 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaster Attention Is What You Need: A Fast Self-Attention Neural Network Backbone Architecture for the Edge via Double-Condensing Attention Condensers
Paper and Code
Aug 22, 2022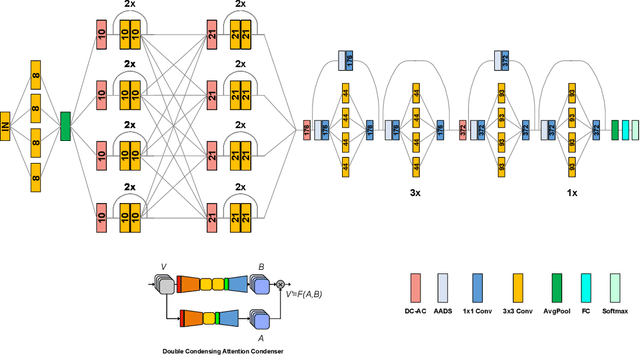
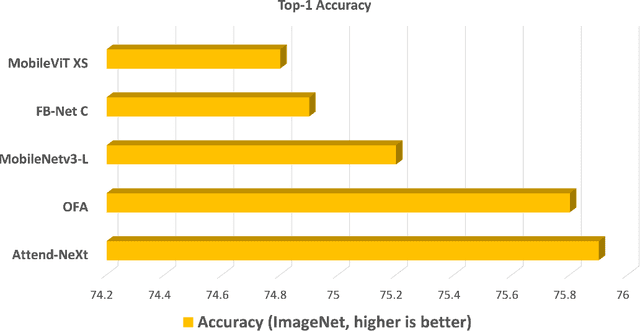
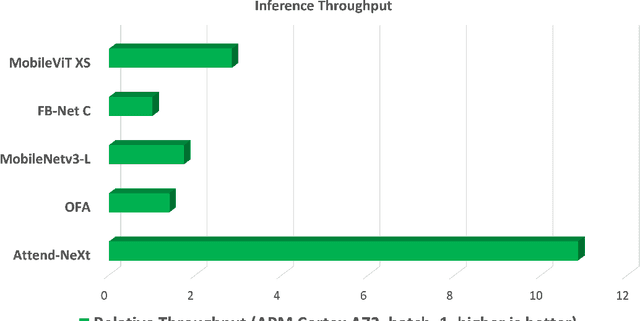
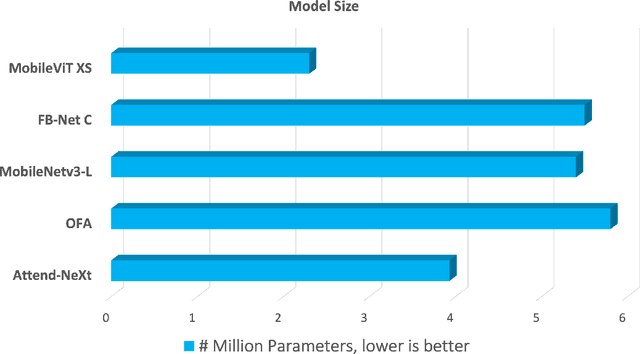
With the growing adoption of deep learning for on-device TinyML applications, there has been an ever-increasing demand for more efficient neural network backbones optimized for the edge. Recently, the introduction of attention condenser networks have resulted in low-footprint, highly-efficient, self-attention neural networks that strike a strong balance between accuracy and speed. In this study, we introduce a new faster attention condenser design called double-condensing attention condensers that enable more condensed feature embedding. We further employ a machine-driven design exploration strategy that imposes best practices design constraints for greater efficiency and robustness to produce the macro-micro architecture constructs of the backbone. The resulting backbone (which we name AttendNeXt) achieves significantly higher inference throughput on an embedded ARM processor when compared to several other state-of-the-art efficient backbones (>10X faster than FB-Net C at higher accuracy and speed and >10X faster than MobileOne-S1 at smaller size) while having a small model size (>1.37X smaller than MobileNetv3-L at higher accuracy and speed) and strong accuracy (1.1% higher top-1 accuracy than MobileViT XS on ImageNet at higher speed). These promising results demonstrate that exploring different efficient architecture designs and self-attention mechanisms can lead to interesting new building blocks for TinyML applications.