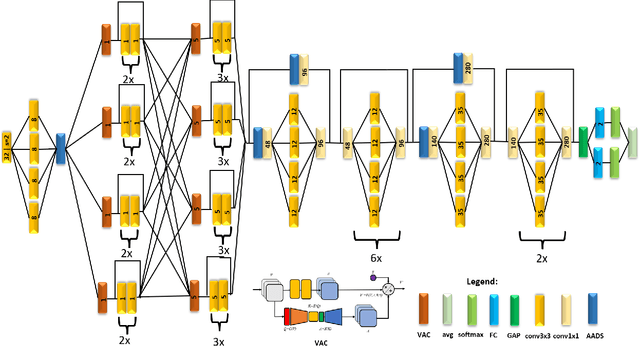
Light guide plates are essential optical components widely used in a diverse range of applications ranging from medical lighting fixtures to back-lit TV displays. An essential step in the manufacturing of light guide plates is the quality inspection of defects such as scratches, bright/dark spots, and impurities. This is mainly done in industry through manual visual inspection for plate pattern irregularities, which is time-consuming and prone to human error and thus act as a significant barrier to high-throughput production. Advances in deep learning-driven computer vision has led to the exploration of automated visual quality inspection of light guide plates to improve inspection consistency, accuracy, and efficiency. However, given the cost constraints in visual inspection scenarios, the widespread adoption of deep learning-driven computer vision methods for inspecting light guide plates has been greatly limited due to high computational requirements. In this study, we explore the utilization of machine-driven design exploration with computational and "best-practices" constraints as well as L$_1$ paired classification discrepancy loss to create LightDefectNet, a highly compact deep anti-aliased attention condenser neural network architecture tailored specifically for light guide plate surface defect detection in resource-constrained scenarios. Experiments show that LightDetectNet achieves a detection accuracy of $\sim$98.2% on the LGPSDD benchmark while having just 770K parameters ($\sim$33$\times$ and $\sim$6.9$\times$ lower than ResNet-50 and EfficientNet-B0, respectively) and $\sim$93M FLOPs ($\sim$88$\times$ and $\sim$8.4$\times$ lower than ResNet-50 and EfficientNet-B0, respectively) and $\sim$8.8$\times$ faster inference speed than EfficientNet-B0 on an embedded ARM processor.