 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLangDA: Building Context-Awareness via Language for Domain Adaptive Semantic Segmentation
Mar 17, 2025Unsupervised domain adaptation for semantic segmentation (DASS) aims to transfer knowledge from a label-rich source domain to a target domain with no labels. Two key approaches in DASS are (1) vision-only approaches using masking or multi-resolution crops, and (2) language-based approaches that use generic class-wise prompts informed by target domain (e.g. "a {snowy} photo of a {class}"). However, the former is susceptible to noisy pseudo-labels that are biased to the source domain. The latter does not fully capture the intricate spatial relationships of objects -- key for dense prediction tasks. To this end, we propose LangDA. LangDA addresses these challenges by, first, learning contextual relationships between objects via VLM-generated scene descriptions (e.g. "a pedestrian is on the sidewalk, and the street is lined with buildings."). Second, LangDA aligns the entire image features with text representation of this context-aware scene caption and learns generalized representations via text. With this, LangDA sets the new state-of-the-art across three DASS benchmarks, outperforming existing methods by 2.6%, 1.4% and 3.9%.
Is Generative Modeling-based Stylization Necessary for Domain Adaptation in Regression Tasks?
Jun 02, 2023Unsupervised domain adaptation (UDA) aims to bridge the gap between source and target domains in the absence of target domain labels using two main techniques: input-level alignment (such as generative modeling and stylization) and feature-level alignment (which matches the distribution of the feature maps, e.g. gradient reversal layers). Motivated from the success of generative modeling for image classification, stylization-based methods were recently proposed for regression tasks, such as pose estimation. However, use of input-level alignment via generative modeling and stylization incur additional overhead and computational complexity which limit their use in real-world DA tasks. To investigate the role of input-level alignment for DA, we ask the following question: Is generative modeling-based stylization necessary for visual domain adaptation in regression? Surprisingly, we find that input-alignment has little effect on regression tasks as compared to classification. Based on these insights, we develop a non-parametric feature-level domain alignment method -- Implicit Stylization (ImSty) -- which results in consistent improvements over SOTA regression task, without the need for computationally intensive stylization and generative modeling. Our work conducts a critical evaluation of the role of generative modeling and stylization, at a time when these are also gaining popularity for domain generalization.
Domain Generalization for Domain-Linked Classes
Jun 01, 2023



Domain generalization (DG) focuses on transferring domain-invariant knowledge from multiple source domains (available at train time) to an, a priori, unseen target domain(s). This requires a class to be expressed in multiple domains for the learning algorithm to break the spurious correlations between domain and class. However, in the real-world, classes may often be domain-linked, i.e. expressed only in a specific domain, which leads to extremely poor generalization performance for these classes. In this work, we aim to learn generalizable representations for these domain-linked classes by transferring domain-invariant knowledge from classes expressed in multiple source domains (domain-shared classes). To this end, we introduce this task to the community and propose a Fair and cONtrastive feature-space regularization algorithm for Domain-linked DG, FOND. Rigorous and reproducible experiments with baselines across popular DG tasks demonstrate our method and its variants' ability to accomplish state-of-the-art DG results for domain-linked classes. We also provide practical insights on data conditions that increase domain-linked class generalizability to tackle real-world data scarcity.
Building Spatio-temporal Transformers for Egocentric 3D Pose Estimation
Jun 09, 2022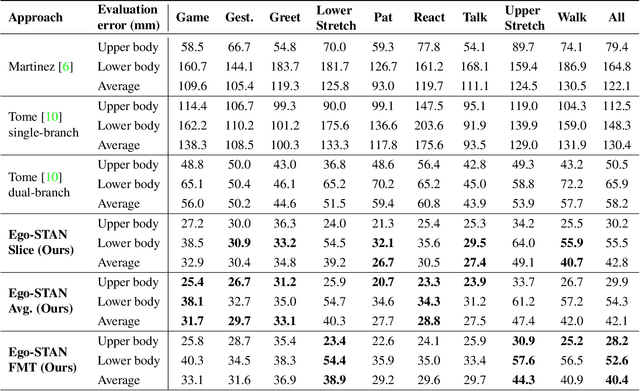
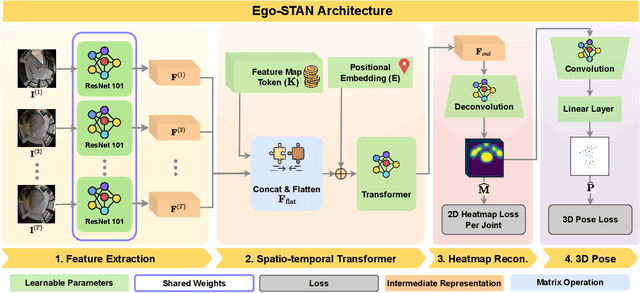
Egocentric 3D human pose estimation (HPE) from images is challenging due to severe self-occlusions and strong distortion introduced by the fish-eye view from the head mounted camera. Although existing works use intermediate heatmap-based representations to counter distortion with some success, addressing self-occlusion remains an open problem. In this work, we leverage information from past frames to guide our self-attention-based 3D HPE estimation procedure -- Ego-STAN. Specifically, we build a spatio-temporal Transformer model that attends to semantically rich convolutional neural network-based feature maps. We also propose feature map tokens: a new set of learnable parameters to attend to these feature maps. Finally, we demonstrate Ego-STAN's superior performance on the xR-EgoPose dataset where it achieves a 30.6% improvement on the overall mean per-joint position error, while leading to a 22% drop in parameters compared to the state-of-the-art.