 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetaFood3D: Large 3D Food Object Dataset with Nutrition Values
Sep 03, 2024
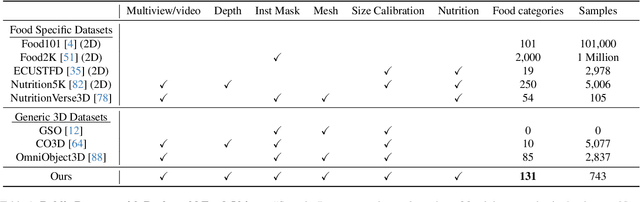
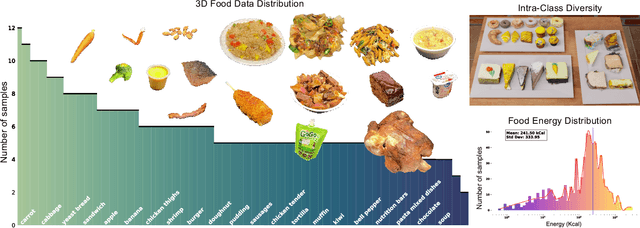
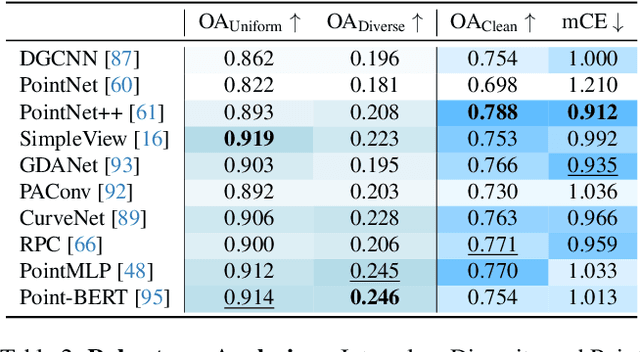
Food computing is both important and challenging in computer vision (CV). It significantly contributes to the development of CV algorithms due to its frequent presence in datasets across various applications, ranging from classification and instance segmentation to 3D reconstruction. The polymorphic shapes and textures of food, coupled with high variation in forms and vast multimodal information, including language descriptions and nutritional data, make food computing a complex and demanding task for modern CV algorithms. 3D food modeling is a new frontier for addressing food-related problems, due to its inherent capability to deal with random camera views and its straightforward representation for calculating food portion size. However, the primary hurdle in the development of algorithms for food object analysis is the lack of nutrition values in existing 3D datasets. Moreover, in the broader field of 3D research, there is a critical need for domain-specific test datasets. To bridge the gap between general 3D vision and food computing research, we propose MetaFood3D. This dataset consists of 637 meticulously labeled 3D food objects across 108 categories, featuring detailed nutrition information, weight, and food codes linked to a comprehensive nutrition database. The dataset emphasizes intra-class diversity and includes rich modalities such as textured mesh files, RGB-D videos, and segmentation masks. Experimental results demonstrate our dataset's significant potential for improving algorithm performance, highlight the challenging gap between video captures and 3D scanned data, and show the strength of the MetaFood3D dataset in high-quality data generation, simulation, and augmentation.
NutritionVerse-Synth: An Open Access Synthetically Generated 2D Food Scene Dataset for Dietary Intake Estimation
Dec 11, 2023Manually tracking nutritional intake via food diaries is error-prone and burdensome. Automated computer vision techniques show promise for dietary monitoring but require large and diverse food image datasets. To address this need, we introduce NutritionVerse-Synth (NV-Synth), a large-scale synthetic food image dataset. NV-Synth contains 84,984 photorealistic meal images rendered from 7,082 dynamically plated 3D scenes. Each scene is captured from 12 viewpoints and includes perfect ground truth annotations such as RGB, depth, semantic, instance, and amodal segmentation masks, bounding boxes, and detailed nutritional information per food item. We demonstrate the diversity of NV-Synth across foods, compositions, viewpoints, and lighting. As the largest open-source synthetic food dataset, NV-Synth highlights the value of physics-based simulations for enabling scalable and controllable generation of diverse photorealistic meal images to overcome data limitations and drive advancements in automated dietary assessment using computer vision. In addition to the dataset, the source code for our data generation framework is also made publicly available at https://saeejithnair.github.io/nvsynth.
DARLEI: Deep Accelerated Reinforcement Learning with Evolutionary Intelligence
Dec 08, 2023We present DARLEI, a framework that combines evolutionary algorithms with parallelized reinforcement learning for efficiently training and evolving populations of UNIMAL agents. Our approach utilizes Proximal Policy Optimization (PPO) for individual agent learning and pairs it with a tournament selection-based generational learning mechanism to foster morphological evolution. By building on Nvidia's Isaac Gym, DARLEI leverages GPU accelerated simulation to achieve over 20x speedup using just a single workstation, compared to previous work which required large distributed CPU clusters. We systematically characterize DARLEI's performance under various conditions, revealing factors impacting diversity of evolved morphologies. For example, by enabling inter-agent collisions within the simulator, we find that we can simulate some multi-agent interactions between the same morphology, and see how it influences individual agent capabilities and long-term evolutionary adaptation. While current results demonstrate limited diversity across generations, we hope to extend DARLEI in future work to include interactions between diverse morphologies in richer environments, and create a platform that allows for coevolving populations and investigating emergent behaviours in them. Our source code is also made publicly at https://saeejithnair.github.io/darlei.
NAS-NeRF: Generative Neural Architecture Search for Neural Radiance Fields
Sep 25, 2023



Neural radiance fields (NeRFs) enable high-quality novel view synthesis, but their prohibitively high computational complexity limits deployability, especially on resource-constrained platforms. To enable practical usage of NeRFs, quality tuning is essential to reduce computational complexity, akin to adjustable graphics settings in video games. However while existing solutions strive for efficiency, they use one-size-fits-all architectures regardless of scene complexity, although the same architecture may be unnecessarily large for simple scenes but insufficient for complex ones. Thus as NeRFs become more widely used for 3D visualization, there is a need to dynamically optimize the neural network component of NeRFs to achieve a balance between computational complexity and specific targets for synthesis quality. Addressing this gap, we introduce NAS-NeRF: a generative neural architecture search strategy uniquely tailored to generate NeRF architectures on a per-scene basis by optimizing the trade-off between complexity and performance, while adhering to constraints on computational budget and minimum synthesis quality. Our experiments on the Blender synthetic dataset show the proposed NAS-NeRF can generate architectures up to 5.74$\times$ smaller, with 4.19$\times$ fewer FLOPs, and 1.93$\times$ faster on a GPU than baseline NeRFs, without suffering a drop in SSIM. Furthermore, we illustrate that NAS-NeRF can also achieve architectures up to 23$\times$ smaller, 22$\times$ fewer FLOPs, and 4.7$\times$ faster than baseline NeRFs with only a 5.3\% average SSIM drop. The source code for our work is also made publicly available at https://saeejithnair.github.io/NAS-NeRF.
NutritionVerse: Empirical Study of Various Dietary Intake Estimation Approaches
Sep 14, 2023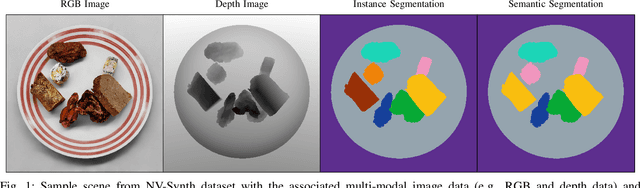



Accurate dietary intake estimation is critical for informing policies and programs to support healthy eating, as malnutrition has been directly linked to decreased quality of life. However self-reporting methods such as food diaries suffer from substantial bias. Other conventional dietary assessment techniques and emerging alternative approaches such as mobile applications incur high time costs and may necessitate trained personnel. Recent work has focused on using computer vision and machine learning to automatically estimate dietary intake from food images, but the lack of comprehensive datasets with diverse viewpoints, modalities and food annotations hinders the accuracy and realism of such methods. To address this limitation, we introduce NutritionVerse-Synth, the first large-scale dataset of 84,984 photorealistic synthetic 2D food images with associated dietary information and multimodal annotations (including depth images, instance masks, and semantic masks). Additionally, we collect a real image dataset, NutritionVerse-Real, containing 889 images of 251 dishes to evaluate realism. Leveraging these novel datasets, we develop and benchmark NutritionVerse, an empirical study of various dietary intake estimation approaches, including indirect segmentation-based and direct prediction networks. We further fine-tune models pretrained on synthetic data with real images to provide insights into the fusion of synthetic and real data. Finally, we release both datasets (NutritionVerse-Synth, NutritionVerse-Real) on https://www.kaggle.com/nutritionverse/datasets as part of an open initiative to accelerate machine learning for dietary sensing.
TurboViT: Generating Fast Vision Transformers via Generative Architecture Search
Aug 22, 2023


Vision transformers have shown unprecedented levels of performance in tackling various visual perception tasks in recent years. However, the architectural and computational complexity of such network architectures have made them challenging to deploy in real-world applications with high-throughput, low-memory requirements. As such, there has been significant research recently on the design of efficient vision transformer architectures. In this study, we explore the generation of fast vision transformer architecture designs via generative architecture search (GAS) to achieve a strong balance between accuracy and architectural and computational efficiency. Through this generative architecture search process, we create TurboViT, a highly efficient hierarchical vision transformer architecture design that is generated around mask unit attention and Q-pooling design patterns. The resulting TurboViT architecture design achieves significantly lower architectural computational complexity (>2.47$\times$ smaller than FasterViT-0 while achieving same accuracy) and computational complexity (>3.4$\times$ fewer FLOPs and 0.9% higher accuracy than MobileViT2-2.0) when compared to 10 other state-of-the-art efficient vision transformer network architecture designs within a similar range of accuracy on the ImageNet-1K dataset. Furthermore, TurboViT demonstrated strong inference latency and throughput in both low-latency and batch processing scenarios (>3.21$\times$ lower latency and >3.18$\times$ higher throughput compared to FasterViT-0 for low-latency scenario). These promising results demonstrate the efficacy of leveraging generative architecture search for generating efficient transformer architecture designs for high-throughput scenarios.
Fast GraspNeXt: A Fast Self-Attention Neural Network Architecture for Multi-task Learning in Computer Vision Tasks for Robotic Grasping on the Edge
Apr 21, 2023Multi-task learning has shown considerable promise for improving the performance of deep learning-driven vision systems for the purpose of robotic grasping. However, high architectural and computational complexity can result in poor suitability for deployment on embedded devices that are typically leveraged in robotic arms for real-world manufacturing and warehouse environments. As such, the design of highly efficient multi-task deep neural network architectures tailored for computer vision tasks for robotic grasping on the edge is highly desired for widespread adoption in manufacturing environments. Motivated by this, we propose Fast GraspNeXt, a fast self-attention neural network architecture tailored for embedded multi-task learning in computer vision tasks for robotic grasping. To build Fast GraspNeXt, we leverage a generative network architecture search strategy with a set of architectural constraints customized to achieve a strong balance between multi-task learning performance and embedded inference efficiency. Experimental results on the MetaGraspNet benchmark dataset show that the Fast GraspNeXt network design achieves the highest performance (average precision (AP), accuracy, and mean squared error (MSE)) across multiple computer vision tasks when compared to other efficient multi-task network architecture designs, while having only 17.8M parameters (about >5x smaller), 259 GFLOPs (as much as >5x lower) and as much as >3.15x faster on a NVIDIA Jetson TX2 embedded processor.
NutritionVerse-Thin: An Optimized Strategy for Enabling Improved Rendering of 3D Thin Food Models
Apr 12, 2023

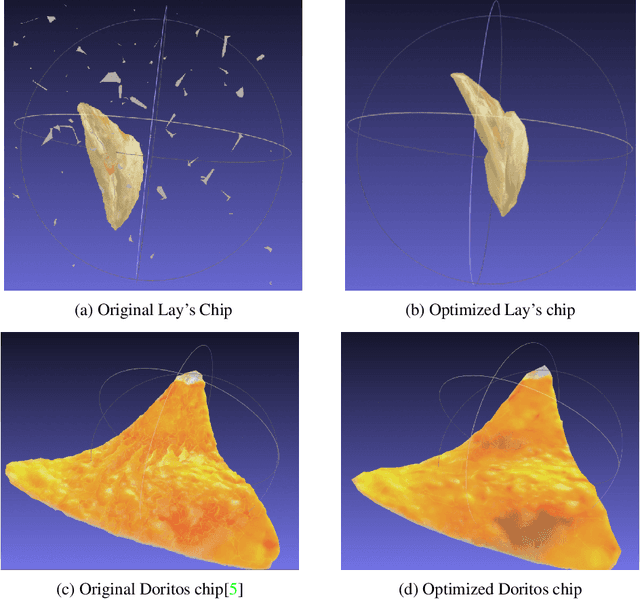

With the growth in capabilities of generative models, there has been growing interest in using photo-realistic renders of common 3D food items to improve downstream tasks such as food printing, nutrition prediction, or management of food wastage. Despite 3D modelling capabilities being more accessible than ever due to the success of NeRF based view-synthesis, such rendering methods still struggle to correctly capture thin food objects, often generating meshes with significant holes. In this study, we present an optimized strategy for enabling improved rendering of thin 3D food models, and demonstrate qualitative improvements in rendering quality. Our method generates the 3D model mesh via a proposed thin-object-optimized differentiable reconstruction method and tailors the strategy at both the data collection and training stages to better handle thin objects. While simple, we find that this technique can be employed for quick and highly consistent capturing of thin 3D objects.
NutritionVerse-3D: A 3D Food Model Dataset for Nutritional Intake Estimation
Apr 12, 2023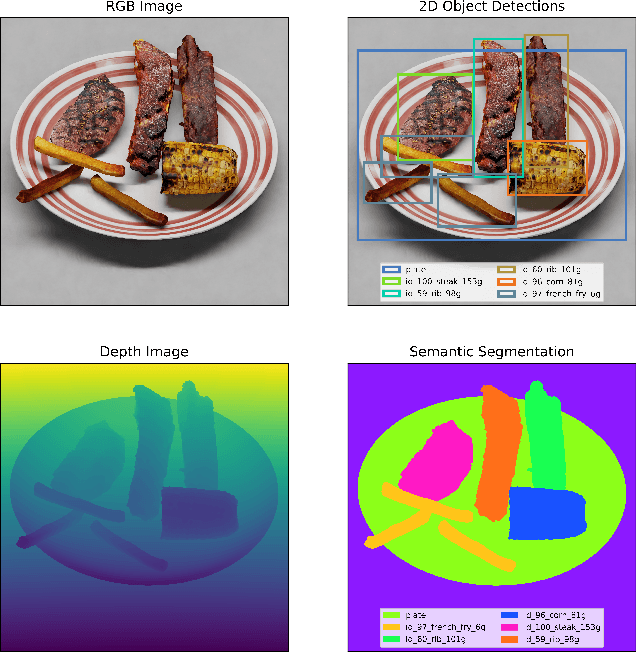
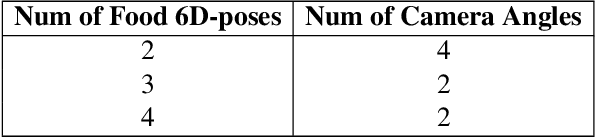


77% of adults over 50 want to age in place today, presenting a major challenge to ensuring adequate nutritional intake. It has been reported that one in four older adults that are 65 years or older are malnourished and given the direct link between malnutrition and decreased quality of life, there have been numerous studies conducted on how to efficiently track nutritional intake of food. Recent advancements in machine learning and computer vision show promise of automated nutrition tracking methods of food, but require a large high-quality dataset in order to accurately identify the nutrients from the food on the plate. Unlike existing datasets, a collection of 3D models with nutritional information allow for view synthesis to create an infinite number of 2D images for any given viewpoint/camera angle along with the associated nutritional information. In this paper, we develop a methodology for collecting high-quality 3D models for food items with a particular focus on speed and consistency, and introduce NutritionVerse-3D, a large-scale high-quality high-resolution dataset of 105 3D food models, in conjunction with their associated weight, food name, and nutritional value. These models allow for large quantity food intake scenes, diverse and customizable scene layout, and an infinite number of camera settings and lighting conditions. NutritionVerse-3D is publicly available as a part of an open initiative to accelerate machine learning for nutrition sensing.
PCBDet: An Efficient Deep Neural Network Object Detection Architecture for Automatic PCB Component Detection on the Edge
Jan 23, 2023There can be numerous electronic components on a given PCB, making the task of visual inspection to detect defects very time-consuming and prone to error, especially at scale. There has thus been significant interest in automatic PCB component detection, particularly leveraging deep learning. However, deep neural networks typically require high computational resources, possibly limiting their feasibility in real-world use cases in manufacturing, which often involve high-volume and high-throughput detection with constrained edge computing resource availability. As a result of an exploration of efficient deep neural network architectures for this use case, we introduce PCBDet, an attention condenser network design that provides state-of-the-art inference throughput while achieving superior PCB component detection performance compared to other state-of-the-art efficient architecture designs. Experimental results show that PCBDet can achieve up to 2$\times$ inference speed-up on an ARM Cortex A72 processor when compared to an EfficientNet-based design while achieving $\sim$2-4\% higher mAP on the FICS-PCB benchmark dataset.