 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding Spatio-temporal Transformers for Egocentric 3D Pose Estimation
Paper and Code
Jun 09, 2022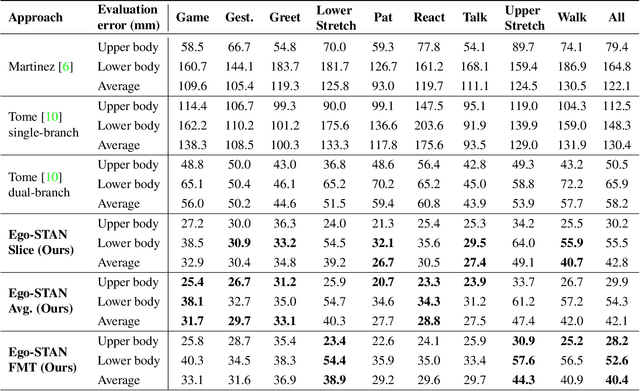
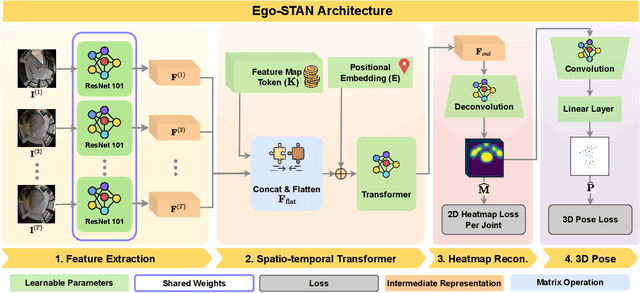
Egocentric 3D human pose estimation (HPE) from images is challenging due to severe self-occlusions and strong distortion introduced by the fish-eye view from the head mounted camera. Although existing works use intermediate heatmap-based representations to counter distortion with some success, addressing self-occlusion remains an open problem. In this work, we leverage information from past frames to guide our self-attention-based 3D HPE estimation procedure -- Ego-STAN. Specifically, we build a spatio-temporal Transformer model that attends to semantically rich convolutional neural network-based feature maps. We also propose feature map tokens: a new set of learnable parameters to attend to these feature maps. Finally, we demonstrate Ego-STAN's superior performance on the xR-EgoPose dataset where it achieves a 30.6% improvement on the overall mean per-joint position error, while leading to a 22% drop in parameters compared to the state-of-the-art.