 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetaFood3D: Large 3D Food Object Dataset with Nutrition Values
Sep 03, 2024
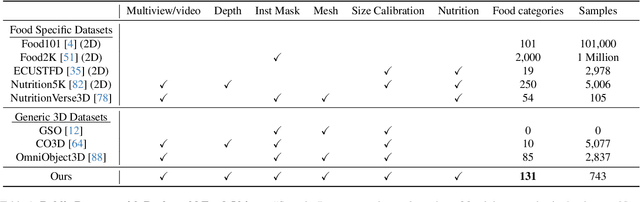
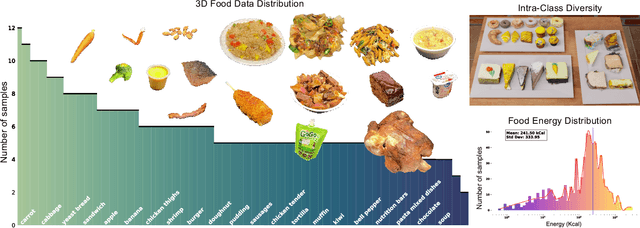
Food computing is both important and challenging in computer vision (CV). It significantly contributes to the development of CV algorithms due to its frequent presence in datasets across various applications, ranging from classification and instance segmentation to 3D reconstruction. The polymorphic shapes and textures of food, coupled with high variation in forms and vast multimodal information, including language descriptions and nutritional data, make food computing a complex and demanding task for modern CV algorithms. 3D food modeling is a new frontier for addressing food-related problems, due to its inherent capability to deal with random camera views and its straightforward representation for calculating food portion size. However, the primary hurdle in the development of algorithms for food object analysis is the lack of nutrition values in existing 3D datasets. Moreover, in the broader field of 3D research, there is a critical need for domain-specific test datasets. To bridge the gap between general 3D vision and food computing research, we propose MetaFood3D. This dataset consists of 637 meticulously labeled 3D food objects across 108 categories, featuring detailed nutrition information, weight, and food codes linked to a comprehensive nutrition database. The dataset emphasizes intra-class diversity and includes rich modalities such as textured mesh files, RGB-D videos, and segmentation masks. Experimental results demonstrate our dataset's significant potential for improving algorithm performance, highlight the challenging gap between video captures and 3D scanned data, and show the strength of the MetaFood3D dataset in high-quality data generation, simulation, and augmentation.
Towards Real-Time Gaussian Splatting: Accelerating 3DGS through Photometric SLAM
Aug 07, 2024Initial applications of 3D Gaussian Splatting (3DGS) in Visual Simultaneous Localization and Mapping (VSLAM) demonstrate the generation of high-quality volumetric reconstructions from monocular video streams. However, despite these promising advancements, current 3DGS integrations have reduced tracking performance and lower operating speeds compared to traditional VSLAM. To address these issues, we propose integrating 3DGS with Direct Sparse Odometry, a monocular photometric SLAM system. We have done preliminary experiments showing that using Direct Sparse Odometry point cloud outputs, as opposed to standard structure-from-motion methods, significantly shortens the training time needed to achieve high-quality renders. Reducing 3DGS training time enables the development of 3DGS-integrated SLAM systems that operate in real-time on mobile hardware. These promising initial findings suggest further exploration is warranted in combining traditional VSLAM systems with 3DGS.
Robust Analysis of Multi-Task Learning on a Complex Vision System
Feb 05, 2024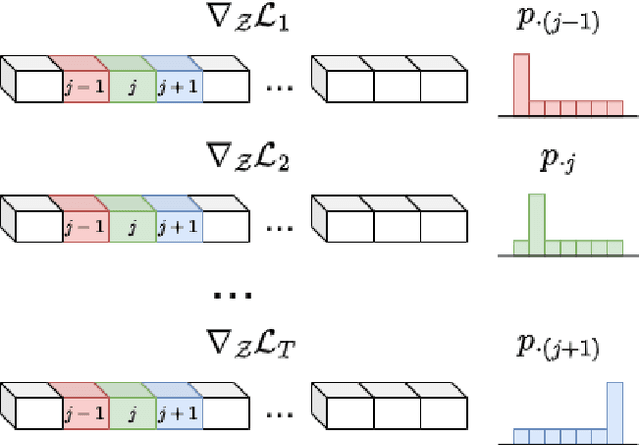
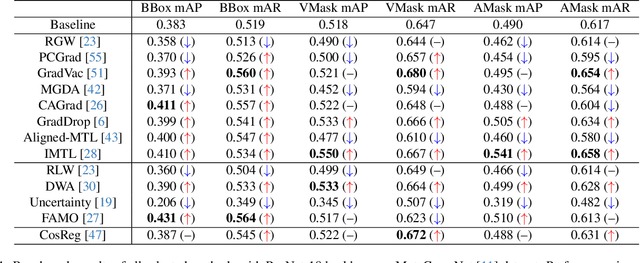
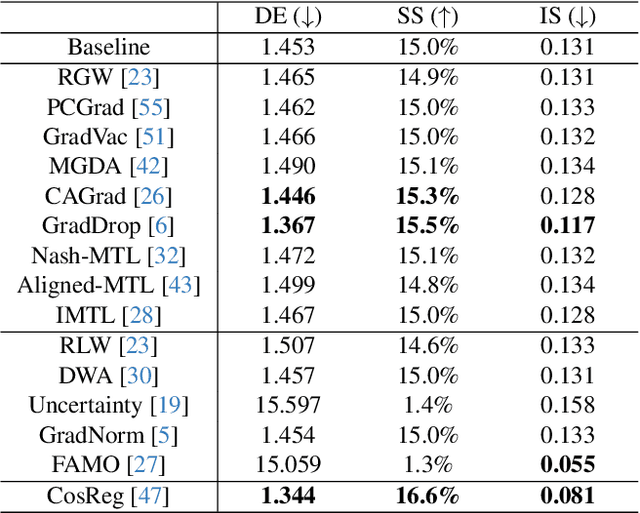
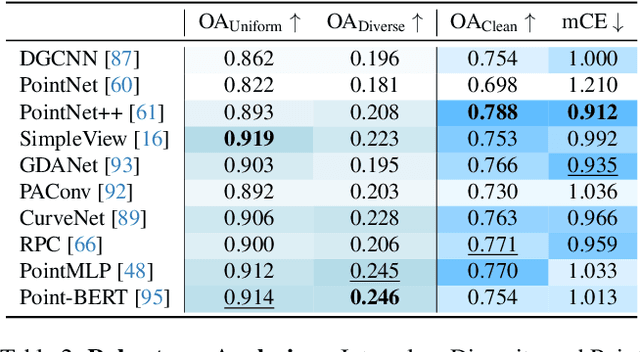
Multi-task learning (MTL) has been widely studied in the past decade. In particular, dozens of optimization algorithms have been proposed for different settings. While each of them claimed improvement when applied to certain models on certain datasets, there is still lack of deep understanding on the performance in complex real-worlds scenarios. We identify the gaps between research and application and make the following 4 contributions. (1) We comprehensively evaluate a large set of existing MTL optimization algorithms on the MetaGraspNet dataset designed for robotic grasping task, which is complex and has high real-world application values, and conclude the best-performing methods. (2) We empirically compare the method performance when applied on feature-level gradients versus parameter-level gradients over a large set of MTL optimization algorithms, and conclude that this feature-level gradients surrogate is reasonable when there are method-specific theoretical guarantee but not generalizable to all methods. (3) We provide insights on the problem of task interference and show that the existing perspectives of gradient angles and relative gradient norms do not precisely reflect the challenges of MTL, as the rankings of the methods based on these two indicators do not align well with those based on the test-set performance. (4) We provide a novel view of the task interference problem from the perspective of the latent space induced by the feature extractor and provide training monitoring results based on feature disentanglement.
DeepfakeArt Challenge: A Benchmark Dataset for Generative AI Art Forgery and Data Poisoning Detection
Jun 11, 2023



The tremendous recent advances in generative artificial intelligence techniques have led to significant successes and promise in a wide range of different applications ranging from conversational agents and textual content generation to voice and visual synthesis. Amid the rise in generative AI and its increasing widespread adoption, there has been significant growing concern over the use of generative AI for malicious purposes. In the realm of visual content synthesis using generative AI, key areas of significant concern has been image forgery (e.g., generation of images containing or derived from copyright content), and data poisoning (i.e., generation of adversarially contaminated images). Motivated to address these key concerns to encourage responsible generative AI, we introduce the DeepfakeArt Challenge, a large-scale challenge benchmark dataset designed specifically to aid in the building of machine learning algorithms for generative AI art forgery and data poisoning detection. Comprising of over 32,000 records across a variety of generative forgery and data poisoning techniques, each entry consists of a pair of images that are either forgeries / adversarially contaminated or not. Each of the generated images in the DeepfakeArt Challenge benchmark dataset has been quality checked in a comprehensive manner. The DeepfakeArt Challenge is a core part of GenAI4Good, a global open source initiative for accelerating machine learning for promoting responsible creation and deployment of generative AI for good.