 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLangDA: Building Context-Awareness via Language for Domain Adaptive Semantic Segmentation
Mar 17, 2025Unsupervised domain adaptation for semantic segmentation (DASS) aims to transfer knowledge from a label-rich source domain to a target domain with no labels. Two key approaches in DASS are (1) vision-only approaches using masking or multi-resolution crops, and (2) language-based approaches that use generic class-wise prompts informed by target domain (e.g. "a {snowy} photo of a {class}"). However, the former is susceptible to noisy pseudo-labels that are biased to the source domain. The latter does not fully capture the intricate spatial relationships of objects -- key for dense prediction tasks. To this end, we propose LangDA. LangDA addresses these challenges by, first, learning contextual relationships between objects via VLM-generated scene descriptions (e.g. "a pedestrian is on the sidewalk, and the street is lined with buildings."). Second, LangDA aligns the entire image features with text representation of this context-aware scene caption and learns generalized representations via text. With this, LangDA sets the new state-of-the-art across three DASS benchmarks, outperforming existing methods by 2.6%, 1.4% and 3.9%.
PitcherNet: Powering the Moneyball Evolution in Baseball Video Analytics
May 13, 2024
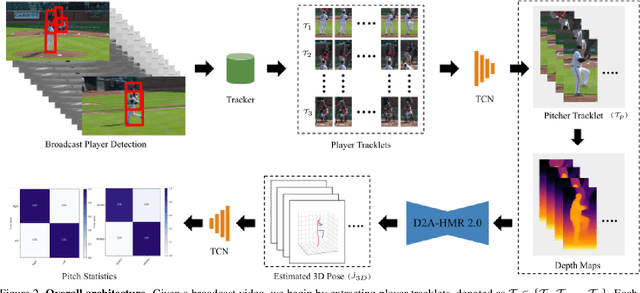
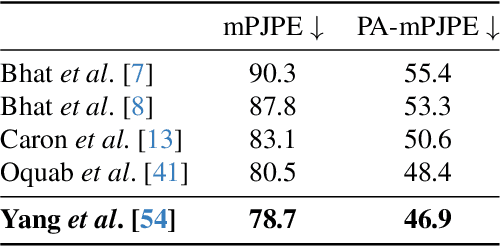
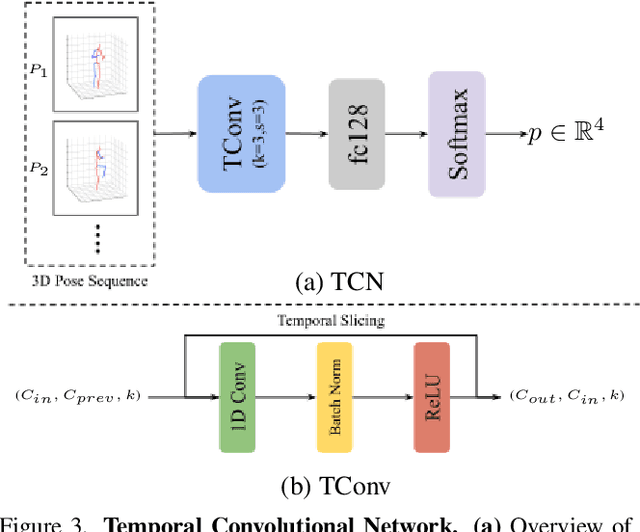
In the high-stakes world of baseball, every nuance of a pitcher's mechanics holds the key to maximizing performance and minimizing runs. Traditional analysis methods often rely on pre-recorded offline numerical data, hindering their application in the dynamic environment of live games. Broadcast video analysis, while seemingly ideal, faces significant challenges due to factors like motion blur and low resolution. To address these challenges, we introduce PitcherNet, an end-to-end automated system that analyzes pitcher kinematics directly from live broadcast video, thereby extracting valuable pitch statistics including velocity, release point, pitch position, and release extension. This system leverages three key components: (1) Player tracking and identification by decoupling actions from player kinematics; (2) Distribution and depth-aware 3D human modeling; and (3) Kinematic-driven pitch statistics. Experimental validation demonstrates that PitcherNet achieves robust analysis results with 96.82% accuracy in pitcher tracklet identification, reduced joint position error by 1.8mm and superior analytics compared to baseline methods. By enabling performance-critical kinematic analysis from broadcast video, PitcherNet paves the way for the future of baseball analytics by optimizing pitching strategies, preventing injuries, and unlocking a deeper understanding of pitcher mechanics, forever transforming the game.
Domain-Guided Masked Autoencoders for Unique Player Identification
Mar 17, 2024
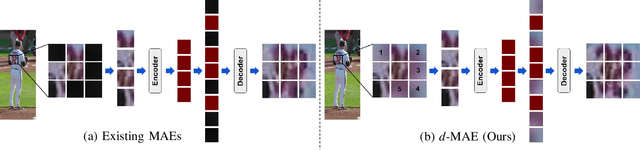
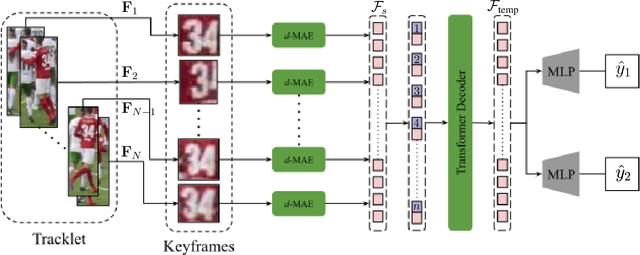

Unique player identification is a fundamental module in vision-driven sports analytics. Identifying players from broadcast videos can aid with various downstream tasks such as player assessment, in-game analysis, and broadcast production. However, automatic detection of jersey numbers using deep features is challenging primarily due to: a) motion blur, b) low resolution video feed, and c) occlusions. With their recent success in various vision tasks, masked autoencoders (MAEs) have emerged as a superior alternative to conventional feature extractors. However, most MAEs simply zero-out image patches either randomly or focus on where to mask rather than how to mask. Motivated by human vision, we devise a novel domain-guided masking policy for MAEs termed d-MAE to facilitate robust feature extraction in the presence of motion blur for player identification. We further introduce a new spatio-temporal network leveraging our novel d-MAE for unique player identification. We conduct experiments on three large-scale sports datasets, including a curated baseball dataset, the SoccerNet dataset, and an in-house ice hockey dataset. We preprocess the datasets using an upgraded keyframe identification (KfID) module by focusing on frames containing jersey numbers. Additionally, we propose a keyframe-fusion technique to augment keyframes, preserving spatial and temporal context. Our spatio-temporal network showcases significant improvements, surpassing the current state-of-the-art by 8.58%, 4.29%, and 1.20% in the test set accuracies, respectively. Rigorous ablations highlight the effectiveness of our domain-guided masking approach and the refined KfID module, resulting in performance enhancements of 1.48% and 1.84% respectively, compared to original architectures.
Distribution and Depth-Aware Transformers for 3D Human Mesh Recovery
Mar 14, 2024



Precise Human Mesh Recovery (HMR) with in-the-wild data is a formidable challenge and is often hindered by depth ambiguities and reduced precision. Existing works resort to either pose priors or multi-modal data such as multi-view or point cloud information, though their methods often overlook the valuable scene-depth information inherently present in a single image. Moreover, achieving robust HMR for out-of-distribution (OOD) data is exceedingly challenging due to inherent variations in pose, shape and depth. Consequently, understanding the underlying distribution becomes a vital subproblem in modeling human forms. Motivated by the need for unambiguous and robust human modeling, we introduce Distribution and depth-aware human mesh recovery (D2A-HMR), an end-to-end transformer architecture meticulously designed to minimize the disparity between distributions and incorporate scene-depth leveraging prior depth information. Our approach demonstrates superior performance in handling OOD data in certain scenarios while consistently achieving competitive results against state-of-the-art HMR methods on controlled datasets.
Jersey Number Recognition using Keyframe Identification from Low-Resolution Broadcast Videos
Sep 12, 2023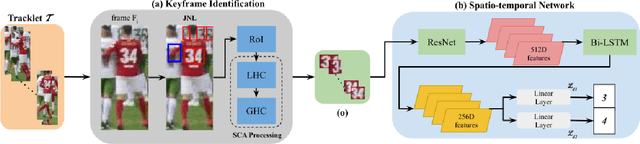

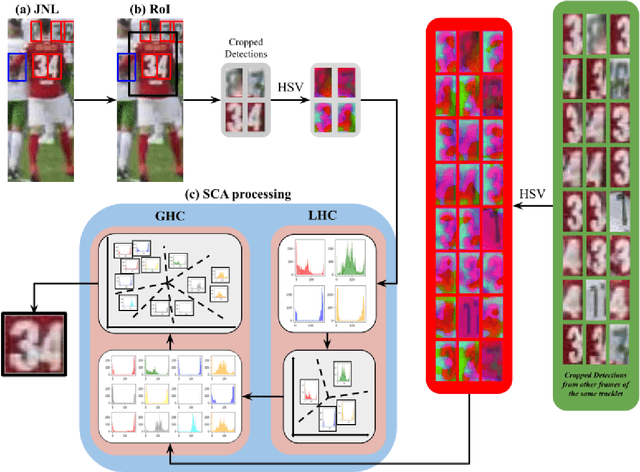

Player identification is a crucial component in vision-driven soccer analytics, enabling various downstream tasks such as player assessment, in-game analysis, and broadcast production. However, automatically detecting jersey numbers from player tracklets in videos presents challenges due to motion blur, low resolution, distortions, and occlusions. Existing methods, utilizing Spatial Transformer Networks, CNNs, and Vision Transformers, have shown success in image data but struggle with real-world video data, where jersey numbers are not visible in most of the frames. Hence, identifying frames that contain the jersey number is a key sub-problem to tackle. To address these issues, we propose a robust keyframe identification module that extracts frames containing essential high-level information about the jersey number. A spatio-temporal network is then employed to model spatial and temporal context and predict the probabilities of jersey numbers in the video. Additionally, we adopt a multi-task loss function to predict the probability distribution of each digit separately. Extensive evaluations on the SoccerNet dataset demonstrate that incorporating our proposed keyframe identification module results in a significant 37.81% and 37.70% increase in the accuracies of 2 different test sets with domain gaps. These results highlight the effectiveness and importance of our approach in tackling the challenges of automatic jersey number detection in sports videos.