 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEPNet: An Efficient Pyramid Network for Enhanced Single-Image Super-Resolution with Reduced Computational Requirements
Dec 20, 2023Single-image super-resolution (SISR) has seen significant advancements through the integration of deep learning. However, the substantial computational and memory requirements of existing methods often limit their practical application. This paper introduces a new Efficient Pyramid Network (EPNet) that harmoniously merges an Edge Split Pyramid Module (ESPM) with a Panoramic Feature Extraction Module (PFEM) to overcome the limitations of existing methods, particularly in terms of computational efficiency. The ESPM applies a pyramid-based channel separation strategy, boosting feature extraction while maintaining computational efficiency. The PFEM, a novel fusion of CNN and Transformer structures, enables the concurrent extraction of local and global features, thereby providing a panoramic view of the image landscape. Our architecture integrates the PFEM in a manner that facilitates the streamlined exchange of feature information and allows for the further refinement of image texture details. Experimental results indicate that our model outperforms existing state-of-the-art methods in image resolution quality, while considerably decreasing computational and memory costs. This research contributes to the ongoing evolution of efficient and practical SISR methodologies, bearing broader implications for the field of computer vision.
Is Generative Modeling-based Stylization Necessary for Domain Adaptation in Regression Tasks?
Jun 02, 2023Unsupervised domain adaptation (UDA) aims to bridge the gap between source and target domains in the absence of target domain labels using two main techniques: input-level alignment (such as generative modeling and stylization) and feature-level alignment (which matches the distribution of the feature maps, e.g. gradient reversal layers). Motivated from the success of generative modeling for image classification, stylization-based methods were recently proposed for regression tasks, such as pose estimation. However, use of input-level alignment via generative modeling and stylization incur additional overhead and computational complexity which limit their use in real-world DA tasks. To investigate the role of input-level alignment for DA, we ask the following question: Is generative modeling-based stylization necessary for visual domain adaptation in regression? Surprisingly, we find that input-alignment has little effect on regression tasks as compared to classification. Based on these insights, we develop a non-parametric feature-level domain alignment method -- Implicit Stylization (ImSty) -- which results in consistent improvements over SOTA regression task, without the need for computationally intensive stylization and generative modeling. Our work conducts a critical evaluation of the role of generative modeling and stylization, at a time when these are also gaining popularity for domain generalization.
Building Spatio-temporal Transformers for Egocentric 3D Pose Estimation
Jun 09, 2022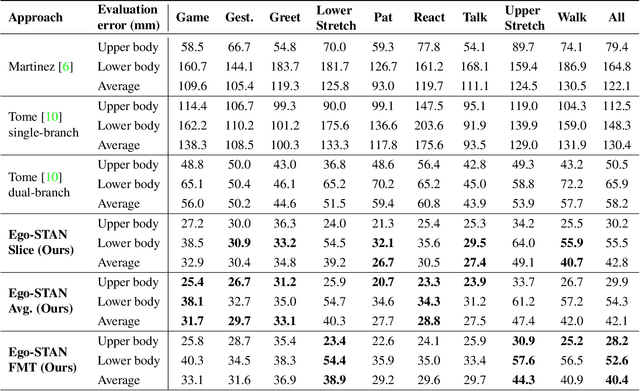
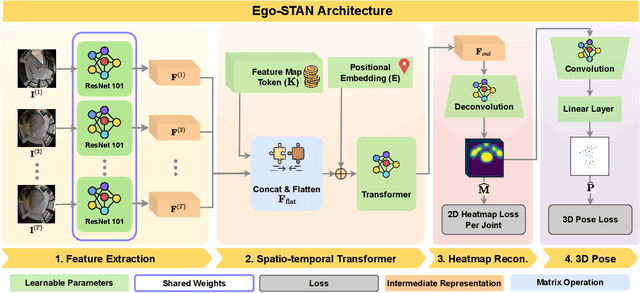
Egocentric 3D human pose estimation (HPE) from images is challenging due to severe self-occlusions and strong distortion introduced by the fish-eye view from the head mounted camera. Although existing works use intermediate heatmap-based representations to counter distortion with some success, addressing self-occlusion remains an open problem. In this work, we leverage information from past frames to guide our self-attention-based 3D HPE estimation procedure -- Ego-STAN. Specifically, we build a spatio-temporal Transformer model that attends to semantically rich convolutional neural network-based feature maps. We also propose feature map tokens: a new set of learnable parameters to attend to these feature maps. Finally, we demonstrate Ego-STAN's superior performance on the xR-EgoPose dataset where it achieves a 30.6% improvement on the overall mean per-joint position error, while leading to a 22% drop in parameters compared to the state-of-the-art.