 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTamperBench: Systematically Stress-Testing LLM Safety Under Fine-Tuning and Tampering
Feb 06, 2026As increasingly capable open-weight large language models (LLMs) are deployed, improving their tamper resistance against unsafe modifications, whether accidental or intentional, becomes critical to minimize risks. However, there is no standard approach to evaluate tamper resistance. Varied data sets, metrics, and tampering configurations make it difficult to compare safety, utility, and robustness across different models and defenses. To this end, we introduce TamperBench, the first unified framework to systematically evaluate the tamper resistance of LLMs. TamperBench (i) curates a repository of state-of-the-art weight-space fine-tuning attacks and latent-space representation attacks; (ii) enables realistic adversarial evaluation through systematic hyperparameter sweeps per attack-model pair; and (iii) provides both safety and utility evaluations. TamperBench requires minimal additional code to specify any fine-tuning configuration, alignment-stage defense method, and metric suite while ensuring end-to-end reproducibility. We use TamperBench to evaluate 21 open-weight LLMs, including defense-augmented variants, across nine tampering threats using standardized safety and capability metrics with hyperparameter sweeps per model-attack pair. This yields novel insights, including effects of post-training on tamper resistance, that jailbreak-tuning is typically the most severe attack, and that Triplet emerges as a leading alignment-stage defense. Code is available at: https://github.com/criticalml-uw/TamperBench
Avatar4D: Synthesizing Domain-Specific 4D Humans for Real-World Pose Estimation
Dec 18, 2025We present Avatar4D, a real-world transferable pipeline for generating customizable synthetic human motion datasets tailored to domain-specific applications. Unlike prior works, which focus on general, everyday motions and offer limited flexibility, our approach provides fine-grained control over body pose, appearance, camera viewpoint, and environmental context, without requiring any manual annotations. To validate the impact of Avatar4D, we focus on sports, where domain-specific human actions and movement patterns pose unique challenges for motion understanding. In this setting, we introduce Syn2Sport, a large-scale synthetic dataset spanning sports, including baseball and ice hockey. Avatar4D features high-fidelity 4D (3D geometry over time) human motion sequences with varying player appearances rendered in diverse environments. We benchmark several state-of-the-art pose estimation models on Syn2Sport and demonstrate their effectiveness for supervised learning, zero-shot transfer to real-world data, and generalization across sports. Furthermore, we evaluate how closely the generated synthetic data aligns with real-world datasets in feature space. Our results highlight the potential of such systems to generate scalable, controllable, and transferable human datasets for diverse domain-specific tasks without relying on domain-specific real data.
Randomized Gradient Subspaces for Efficient Large Language Model Training
Oct 02, 2025Training large language models (LLMs) is often bottlenecked by extreme memory demands, with optimizer states dominating the footprint. Recent works mitigates this cost by projecting gradients into low-dimensional subspaces using sophisticated update strategies. In this paper, we analyze the dynamics of gradient space and its underlying subspaces. We find that while a small subspace captures most gradient energy, a significant portion still resides in the residual bulk; moreover, the influence of the core subspace diminishes over time and in deeper layers. We also observe that the gradient space exhibits near-flat curvature, calling for algorithms that explicitly account for this geometry. Motivated by these insights, we introduce a suite of randomized algorithms, GrassWalk and GrassJump, which exploit subspace and achieve state-of-the-art memory savings while improving performance on LLaMA-1B and LLaMA-7B pretraining.
Estimating Quality in Therapeutic Conversations: A Multi-Dimensional Natural Language Processing Framework
May 09, 2025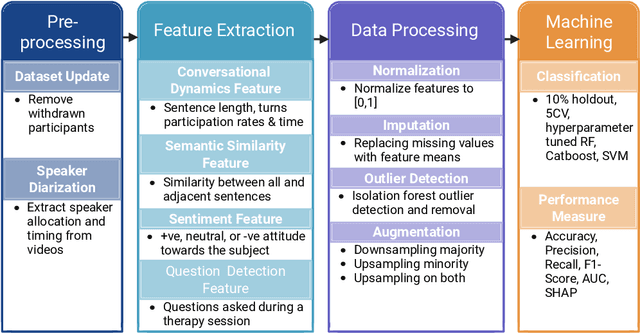
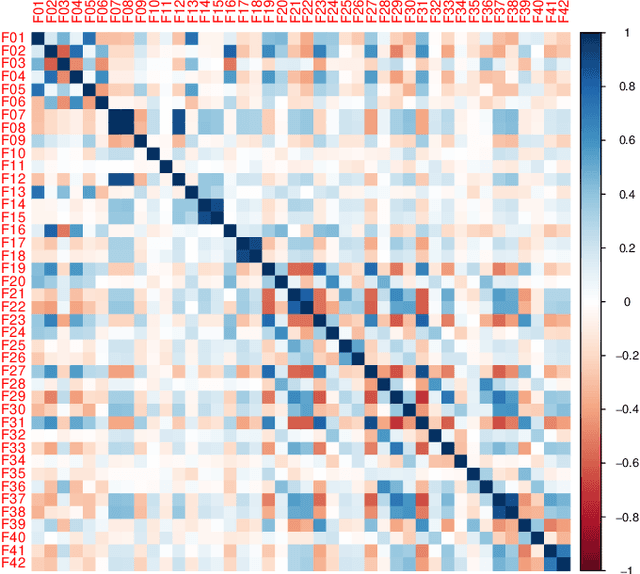
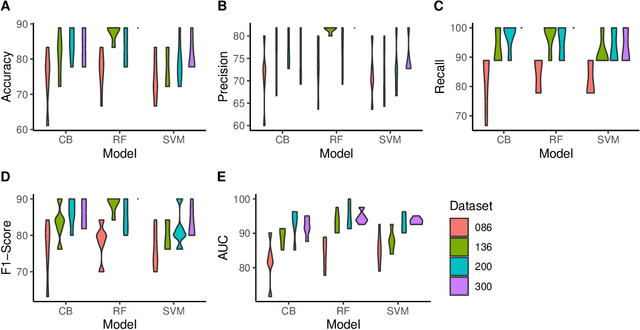
Engagement between client and therapist is a critical determinant of therapeutic success. We propose a multi-dimensional natural language processing (NLP) framework that objectively classifies engagement quality in counseling sessions based on textual transcripts. Using 253 motivational interviewing transcripts (150 high-quality, 103 low-quality), we extracted 42 features across four domains: conversational dynamics, semantic similarity as topic alignment, sentiment classification, and question detection. Classifiers, including Random Forest (RF), Cat-Boost, and Support Vector Machines (SVM), were hyperparameter tuned and trained using a stratified 5-fold cross-validation and evaluated on a holdout test set. On balanced (non-augmented) data, RF achieved the highest classification accuracy (76.7%), and SVM achieved the highest AUC (85.4%). After SMOTE-Tomek augmentation, performance improved significantly: RF achieved up to 88.9% accuracy, 90.0% F1-score, and 94.6% AUC, while SVM reached 81.1% accuracy, 83.1% F1-score, and 93.6% AUC. The augmented data results reflect the potential of the framework in future larger-scale applications. Feature contribution revealed conversational dynamics and semantic similarity between clients and therapists were among the top contributors, led by words uttered by the client (mean and standard deviation). The framework was robust across the original and augmented datasets and demonstrated consistent improvements in F1 scores and recall. While currently text-based, the framework supports future multimodal extensions (e.g., vocal tone, facial affect) for more holistic assessments. This work introduces a scalable, data-driven method for evaluating engagement quality of the therapy session, offering clinicians real-time feedback to enhance the quality of both virtual and in-person therapeutic interactions.
Understanding LLM Scientific Reasoning through Promptings and Model's Explanation on the Answers
May 02, 2025Large language models (LLMs) have demonstrated remarkable capabilities in natural language understanding, reasoning, and problem-solving across various domains. However, their ability to perform complex, multi-step reasoning task-essential for applications in science, medicine, and law-remains an area of active investigation. This paper examines the reasoning capabilities of contemporary LLMs, analyzing their strengths, limitations, and potential for improvement. The study uses prompt engineering techniques on the Graduate-Level GoogleProof Q&A (GPQA) dataset to assess the scientific reasoning of GPT-4o. Five popular prompt engineering techniques and two tailored promptings were tested: baseline direct answer (zero-shot), chain-of-thought (CoT), zero-shot CoT, self-ask, self-consistency, decomposition, and multipath promptings. Our findings indicate that while LLMs exhibit emergent reasoning abilities, they often rely on pattern recognition rather than true logical inference, leading to inconsistencies in complex problem-solving. The results indicated that self-consistency outperformed the other prompt engineering technique with an accuracy of 52.99%, followed by direct answer (52.23%). Zero-shot CoT (50%) outperformed multipath (48.44%), decomposition (47.77%), self-ask (46.88%), and CoT (43.75%). Self-consistency performed the second worst in explaining the answers. Simple techniques such as direct answer, CoT, and zero-shot CoT have the best scientific reasoning. We propose a research agenda aimed at bridging these gaps by integrating structured reasoning frameworks, hybrid AI approaches, and human-in-the-loop methodologies. By critically evaluating the reasoning mechanisms of LLMs, this paper contributes to the ongoing discourse on the future of artificial general intelligence and the development of more robust, trustworthy AI systems.
LOCATEdit: Graph Laplacian Optimized Cross Attention for Localized Text-Guided Image Editing
Mar 27, 2025Text-guided image editing aims to modify specific regions of an image according to natural language instructions while maintaining the general structure and the background fidelity. Existing methods utilize masks derived from cross-attention maps generated from diffusion models to identify the target regions for modification. However, since cross-attention mechanisms focus on semantic relevance, they struggle to maintain the image integrity. As a result, these methods often lack spatial consistency, leading to editing artifacts and distortions. In this work, we address these limitations and introduce LOCATEdit, which enhances cross-attention maps through a graph-based approach utilizing self-attention-derived patch relationships to maintain smooth, coherent attention across image regions, ensuring that alterations are limited to the designated items while retaining the surrounding structure. \method consistently and substantially outperforms existing baselines on PIE-Bench, demonstrating its state-of-the-art performance and effectiveness on various editing tasks. Code can be found on https://github.com/LOCATEdit/LOCATEdit/
LangDA: Building Context-Awareness via Language for Domain Adaptive Semantic Segmentation
Mar 17, 2025Unsupervised domain adaptation for semantic segmentation (DASS) aims to transfer knowledge from a label-rich source domain to a target domain with no labels. Two key approaches in DASS are (1) vision-only approaches using masking or multi-resolution crops, and (2) language-based approaches that use generic class-wise prompts informed by target domain (e.g. "a {snowy} photo of a {class}"). However, the former is susceptible to noisy pseudo-labels that are biased to the source domain. The latter does not fully capture the intricate spatial relationships of objects -- key for dense prediction tasks. To this end, we propose LangDA. LangDA addresses these challenges by, first, learning contextual relationships between objects via VLM-generated scene descriptions (e.g. "a pedestrian is on the sidewalk, and the street is lined with buildings."). Second, LangDA aligns the entire image features with text representation of this context-aware scene caption and learns generalized representations via text. With this, LangDA sets the new state-of-the-art across three DASS benchmarks, outperforming existing methods by 2.6%, 1.4% and 3.9%.
SubTrack your Grad: Gradient Subspace Tracking for Memory and Time Efficient Full-Parameter LLM Training
Feb 03, 2025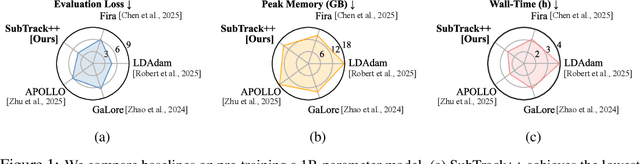
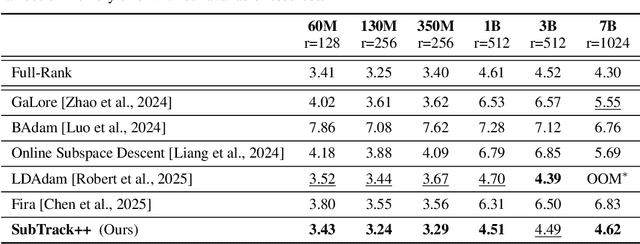
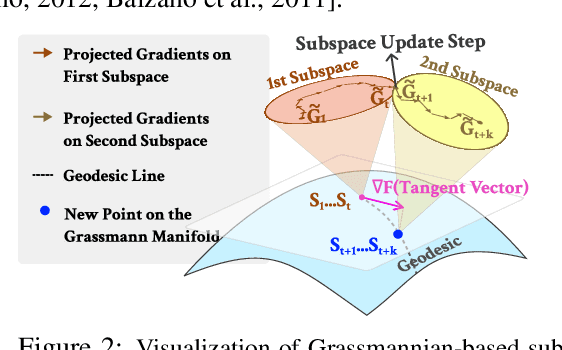
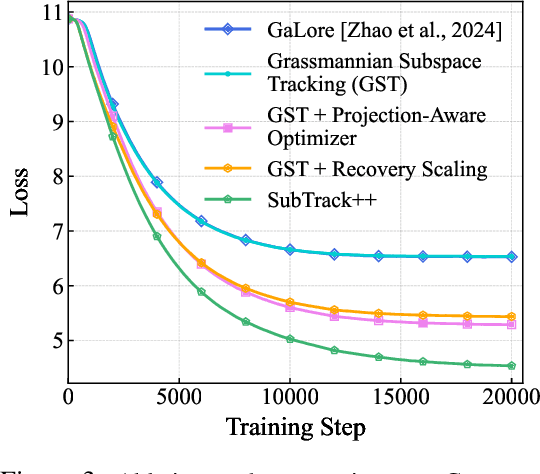
Training Large Language Models (LLMs) demand significant time and computational resources due to their large model sizes and optimizer states. To overcome these challenges, recent methods, such as BAdam, employ partial weight updates to enhance time and memory efficiency, though sometimes at the cost of performance. Others, like GaLore, focus on maintaining performance while optimizing memory usage through full parameter training, but may incur higher time complexity. By leveraging the low-rank structure of the gradient and the Grassmannian geometry, we propose SubTrack-Grad, a subspace tracking-based optimization method that efficiently tracks the evolving gradient subspace by incorporating estimation errors and previously identified subspaces. SubTrack-Grad delivers better or on-par results compared to GaLore, while significantly outperforming BAdam, which, despite being time-efficient, compromises performance. SubTrack-Grad reduces wall-time by up to 20.57% on GLUE tasks (15% average reduction) and up to 65% on SuperGLUE tasks (22% average reduction) compared to GaLore. Notably, for a 3B parameter model, GaLore incurred a substantial 157% increase in wall-time compared to full-rank training, whereas SubTrack-Grad exhibited a 31% increase, representing a 49% reduction in wall-time, while enjoying the same memory reductions as GaLore.
Domain-Guided Masked Autoencoders for Unique Player Identification
Mar 17, 2024
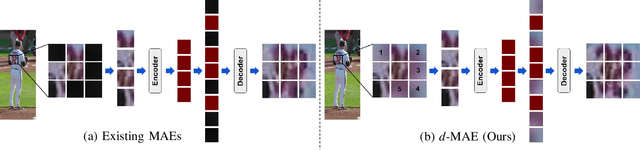
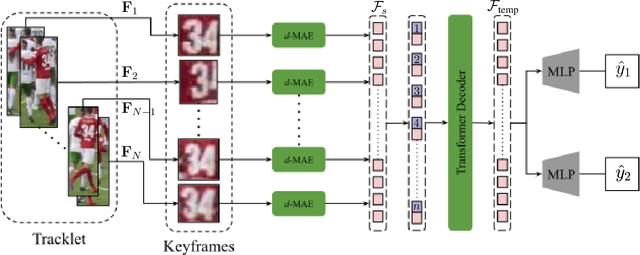

Unique player identification is a fundamental module in vision-driven sports analytics. Identifying players from broadcast videos can aid with various downstream tasks such as player assessment, in-game analysis, and broadcast production. However, automatic detection of jersey numbers using deep features is challenging primarily due to: a) motion blur, b) low resolution video feed, and c) occlusions. With their recent success in various vision tasks, masked autoencoders (MAEs) have emerged as a superior alternative to conventional feature extractors. However, most MAEs simply zero-out image patches either randomly or focus on where to mask rather than how to mask. Motivated by human vision, we devise a novel domain-guided masking policy for MAEs termed d-MAE to facilitate robust feature extraction in the presence of motion blur for player identification. We further introduce a new spatio-temporal network leveraging our novel d-MAE for unique player identification. We conduct experiments on three large-scale sports datasets, including a curated baseball dataset, the SoccerNet dataset, and an in-house ice hockey dataset. We preprocess the datasets using an upgraded keyframe identification (KfID) module by focusing on frames containing jersey numbers. Additionally, we propose a keyframe-fusion technique to augment keyframes, preserving spatial and temporal context. Our spatio-temporal network showcases significant improvements, surpassing the current state-of-the-art by 8.58%, 4.29%, and 1.20% in the test set accuracies, respectively. Rigorous ablations highlight the effectiveness of our domain-guided masking approach and the refined KfID module, resulting in performance enhancements of 1.48% and 1.84% respectively, compared to original architectures.
Is Generative Modeling-based Stylization Necessary for Domain Adaptation in Regression Tasks?
Jun 02, 2023Unsupervised domain adaptation (UDA) aims to bridge the gap between source and target domains in the absence of target domain labels using two main techniques: input-level alignment (such as generative modeling and stylization) and feature-level alignment (which matches the distribution of the feature maps, e.g. gradient reversal layers). Motivated from the success of generative modeling for image classification, stylization-based methods were recently proposed for regression tasks, such as pose estimation. However, use of input-level alignment via generative modeling and stylization incur additional overhead and computational complexity which limit their use in real-world DA tasks. To investigate the role of input-level alignment for DA, we ask the following question: Is generative modeling-based stylization necessary for visual domain adaptation in regression? Surprisingly, we find that input-alignment has little effect on regression tasks as compared to classification. Based on these insights, we develop a non-parametric feature-level domain alignment method -- Implicit Stylization (ImSty) -- which results in consistent improvements over SOTA regression task, without the need for computationally intensive stylization and generative modeling. Our work conducts a critical evaluation of the role of generative modeling and stylization, at a time when these are also gaining popularity for domain generalization.