 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Injury-Risk Screening in Baseball Pitching From Broadcast Video
Mar 05, 2026Injury prediction in pitching depends on precise biomechanical signals, yet gold-standard measurements come from expensive, stadium-installed multi-camera systems that are unavailable outside professional venues. We present a monocular video pipeline that recovers 18 clinically relevant biomechanics metrics from broadcast footage, positioning pose-derived kinematics as a scalable source for injury-risk modeling. Built on DreamPose3D, our approach introduces a drift-controlled global lifting module that recovers pelvis trajectory via velocity-based parameterization and sliding-window inference, lifting pelvis-rooted poses into global space. To address motion blur, compression artifacts, and extreme pitching poses, we incorporate a kinematics refinement pipeline with bone-length constraints, joint-limited inverse kinematics, smoothing, and symmetry constraints to ensure temporally stable and physically plausible kinematics. On 13 professional pitchers (156 paired pitches), 16/18 metrics achieve sub-degree agreement (MAE $< 1^{\circ}$). Using these metrics for injury prediction, an automated screening model achieves AUC 0.811 for Tommy John surgery and 0.825 for significant arm injuries on 7,348 pitchers. The resulting pose-derived metrics support scalable injury-risk screening, establishing monocular broadcast video as a viable alternative to stadium-scale motion capture for biomechanics.
Interpretable Pre-Release Baseball Pitch Type Anticipation from Broadcast 3D Kinematics
Mar 05, 2026How much can a pitcher's body reveal about the upcoming pitch? We study this question at scale by classifying eight pitch types from monocular 3D pose sequences, without access to ball-flight data. Our pipeline chains a diffusion-based 3D pose backbone with automatic pitching-event detection, groundtruth-validated biomechanical feature extraction, and gradient-boosted classification over 229 kinematic features. Evaluated on 119,561 professional pitches, the largest such benchmark to date, we achieve 80.4\% accuracy using body kinematics alone. A systematic importance analysis reveals that upper-body mechanics contribute 64.9\% of the predictive signal versus 35.1\% for the lower body, with wrist position (14.8\%) and trunk lateral tilt emerging as the most informative joint group and biomechanical feature, respectively. We further show that grip-defined variants (four-seam vs.\ two-seam fastball) are not separable from pose, establishing an empirical ceiling near 80\% and delineating where kinematic information ends and ball-flight information begins.
Avatar4D: Synthesizing Domain-Specific 4D Humans for Real-World Pose Estimation
Dec 18, 2025We present Avatar4D, a real-world transferable pipeline for generating customizable synthetic human motion datasets tailored to domain-specific applications. Unlike prior works, which focus on general, everyday motions and offer limited flexibility, our approach provides fine-grained control over body pose, appearance, camera viewpoint, and environmental context, without requiring any manual annotations. To validate the impact of Avatar4D, we focus on sports, where domain-specific human actions and movement patterns pose unique challenges for motion understanding. In this setting, we introduce Syn2Sport, a large-scale synthetic dataset spanning sports, including baseball and ice hockey. Avatar4D features high-fidelity 4D (3D geometry over time) human motion sequences with varying player appearances rendered in diverse environments. We benchmark several state-of-the-art pose estimation models on Syn2Sport and demonstrate their effectiveness for supervised learning, zero-shot transfer to real-world data, and generalization across sports. Furthermore, we evaluate how closely the generated synthetic data aligns with real-world datasets in feature space. Our results highlight the potential of such systems to generate scalable, controllable, and transferable human datasets for diverse domain-specific tasks without relying on domain-specific real data.
Ice Hockey Puck Localization Using Contextual Cues
Jun 04, 2025
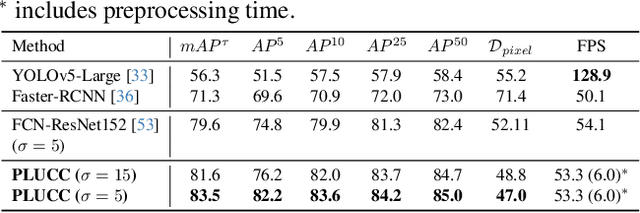
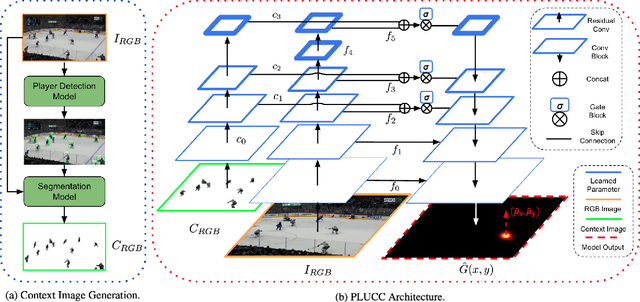

Puck detection in ice hockey broadcast videos poses significant challenges due to the puck's small size, frequent occlusions, motion blur, broadcast artifacts, and scale inconsistencies due to varying camera zoom and broadcast camera viewpoints. Prior works focus on appearance-based or motion-based cues of the puck without explicitly modelling the cues derived from player behaviour. Players consistently turn their bodies and direct their gaze toward the puck. Motivated by this strong contextual cue, we propose Puck Localization Using Contextual Cues (PLUCC), a novel approach for scale-aware and context-driven single-frame puck detections. PLUCC consists of three components: (a) a contextual encoder, which utilizes player orientations and positioning as helpful priors; (b) a feature pyramid encoder, which extracts multiscale features from the dual encoders; and (c) a gating decoder that combines latent features with a channel gating mechanism. For evaluation, in addition to standard average precision, we propose Rink Space Localization Error (RSLE), a scale-invariant homography-based metric for removing perspective bias from rink space evaluation. The experimental results of PLUCC on the PuckDataset dataset demonstrated state-of-the-art detection performance, surpassing previous baseline methods by an average precision improvement of 12.2% and RSLE average precision of 25%. Our research demonstrates the critical role of contextual understanding in improving puck detection performance, with broad implications for automated sports analysis.
SplatPose+: Real-time Image-Based Pose-Agnostic 3D Anomaly Detection
Oct 15, 2024



Image-based Pose-Agnostic 3D Anomaly Detection is an important task that has emerged in industrial quality control. This task seeks to find anomalies from query images of a tested object given a set of reference images of an anomaly-free object. The challenge is that the query views (a.k.a poses) are unknown and can be different from the reference views. Currently, new methods such as OmniposeAD and SplatPose have emerged to bridge the gap by synthesizing pseudo reference images at the query views for pixel-to-pixel comparison. However, none of these methods can infer in real-time, which is critical in industrial quality control for massive production. For this reason, we propose SplatPose+, which employs a hybrid representation consisting of a Structure from Motion (SfM) model for localization and a 3D Gaussian Splatting (3DGS) model for Novel View Synthesis. Although our proposed pipeline requires the computation of an additional SfM model, it offers real-time inference speeds and faster training compared to SplatPose. Quality-wise, we achieved a new SOTA on the Pose-agnostic Anomaly Detection benchmark with the Multi-Pose Anomaly Detection (MAD-SIM) dataset.
Inline Photometrically Calibrated Hybrid Visual SLAM
Sep 25, 2024



This paper presents an integrated approach to Visual SLAM, merging online sequential photometric calibration within a Hybrid direct-indirect visual SLAM (H-SLAM). Photometric calibration helps normalize pixel intensity values under different lighting conditions, and thereby improves the direct component of our H-SLAM. A tangential benefit also results to the indirect component of H-SLAM given that the detected features are more stable across variable lighting conditions. Our proposed photometrically calibrated H-SLAM is tested on several datasets, including the TUM monoVO as well as on a dataset we created. Calibrated H-SLAM outperforms other state of the art direct, indirect, and hybrid Visual SLAM systems in all the experiments. Furthermore, in online SLAM tested at our site, it also significantly outperformed the other SLAM Systems.
Towards Real-Time Gaussian Splatting: Accelerating 3DGS through Photometric SLAM
Aug 07, 2024Initial applications of 3D Gaussian Splatting (3DGS) in Visual Simultaneous Localization and Mapping (VSLAM) demonstrate the generation of high-quality volumetric reconstructions from monocular video streams. However, despite these promising advancements, current 3DGS integrations have reduced tracking performance and lower operating speeds compared to traditional VSLAM. To address these issues, we propose integrating 3DGS with Direct Sparse Odometry, a monocular photometric SLAM system. We have done preliminary experiments showing that using Direct Sparse Odometry point cloud outputs, as opposed to standard structure-from-motion methods, significantly shortens the training time needed to achieve high-quality renders. Reducing 3DGS training time enables the development of 3DGS-integrated SLAM systems that operate in real-time on mobile hardware. These promising initial findings suggest further exploration is warranted in combining traditional VSLAM systems with 3DGS.
Dense Monocular Motion Segmentation Using Optical Flow and Pseudo Depth Map: A Zero-Shot Approach
Jun 27, 2024



Motion segmentation from a single moving camera presents a significant challenge in the field of computer vision. This challenge is compounded by the unknown camera movements and the lack of depth information of the scene. While deep learning has shown impressive capabilities in addressing these issues, supervised models require extensive training on massive annotated datasets, and unsupervised models also require training on large volumes of unannotated data, presenting significant barriers for both. In contrast, traditional methods based on optical flow do not require training data, however, they often fail to capture object-level information, leading to over-segmentation or under-segmentation. In addition, they also struggle in complex scenes with substantial depth variations and non-rigid motion, due to the overreliance of optical flow. To overcome these challenges, we propose an innovative hybrid approach that leverages the advantages of both deep learning methods and traditional optical flow based methods to perform dense motion segmentation without requiring any training. Our method initiates by automatically generating object proposals for each frame using foundation models. These proposals are then clustered into distinct motion groups using both optical flow and relative depth maps as motion cues. The integration of depth maps derived from state-of-the-art monocular depth estimation models significantly enhances the motion cues provided by optical flow, particularly in handling motion parallax issues. Our method is evaluated on the DAVIS-Moving and YTVOS-Moving datasets, and the results demonstrate that our method outperforms the best unsupervised method and closely matches with the state-of-theart supervised methods.
* For the offical publication, see https://crv.pubpub.org/pub/iunjzl55
Zero-Shot Monocular Motion Segmentation in the Wild by Combining Deep Learning with Geometric Motion Model Fusion
May 02, 2024Detecting and segmenting moving objects from a moving monocular camera is challenging in the presence of unknown camera motion, diverse object motions and complex scene structures. Most existing methods rely on a single motion cue to perform motion segmentation, which is usually insufficient when facing different complex environments. While a few recent deep learning based methods are able to combine multiple motion cues to achieve improved accuracy, they depend heavily on vast datasets and extensive annotations, making them less adaptable to new scenarios. To address these limitations, we propose a novel monocular dense segmentation method that achieves state-of-the-art motion segmentation results in a zero-shot manner. The proposed method synergestically combines the strengths of deep learning and geometric model fusion methods by performing geometric model fusion on object proposals. Experiments show that our method achieves competitive results on several motion segmentation datasets and even surpasses some state-of-the-art supervised methods on certain benchmarks, while not being trained on any data. We also present an ablation study to show the effectiveness of combining different geometric models together for motion segmentation, highlighting the value of our geometric model fusion strategy.
Domain-Guided Masked Autoencoders for Unique Player Identification
Mar 17, 2024
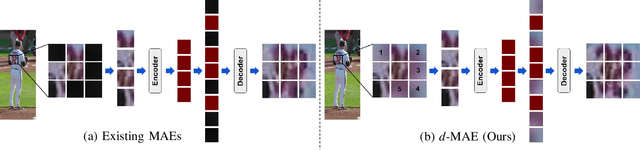
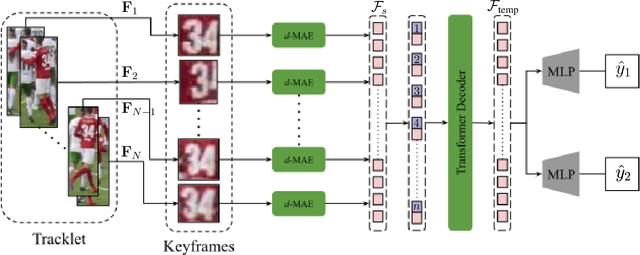

Unique player identification is a fundamental module in vision-driven sports analytics. Identifying players from broadcast videos can aid with various downstream tasks such as player assessment, in-game analysis, and broadcast production. However, automatic detection of jersey numbers using deep features is challenging primarily due to: a) motion blur, b) low resolution video feed, and c) occlusions. With their recent success in various vision tasks, masked autoencoders (MAEs) have emerged as a superior alternative to conventional feature extractors. However, most MAEs simply zero-out image patches either randomly or focus on where to mask rather than how to mask. Motivated by human vision, we devise a novel domain-guided masking policy for MAEs termed d-MAE to facilitate robust feature extraction in the presence of motion blur for player identification. We further introduce a new spatio-temporal network leveraging our novel d-MAE for unique player identification. We conduct experiments on three large-scale sports datasets, including a curated baseball dataset, the SoccerNet dataset, and an in-house ice hockey dataset. We preprocess the datasets using an upgraded keyframe identification (KfID) module by focusing on frames containing jersey numbers. Additionally, we propose a keyframe-fusion technique to augment keyframes, preserving spatial and temporal context. Our spatio-temporal network showcases significant improvements, surpassing the current state-of-the-art by 8.58%, 4.29%, and 1.20% in the test set accuracies, respectively. Rigorous ablations highlight the effectiveness of our domain-guided masking approach and the refined KfID module, resulting in performance enhancements of 1.48% and 1.84% respectively, compared to original architectures.