 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAPLE-X: Latency Prediction with Explicit Microprocessor Prior Knowledge
Paper and Code
May 25, 2022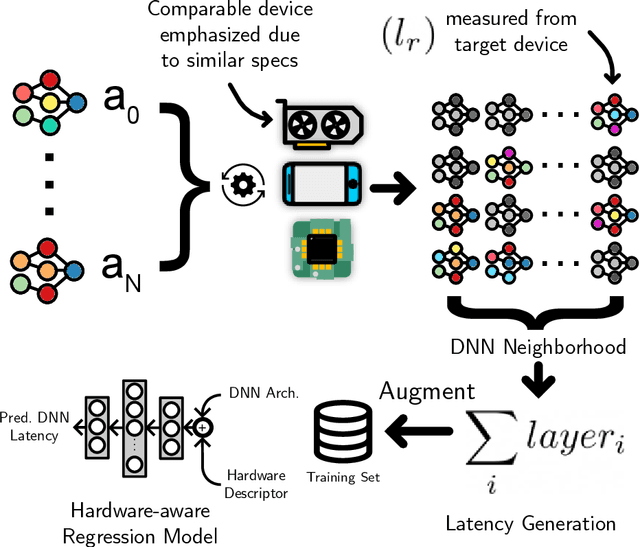
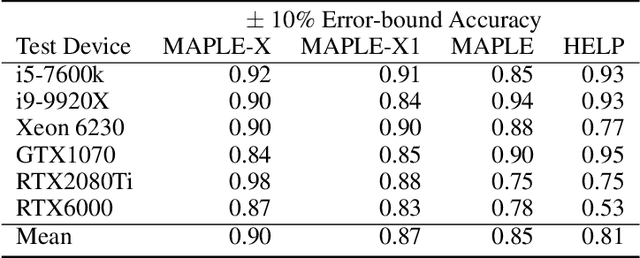
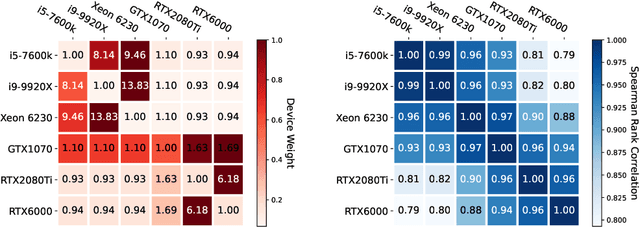
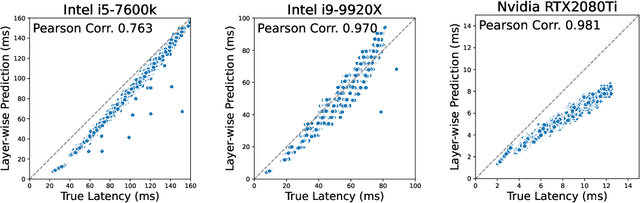
Deep neural network (DNN) latency characterization is a time-consuming process and adds significant cost to Neural Architecture Search (NAS) processes when searching for efficient convolutional neural networks for embedded vision applications. DNN Latency is a hardware dependent metric and requires direct measurement or inference on target hardware. A recently introduced latency estimation technique known as MAPLE predicts DNN execution time on previously unseen hardware devices by using hardware performance counters. Leveraging these hardware counters in the form of an implicit prior, MAPLE achieves state-of-the-art performance in latency prediction. Here, we propose MAPLE-X which extends MAPLE by incorporating explicit prior knowledge of hardware devices and DNN architecture latency to better account for model stability and robustness. First, by identifying DNN architectures that exhibit a similar latency to each other, we can generate multiple virtual examples to significantly improve the accuracy over MAPLE. Secondly, the hardware specifications are used to determine the similarity between training and test hardware to emphasize training samples captured from comparable devices (domains) and encourages improved domain alignment. Experimental results using a convolution neural network NAS benchmark across different types of devices, including an Intel processor that is now used for embedded vision applications, demonstrate a 5% improvement over MAPLE and 9% over HELP. Furthermore, we include ablation studies to independently assess the benefits of virtual examples and hardware-based sample importance.