 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Little Rank Goes a Long Way: Random Scaffolds with LoRA Adapters Are All You Need
Apr 13, 2026How many of a neural network's parameters actually encode task-specific information? We investigate this question with LottaLoRA, a training paradigm in which every backbone weight is drawn at random and frozen; only low-rank LoRA adapters are trained. Across nine benchmarks spanning diverse architecture families from single-layer classifiers to 900M parameter Transformers low-rank adapters over frozen random backbones recover 96-100% of fully trained performance while training only 0.5-40% of the parameters. The task-specific signal therefore occupies a subspace orders of magnitude smaller than the full parameter count suggests. Three mechanistic findings underpin this result:(1) the frozen backbone is actively exploited when static the learned scaling~$β$ remains strictly positive across all architectures but when the scaffold is destabilized, the optimizer silences it and the LoRA factors absorb all task information; (2) the frozen backbone is preferable but interchangeable any random initialization works equally well, provided it remains fixed throughout training; and (3) the minimum LoRA rank at which performance saturates estimates the intrinsic dimensionality of the task, reminiscent of the number of components retained in Principal Component Analysis (PCA). The construction is formally analogous to Reservoir Computing unfolded along the depth axis of a feedforward network. Because the backbone is determined by a random seed alone, models can be distributed as adapters plus seed a footprint that grows with task complexity, not model size, so that storage and memory savings compound as architectures scale.
Scribe Verification in Chinese manuscripts using Siamese, Triplet, and Vision Transformer Neural Networks
Mar 14, 2026The paper examines deep learning models for scribe verification in Chinese manuscripts. That is, to automatically determine whether two manuscript fragments were written by the same scribe using deep metric learning methods. Two datasets were used: the Tsinghua Bamboo Slips Dataset and a selected subset of the Multi-Attribute Chinese Calligraphy Dataset, focusing on the calligraphers with a large number of samples. Siamese and Triplet neural network architectures are implemented, including convolutional and Transformer-based models. The experimental results show that the MobileNetV3+ Custom Siamese model trained with contrastive loss achieves either the best or the second-best overall accuracy and area under the Receiver Operating Characteristic Curve on both datasets.
Specializing Foundation Models via Mixture of Low-Rank Experts for Comprehensive Head CT Analysis
Feb 28, 2026Foundation models pre-trained on large-scale datasets demonstrate strong transfer learning capabilities; however, their adaptation to complex multi-label diagnostic tasks-such as comprehensive head CT finding detection-remains understudied. Standard parameter-efficient fine-tuning methods such as LoRA apply uniform adaptations across pathology types, which may limit performance for diverse medical findings. We propose a Mixture of Low-Rank Experts (MoLRE) framework that extends LoRA with multiple specialized low-rank adapters and unsupervised soft routing. This approach enables conditional feature adaptation with less than 0.5% additional parameters and without explicit pathology supervision. We present a comprehensive benchmark of MoLRE across six state-of-the-art medical imaging foundation models spanning 2D and 3D architectures, general-domain, medical-domain, and head CT-specific pretraining, and model sizes ranging from 7M to 431M parameters. Using over 70,000 non-contrast head CT scans with 75 annotated findings-including hemorrhage, infarction, trauma, mass lesions, structural abnormalities, and chronic changes-our experiments demonstrate consistent performance improvements across all models. Gains vary substantially: general-purpose and medical-domain models show the largest improvements (DINOv3-Base: +4.6%; MedGemma: +4.3%), whereas 3D CT-specialized or very large models show more modest gains (+0.2-1.3%). The combination of MoLRE and MedGemma achieves the highest average detection AUC of 0.917. These findings highlight the importance of systematic benchmarking on target clinical tasks, as pretraining domain, architecture, and model scale interact in non-obvious ways.
Revisiting 2D Foundation Models for Scalable 3D Medical Image Classification
Dec 15, 2025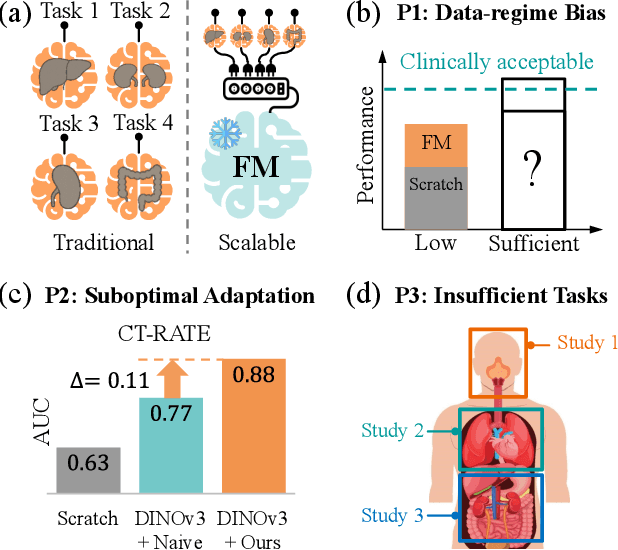
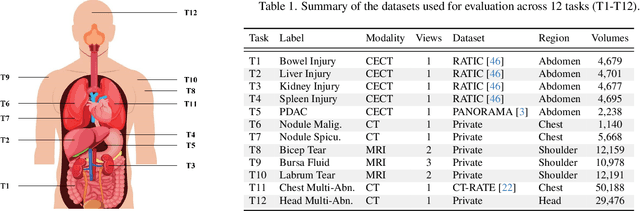
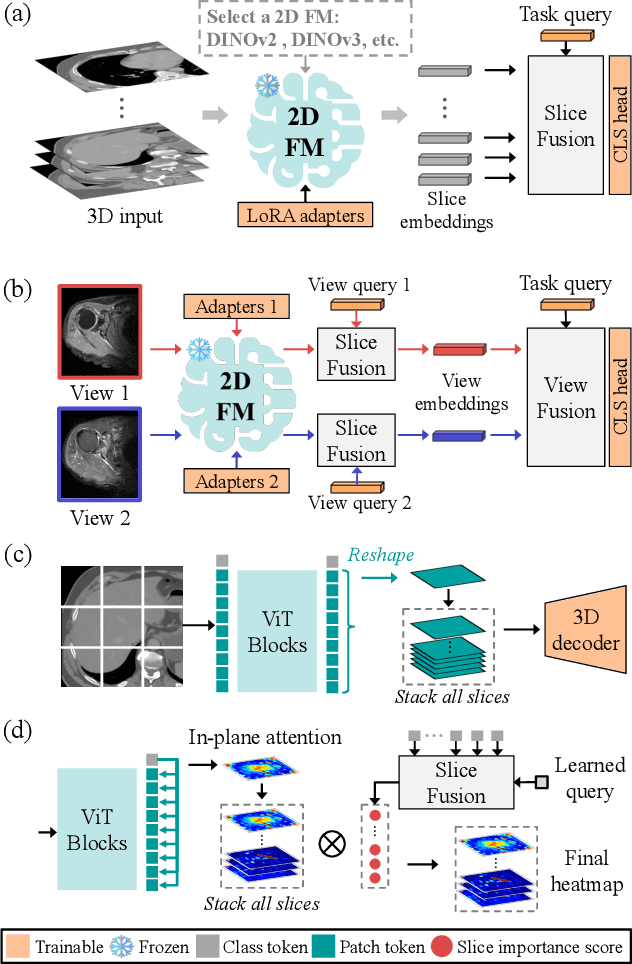
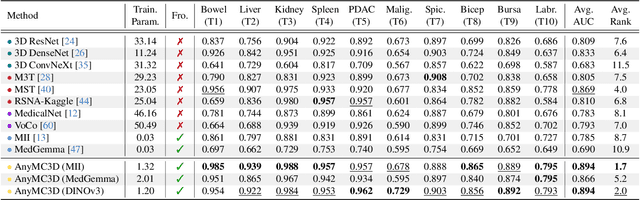
3D medical image classification is essential for modern clinical workflows. Medical foundation models (FMs) have emerged as a promising approach for scaling to new tasks, yet current research suffers from three critical pitfalls: data-regime bias, suboptimal adaptation, and insufficient task coverage. In this paper, we address these pitfalls and introduce AnyMC3D, a scalable 3D classifier adapted from 2D FMs. Our method scales efficiently to new tasks by adding only lightweight plugins (about 1M parameters per task) on top of a single frozen backbone. This versatile framework also supports multi-view inputs, auxiliary pixel-level supervision, and interpretable heatmap generation. We establish a comprehensive benchmark of 12 tasks covering diverse pathologies, anatomies, and modalities, and systematically analyze state-of-the-art 3D classification techniques. Our analysis reveals key insights: (1) effective adaptation is essential to unlock FM potential, (2) general-purpose FMs can match medical-specific FMs if properly adapted, and (3) 2D-based methods surpass 3D architectures for 3D classification. For the first time, we demonstrate the feasibility of achieving state-of-the-art performance across diverse applications using a single scalable framework (including 1st place in the VLM3D challenge), eliminating the need for separate task-specific models.
Advancing the Scientific Method with Large Language Models: From Hypothesis to Discovery
May 22, 2025With recent Nobel Prizes recognising AI contributions to science, Large Language Models (LLMs) are transforming scientific research by enhancing productivity and reshaping the scientific method. LLMs are now involved in experimental design, data analysis, and workflows, particularly in chemistry and biology. However, challenges such as hallucinations and reliability persist. In this contribution, we review how Large Language Models (LLMs) are redefining the scientific method and explore their potential applications across different stages of the scientific cycle, from hypothesis testing to discovery. We conclude that, for LLMs to serve as relevant and effective creative engines and productivity enhancers, their deep integration into all steps of the scientific process should be pursued in collaboration and alignment with human scientific goals, with clear evaluation metrics. The transition to AI-driven science raises ethical questions about creativity, oversight, and responsibility. With careful guidance, LLMs could evolve into creative engines, driving transformative breakthroughs across scientific disciplines responsibly and effectively. However, the scientific community must also decide how much it leaves to LLMs to drive science, even when associations with 'reasoning', mostly currently undeserved, are made in exchange for the potential to explore hypothesis and solution regions that might otherwise remain unexplored by human exploration alone.
* 45 pages
Estimating Quality in Therapeutic Conversations: A Multi-Dimensional Natural Language Processing Framework
May 09, 2025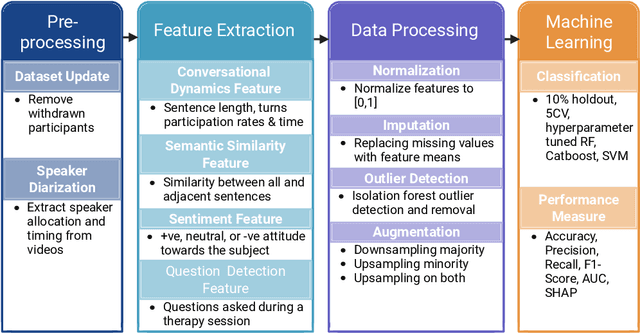
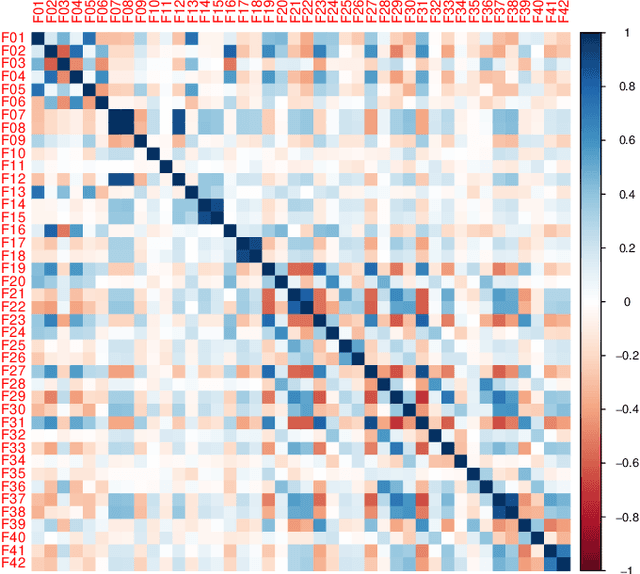
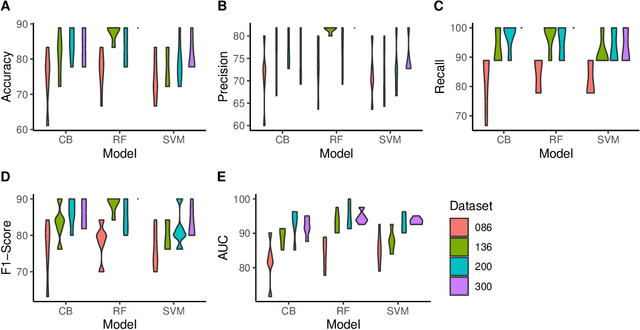
Engagement between client and therapist is a critical determinant of therapeutic success. We propose a multi-dimensional natural language processing (NLP) framework that objectively classifies engagement quality in counseling sessions based on textual transcripts. Using 253 motivational interviewing transcripts (150 high-quality, 103 low-quality), we extracted 42 features across four domains: conversational dynamics, semantic similarity as topic alignment, sentiment classification, and question detection. Classifiers, including Random Forest (RF), Cat-Boost, and Support Vector Machines (SVM), were hyperparameter tuned and trained using a stratified 5-fold cross-validation and evaluated on a holdout test set. On balanced (non-augmented) data, RF achieved the highest classification accuracy (76.7%), and SVM achieved the highest AUC (85.4%). After SMOTE-Tomek augmentation, performance improved significantly: RF achieved up to 88.9% accuracy, 90.0% F1-score, and 94.6% AUC, while SVM reached 81.1% accuracy, 83.1% F1-score, and 93.6% AUC. The augmented data results reflect the potential of the framework in future larger-scale applications. Feature contribution revealed conversational dynamics and semantic similarity between clients and therapists were among the top contributors, led by words uttered by the client (mean and standard deviation). The framework was robust across the original and augmented datasets and demonstrated consistent improvements in F1 scores and recall. While currently text-based, the framework supports future multimodal extensions (e.g., vocal tone, facial affect) for more holistic assessments. This work introduces a scalable, data-driven method for evaluating engagement quality of the therapy session, offering clinicians real-time feedback to enhance the quality of both virtual and in-person therapeutic interactions.
Giving Simulated Cells a Voice: Evolving Prompt-to-Intervention Models for Cellular Control
May 05, 2025



Guiding biological systems toward desired states, such as morphogenetic outcomes, remains a fundamental challenge with far-reaching implications for medicine and synthetic biology. While large language models (LLMs) have enabled natural language as an interface for interpretable control in AI systems, their use as mediators for steering biological or cellular dynamics remains largely unexplored. In this work, we present a functional pipeline that translates natural language prompts into spatial vector fields capable of directing simulated cellular collectives. Our approach combines a large language model with an evolvable neural controller (Prompt-to-Intervention, or P2I), optimized via evolutionary strategies to generate behaviors such as clustering or scattering in a simulated 2D environment. We demonstrate that even with constrained vocabulary and simplified cell models, evolved P2I networks can successfully align cellular dynamics with user-defined goals expressed in plain language. This work offers a complete loop from language input to simulated bioelectric-like intervention to behavioral output, providing a foundation for future systems capable of natural language-driven cellular control.
Understanding LLM Scientific Reasoning through Promptings and Model's Explanation on the Answers
May 02, 2025Large language models (LLMs) have demonstrated remarkable capabilities in natural language understanding, reasoning, and problem-solving across various domains. However, their ability to perform complex, multi-step reasoning task-essential for applications in science, medicine, and law-remains an area of active investigation. This paper examines the reasoning capabilities of contemporary LLMs, analyzing their strengths, limitations, and potential for improvement. The study uses prompt engineering techniques on the Graduate-Level GoogleProof Q&A (GPQA) dataset to assess the scientific reasoning of GPT-4o. Five popular prompt engineering techniques and two tailored promptings were tested: baseline direct answer (zero-shot), chain-of-thought (CoT), zero-shot CoT, self-ask, self-consistency, decomposition, and multipath promptings. Our findings indicate that while LLMs exhibit emergent reasoning abilities, they often rely on pattern recognition rather than true logical inference, leading to inconsistencies in complex problem-solving. The results indicated that self-consistency outperformed the other prompt engineering technique with an accuracy of 52.99%, followed by direct answer (52.23%). Zero-shot CoT (50%) outperformed multipath (48.44%), decomposition (47.77%), self-ask (46.88%), and CoT (43.75%). Self-consistency performed the second worst in explaining the answers. Simple techniques such as direct answer, CoT, and zero-shot CoT have the best scientific reasoning. We propose a research agenda aimed at bridging these gaps by integrating structured reasoning frameworks, hybrid AI approaches, and human-in-the-loop methodologies. By critically evaluating the reasoning mechanisms of LLMs, this paper contributes to the ongoing discourse on the future of artificial general intelligence and the development of more robust, trustworthy AI systems.
A Non-contrast Head CT Foundation Model for Comprehensive Neuro-Trauma Triage
Feb 28, 2025



Recent advancements in AI and medical imaging offer transformative potential in emergency head CT interpretation for reducing assessment times and improving accuracy in the face of an increasing request of such scans and a global shortage in radiologists. This study introduces a 3D foundation model for detecting diverse neuro-trauma findings with high accuracy and efficiency. Using large language models (LLMs) for automatic labeling, we generated comprehensive multi-label annotations for critical conditions. Our approach involved pretraining neural networks for hemorrhage subtype segmentation and brain anatomy parcellation, which were integrated into a pretrained comprehensive neuro-trauma detection network through multimodal fine-tuning. Performance evaluation against expert annotations and comparison with CT-CLIP demonstrated strong triage accuracy across major neuro-trauma findings, such as hemorrhage and midline shift, as well as less frequent critical conditions such as cerebral edema and arterial hyperdensity. The integration of neuro-specific features significantly enhanced diagnostic capabilities, achieving an average AUC of 0.861 for 16 neuro-trauma conditions. This work advances foundation models in medical imaging, serving as a benchmark for future AI-assisted neuro-trauma diagnostics in emergency radiology.
ProAI: Proactive Multi-Agent Conversational AI with Structured Knowledge Base for Psychiatric Diagnosis
Feb 28, 2025Most LLM-driven conversational AI systems operate reactively, responding to user prompts without guiding the interaction. Most LLM-driven conversational AI systems operate reactively, responding to user prompts without guiding the interaction. However, many real-world applications-such as psychiatric diagnosis, consulting, and interviews-require AI to take a proactive role, asking the right questions and steering conversations toward specific objectives. Using mental health differential diagnosis as an application context, we introduce ProAI, a goal-oriented, proactive conversational AI framework. ProAI integrates structured knowledge-guided memory, multi-agent proactive reasoning, and a multi-faceted evaluation strategy, enabling LLMs to engage in clinician-style diagnostic reasoning rather than simple response generation. Through simulated patient interactions, user experience assessment, and professional clinical validation, we demonstrate that ProAI achieves up to 83.3% accuracy in mental disorder differential diagnosis while maintaining professional and empathetic interaction standards. These results highlight the potential for more reliable, adaptive, and goal-driven AI diagnostic assistants, advancing LLMs beyond reactive dialogue systems.